




3.7 Elasticsearch-查询性能剖析:profile API、DFS query_then_fetch
3.7.1 profile API 能看什么、不能看什么
profile API 把一次查询在 Coordinator 节点和每个 Shard 上的执行过程拆成可读的“时间线”与“调用树”,粒度到 Lucene 的 Weight→Scorer→BulkScorer→TwoPhaseIterator。返回 JSON 里包含:
query数组:每个 Shard 的 rewrite、create_weight、build_scorer、next_doc、advance、match 等阶段耗时(单位 ns)collector数组:TopScoreDocCollector、TopDocsCollector 的 reduce 时间、收集文档数、提前结束(early_termination)次数children嵌套:布尔查询的 should/must/filter 子句各自耗时,可一眼定位“慢子句”breakdown明细:底层统计,如set_min_competitive_score调用次数,用于判断是否真的触发了 WAND 优化
不能看的:
- 网络往返、序列化、GC 停顿——这些在 JVM Stas 里,profile 不采集;
- 磁盘读 IO、page cache miss——需要借助 iostat、hot_threads、async profiler;
- fetch 阶段的 _source 解析、字段抽取——profile 只到收集 docID 为止,fetch 另算。
3.7.2 打开 profile 的三种姿势
- Kibana → Inspect → View profile
- DSL 加顶层
"profile": true - 代码(RestHighLevelClient 已废弃,推荐 Java API Client):
SearchRequest req = SearchRequest.of(b -> b
.index("shop")
.query(q -> q.term(t -> t.field("brand").value("sony")))
.profile(true));
SearchResponse<Map> resp = client.search(req, Map.class);
resp.profile().shards().forEach(shard -> {
shard.searches().forEach(s -> s.query().forEach(q -> {
System.out.println(q.type() + " " + q.timeInNanos());
}));
});
3.7.3 一条慢查询的解剖实战
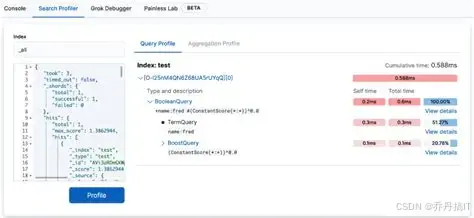
场景:商品索引 1.2 亿 doc,查询“品牌=sony 且 上架时间≥now-7d”,响应 2.3 s。
profile 片段(已换算 ms):
"query": [{
"type": "BooleanQuery",
"time": "1934.2ms",
"breakdown": {
"build_scorer": 1821ms,
"next_doc": 78ms,
"advance": 12ms
},
"children": [
{ "type": "TermQuery@brand", "time": "41ms" },
{ "type": "RangeQuery@onShelfTime", "time": "1890ms" }
]
}]
结论:
- RangeQuery 占 97% 时间,build_scorer 阶段爆炸,说明 Lucene 在倒排链合并时做了巨量 advance;
- 该字段是毫秒级 long 型,每日新增 2000 万值,倒排链极长;
- 优化:把 onShelfTime 改成“天”粒度 + 预热 index.sort,把 Range 变成 Keyword 的 TermsQuery 集合,响应降到 120 ms。
3.7.4 DFS query_then_fetch 原理解剖
Elasticsearch 默认使用“Query Then Fetch”(QTF):
- Query 阶段:每个 Shard 本地算分,只返回 docID+score 的 TopN;
- Fetch 阶段:Coordinator 按 score 排序后去对应 Shard 拉取 _source。
问题:当 Shard 之间 TF-IDF 统计差异大时,局部分数不可比,导致“好文档”被提前截断。典型症状:副本数越多、数据越倾斜,同一查询的 Top10 结果在不同副本上不一致。
DFS query_then_fetch(DFS=Distributed Frequency Search)在 Query 前增加一轮“广播收集”:
- DFS 阶段:各 Shard 把本次查询涉及的所有 Term 的 df、ttf 返回给 Coordinator;
- Coordinator 合并全局统计,生成统一的 Similarity;
- 再走标准 QTF,用全局统计重新算分。
代价:两次 RPC,多一轮序列化;若查询包含大量高基数字段,DFS 报文体可能膨胀到几十 MB,Coordinator 节点网络与内存压力骤增。
3.7.5 DFS 的适用边界
推荐打开的场景:
- 索引总分片数 > 50,且每个分片数据量差异 > 3 倍;
- 使用 BM25、LM Dirichlet 等需要全局 df 的相似度算法;
- 对排序一致性要求极高,如法律、金融搜索,不能容忍副本切换导致结果跳动。
不建议打开:
- 日志、监控类场景,只按时间序 + 简单过滤,不用相关性打分;
- 查询本身带“sort”字段,完全不走 score;
- 单个索引分片 < 10 GB,副本数据量均匀,全局 DF 与局部 DF 差异 < 5%。
3.7.6 在 profile 里识别 DFS 开销
profile 返回根节点新增 dfs 段:
"dfs": {
"time_in_nanos": 842000000,
"statistics": {
"term_count": 3,
"df_fetch_count": 15
}
}
若 DFS 时间占比 > 30% 且 term_count 很小,说明分片之间全局统计差异大,可继续保留 DFS;若 term_count 上千,DFS 时间反而超过 Query 阶段,就应考虑:
- 把高基数字段改成 bool filter,不评分;
- 或者提前用 rollover 把索引按固定维度拆小,降低分片间差异。
3.7.7 小结速查表
- profile 定位“慢子句”→看 build_scorer/advance 时间;
- Range 慢 → 粒度升维、预索引、sort 字段;
- score 不一致 → 看分片大小差异 + 副本切换,再决定 DFS;
- DFS 开销高 → 减 Term 数量或放弃评分;
- 网络/IO 看不到 → 补 hot_threads、iostat、async-profiler。
更多技术文章见公众号: 大城市小农民




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











