



1. Fasttext
1.1 模型架构
Fasttext模型架构和Word2vec的CBOW模型架构非常相似,下面就是FastText模型的架构图:
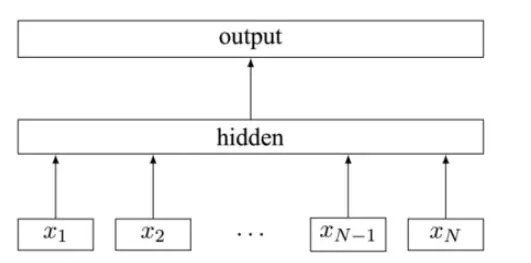
从上图可以看出来,Fasttext模型包括输入层、隐含层、输出层共三层。其中输入的是词向量,输出的是label,隐含层是对多个词向量的叠加平均
- CBOW的输入是目标单词的上下文,
Fasttext的输入是多个单词及其n-gram特征,这些单词用来表示单个文档 - CBOW的输入单词使用one-hot编码,
Fasttext的输入特征时使用embedding编码 - CBOW的输出是目标词汇,
Fasttext的输出是文档对应的类别
1.2 模型实现
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.embedding_ngram2 = nn.Embedding(config.n_gram_vocab, config.embed)
self.embedding_ngram3 = nn.Embedding(config.n_gram_vocab, config.embed)
self.dropout = nn.Dropout(config.dropout)
self.fc1 = nn.Linear(config.embed * 3, config.hidden_size)
# self.dropout2 = nn.Dropout(config.dropout)
self.fc2 = nn.Linear(config.hidden_size, config.num_classes)
def forward(self, x):
out_word = self.embedding(x[0])
out_bigram = self.embedding_ngram2(x[2])
out_trigram = self.embedding_ngram3(x[3])
out = torch.cat((out_word, out_bigram, out_trigram), -1)
out = out.mean(dim=1)
out = self.dropout(out)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
return out
2. TextCNN
2.1 模型架构
与传统图像的CNN网络相比,TextCNN在网络结构上没有任何变化, 从下图可以看出TextCNN其实只有一层convolution,一层max-pooling, 最后将输出外接softmax来n分类

2.2 模型实现
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.convs = nn.ModuleList([nn.Conv2d(1, config.num_filters, (k, config.embed)) for k in config.filter_sizes])
self.dropout = nn.Dropout(config.dropout)
self.fc = nn.Linear(config.num_filters * len(config.filter_sizes), config.num_classes)
def conv_and_pool(self, x, conv):
x = F.relu(conv(x)).squeeze(3)
x = F.max_pool1d(x, x.size(2)).squeeze(2)
return x
def forward(self, x):
out = self.embedding(x[0])
out = out.unsqueeze(1)
out = torch.cat([self.conv_and_pool(out, conv) for conv in self.convs], 1)
out = self.dropout(out)
out = self.fc(out)
return
3. TextRNN
3.1 模型架构
一般取前向/反向LSTM在最后一个时间步长上隐藏状态,然后进行拼接,在经过一个softmax层进行一个多分类;或者取前向/反向LSTM在每一个时间步长上的隐藏状态,对每一个时间步长上的两个隐藏状态进行拼接concat,然后对所有时间步长上拼接后的隐藏状态取均值,再经过一个softmax层进行一个多分类

3.2 模型实现
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers, bidirectional=True, batch_first=True, dropout=config.dropout)
self.fc = nn.Linear(config.hidden_size * 2, config.num_classes)
def forward(self, x):
x, _ = x
out = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]
out, _ = self.lstm(out)
out = self.fc(out[:, -1, :]) # 句子最后时刻的 hidden state
return out
4. TextRCNN
4.1 模型架构
与TextCNN比较类似,都是把文本表示为一个嵌入矩阵,再进行卷积操作。不同的是TextCNN中的文本嵌入矩阵每一行只是文本中一个词的向量表示,而在RCNN中,文本嵌入矩阵的每一行是当前词的词向量以及上下文嵌入表示的拼接
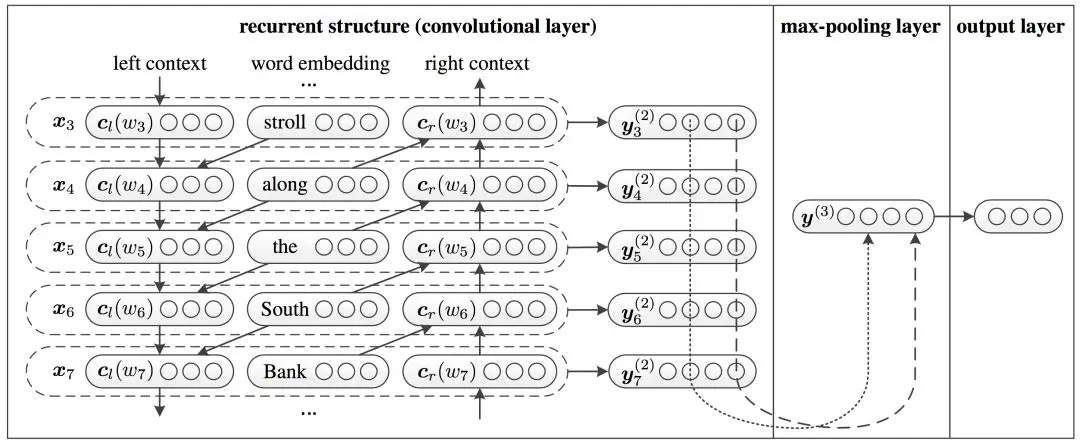
4.2 模型实现
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers, bidirectional=True, batch_first=True, dropout=config.dropout)
self.maxpool = nn.MaxPool1d(config.pad_size)
self.fc = nn.Linear(config.hidden_size * 2 + config.embed, config.num_classes)
def forward(self, x):
x, _ = x
embed = self.embedding(x) # [batch_size, seq_len, embeding]=[64, 32, 64]
out, _ = self.lstm(embed)
out = torch.cat((embed, out), 2)
out = F.relu(out)
out = out.permute(0, 2, 1)
out = self.maxpool(out).squeeze()
out = self.fc(out)
return
5. BiLSTM_Attention
5.1 模型架构
相对于以前的文本分类中的BiLSTM模型,BiLSTM+Attention模型的主要区别是在BiLSTM层之后,全连接softmax分类层之前接入了一个叫做Attention Layer的结构
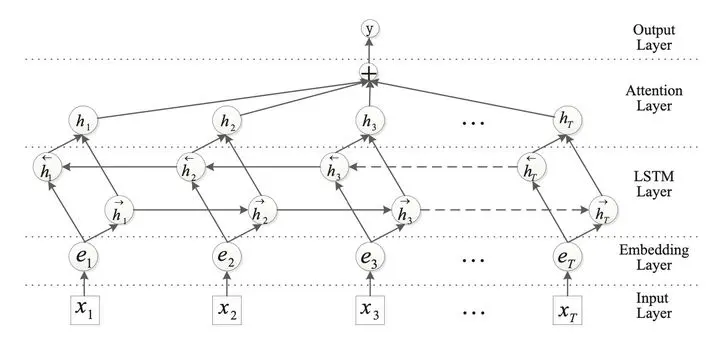
5.2 模型实现
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.lstm = nn.LSTM(config.embed, config.hidden_size, config.num_layers, bidirectional=True, batch_first=True, dropout=config.dropout)
self.tanh1 = nn.Tanh()
self.w = nn.Parameter(torch.zeros(config.hidden_size * 2))
self.tanh2 = nn.Tanh()
self.fc1 = nn.Linear(config.hidden_size * 2, config.hidden_size2)
self.fc = nn.Linear(config.hidden_size2, config.num_classes)
def forward(self, x):
x, _ = x
emb = self.embedding(x) # [batch_size, seq_len, embeding]=[128, 32, 300]
H, _ = self.lstm(emb) # [batch_size, seq_len, hidden_size * num_direction]=[128, 32, 256]
M = self.tanh1(H) # [128, 32, 256]
alpha = F.softmax(torch.matmul(M, self.w), dim=1).unsqueeze(-1) # [128, 32, 1]
out = H * alpha # [128, 32, 256]
out = torch.sum(out, 1) # [128, 256]
out = F.relu(out)
out = self.fc1(out)
out = self.fc(out) # [128, 64]
return out
6. DPCNN
6.1 模型架构
第一层采用text region embedding,其实就是对一个n-gram文本块进行卷积,得到的feature maps作为该文本块的embedding。然后是convolution blocks的堆叠,就是两个卷积层与shortcut的组合。convolution blocks中间采用max-pooling,设置步长为2以进行负采样。最后一个pooling层将每个文档的数据整合成一个向量

6.2 模型实现
class Model(nn.Module):
def __init__(self, config):
super(Model, self).__init__()
self.embedding = nn.Embedding(config.n_vocab, config.embed, padding_idx=config.n_vocab - 1)
self.conv_region = nn.Conv2d(1, config.num_filters, (3, config.embed), stride=1)
self.conv = nn.Conv2d(config.num_filters, config.num_filters, (3, 1), stride=1)
self.max_pool = nn.MaxPool2d(kernel_size=(3, 1), stride=2)
self.padding1 = nn.ZeroPad2d((0, 0, 1, 1)) # top bottom
self.padding2 = nn.ZeroPad2d((0, 0, 0, 1)) # bottom
self.relu = nn.ReLU()
self.fc = nn.Linear(config.num_filters, config.num_classes)
def forward(self, x):
x = x[0]
x = self.embedding(x)
x = x.unsqueeze(1) # [batch_size, 250, seq_len, 1]
x = self.conv_region(x) # [batch_size, 250, seq_len-3+1, 1]
x = self.padding1(x) # [batch_size, 250, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]
x = self.padding1(x) # [batch_size, 250, seq_len, 1]
x = self.relu(x)
x = self.conv(x) # [batch_size, 250, seq_len-3+1, 1]
while x.size()[2] > 2:
x = self._block(x)
x = x.squeeze() # [batch_size, num_filters(250)]
x = self.fc(x)
return x
def _block(self, x):
x = self.padding2(x)
px = self.max_pool(x)
x = self.padding1(px)
x = F.relu(x)
x = self.conv(x)
x = self.padding1(x)
x = F.relu(x)
x = self.conv(x)
x = x + px
return x
NLP新人,欢迎大家一起交流,互相学习,共同成长~~
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 8489
8489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









