



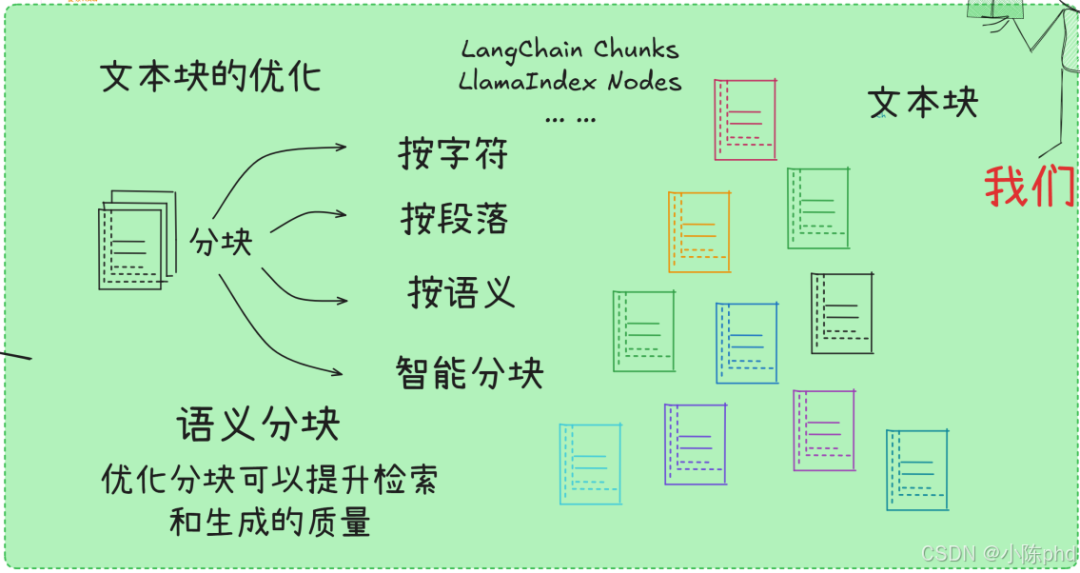
1. 文本分块的原理和重要性
将长文本分解成适当大小的片段,以便于嵌入、索引和存储,并提高检索的精确度。
文本分块(Text Chunking)是 RAG(检索增强生成)、文档问答、向量检索等场景的核心预处理步骤,本质是将长文本拆分为大小合适、语义完整的片段,核心目的是解决「长文本与模型 / 检索系统能力不匹配」的问题,同时提升检索精度、生成质量和系统效率。
1.1 如何确定大模型所能接受的最长上下文
1.查官方文档,获取模型的 理论上下文长度(Token 数);
2.用 Token 计数器生成测试文本,调用模型接口,找到 实际可用上限(排除 API / 显存限制);
from transformers import AutoTokenizer# 加载模型对应的 Tokenizer(如 Llama 3)tokenizer = AutoTokenizer.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")model_max_length = tokenizer.model_max_length # 读取 Tokenizer 标注的最大长度(理论值)print(f"模型理论最大 Token 数:{model_max_length}")# 生成测试文本(逐步增加长度)test_text = "测试文本 " * 1000# 可调整倍数,直到 Token 数接近理论值tokens = tokenizer.encode(test_text, return_tensors="pt")print(f"测试文本 Token 数:{tokens.shape[1]}")# 调用模型(此处仅演示 Token 计数,实际需加载模型)# from transformers import AutoModelForCausalLM# model = AutoModelForCausalLM.from_pretrained("meta-llama/Meta-Llama-3-8B-Instruct")# try:# output = model.generate(tokens, max_new_tokens=100)# print("未超出上下文长度")# except Exception as e:# print(f"超出上下文长度,报错:{e}")
3.预留输出 Token 空间(输入长度 = 实际上限 - 预期输出长度),确保使用时不超限。
1.2 分块大小对检索精度的影响 – 理解嵌入过程
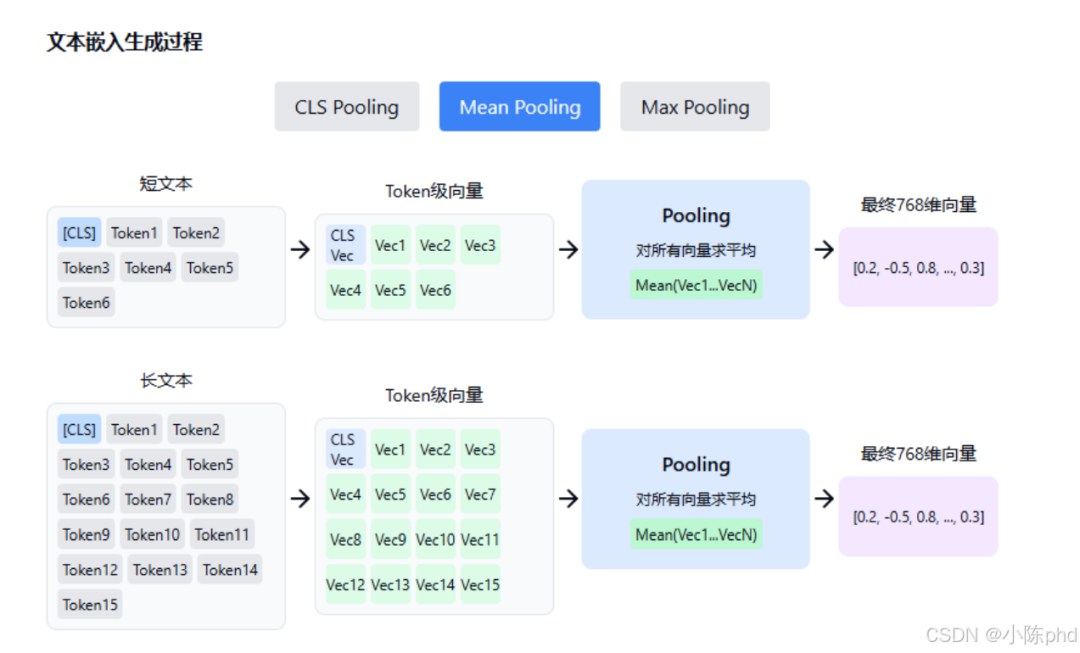
在这里插入图片描述
文本嵌入的核心是用向量捕捉文本的整体语义。图中展示了「短文本」和「长文本」都通过 Mean Pooling(对所有 Token 级向量求平均) 生成最终嵌入:
分块过小时:每个块的语义单元不完整(如把一个完整的论点拆成两段),Token 级向量的聚合结果会丢失关键语义信息。例如,若将 “黑神话悟空的剧情设定很有深度” 拆成 “黑神话悟空的剧情” 和 “设定很有深度” 两个块,各自的嵌入向量会因语义残缺,导致检索时无法准确匹配 “剧情深度” 相关的查询。
分块过大时:块内包含多个无关语义(如一篇文档同时讲 “游戏玩法” 和 “角色设定”),Token 级向量的平均结果会成为 “混合语义”,与查询的相似度被稀释。例如,查询 “黑神话悟空的玩法” 时,包含 “玩法 + 角色” 的大块嵌入可能因角色信息的干扰,比仅包含 “玩法” 的小块嵌入匹配度更低。
最优分块大小需在「语义完整性」和「噪声干扰」之间找到平衡:
对于短文本 / 语义密集型内容(如单段论点、表格数据):分块可略小,确保语义单元完整;
对于长文本 / 多主题内容(如多章节文档、包含冗余说明的报告):分块需适中,既保证每个块聚焦单一主题,又避免语义残缺。
可以基于ChunkViz 对文本分块进行可视化,
ChunkViz 是一款专注于文本分块策略的可视化工具,核心用于帮助用户直观理解和对比不同文本分块方法的效果,从而优化大语言模型(LLM)应用中的文本处理流程。
它的核心功能和价值可总结为以下几点:
多策略可视化:支持多种文本分块策略(如字符分割器、递归字符分割器等),通过不同颜色标记分块边界,直观展示分块结果;
自定义参数调整:可自定义分块大小、重叠程度等参数,快速验证不同配置对分块效果的影响;
生态兼容:与 LangChain、LlamaIndex 等主流 LLM 开发框架深度集成,支持直接导入这些框架的分块策略进行对比;
开源易用:以开源项目形式提供,部署和使用门槛低,适合开发者在构建 RAG(检索增强生成)系统、文档问答等场景中调试分块逻辑。
简单来说,ChunkViz 是文本分块的 “可视化调试器”,能让开发者快速找到最适合业务场景的分块策略,避免因分块不合理导致的检索精度下降或模型理解偏差。
2. 文本分块的方法和实现
2.1 CharacterTextSplitter
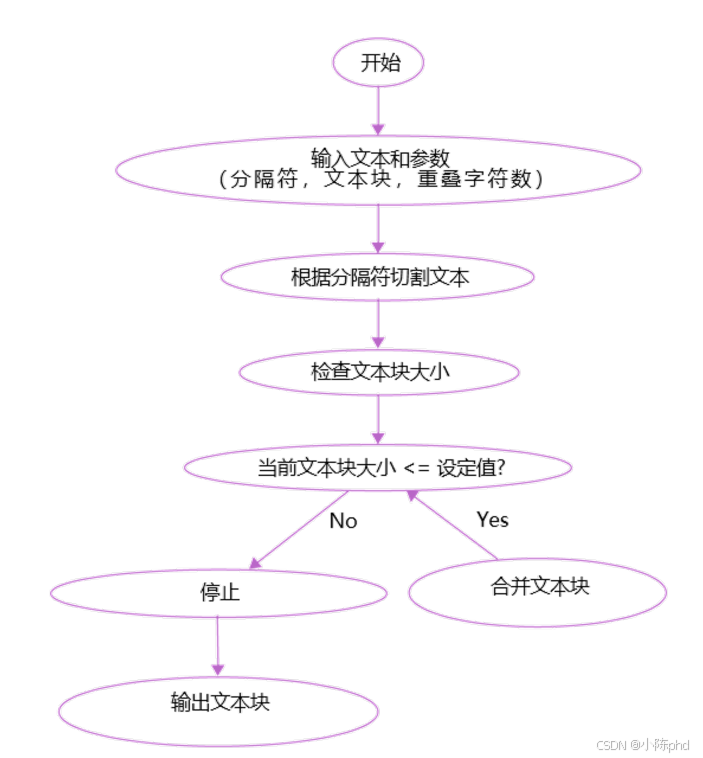
在这里插入图片描述
from langchain_community.document_loaders import TextLoaderfrom langchain_text_splitters import CharacterTextSplitterloader = TextLoader("90-文档-Data/山西文旅/云冈石窟.txt")documents = loader.load()# 设置分块器,指定块的大小为50个字符,无重叠text_splitter = CharacterTextSplitter( chunk_size=100, # 每个文本块的大小为50个字符 chunk_overlap=10, # 文本块之间没有重叠部分)chunks = text_splitter.split_documents(documents)print("\n=== 文档分块结果 ===")for i, chunk inenumerate(chunks, 1): print(f"\n--- 第 {i} 个文档块 ---") print(f"内容: {chunk.page_content}") print(f"元数据: {chunk.metadata}") print("-" * 50)
```核心参数详解(之前提到的关键配置,这里结合代码落地):
`chunk_size=100`:每个分块的最大字符数(注意:是 “字符” 不是 “Token”,中文、英文、标点都算 1 个字符);比如 “云冈石窟位于山西大同” 是 12 个字符;
若文本片段超过 100 字符,会被截断;若未超过,则保留完整片段;
`chunk_overlap=10`:相邻两个分块的重叠部分字符数(不是 “无重叠”,代码注释有误!chunk\_overlap=0 才是无重叠);
作用:避免因硬截断丢失上下文(如第 1 块结尾是 “云冈石窟的佛像”,第 2 块开头重叠 10 字符,确保语义连贯);

### 2.2 RecursiveCharacterTextSplitter 递归分块

在这里插入图片描述
先搞懂:递归分块的核心原理(为什么叫 “递归”?)
`RecursiveCharacterTextSplitter`的核心是`“按优先级分割符递归尝试,优先保持语义完整,实在不行再硬截断”`,流程像 “剥洋葱” 一样层层递进:
1递归分块的 4 步逻辑(以代码中的 separators = ["\n\n", ".", ",", " "] 为例):
1. 1. 第一步:按最高优先级分割符拆分先用第一个分割符 \n\n(双换行,通常是段落分隔)把整个文档拆成多个大段落。此时检查每个段落的字符数:
* • 若段落 ≤ chunk\_size(100 字符):直接作为一个分块;
* • 若段落 > chunk\_size:进入下一步,对这个 “超长段落” 递归拆分。
1. 2. 第二步:按次高优先级分割符拆分对超长段落,用第二个分割符 .(句号,句子结束)拆分,得到多个句子。再检查每个句子的字符数:
* • 若句子 ≤ chunk\_size:合并相邻句子(直到接近 chunk\_size)作为分块;
* • 若句子 > chunk\_size:进入下一步,继续递归拆分。
1. 3. 第三步:按更低优先级分割符拆分对超长句子,用第三个分割符 ,(逗号,分句)拆分,得到多个分句。重复检查字符数:
* • 若分句 ≤ chunk\_size:合并相邻分句作为分块;
* • 若分句 > chunk\_size:进入最后一步。
1. 4. 第四步:终极方案(硬截断)用最后一个分割符 (空格,单词 / 词组分隔)拆分,若仍超长(如连续无空格的长文本),则直接按 chunk\_size 硬截断(这是最后的妥协,尽量避免破坏语义)。
核心优势:
优先按「段落→句子→分句→单词」的逻辑拆分,最大程度保持语义完整(不会轻易在句子中间截断);
递归机制适配各种文本结构(如长段落、短句子、无标点文本),通用性比普通 CharacterTextSplitter 强得多。
```plaintext
from langchain_community.document_loaders import TextLoaderfrom langchain_text_splitters import RecursiveCharacterTextSplitterloader = TextLoader("90-文档-Data/山西文旅/云冈石窟.txt")documents = loader.load()# 定义分割符列表,按优先级依次使用separators = ["\n\n", ".", ",", " "] # . 是句号,, 是逗号, 是空格# 创建递归分块器,并传入分割符列表text_splitter = RecursiveCharacterTextSplitter( chunk_size=100, chunk_overlap=10, separators=separators)chunks = text_splitter.split_documents(documents)print("\n=== 文档分块结果 ===")for i, chunk in enumerate(chunks, 1): print(f"\n--- 第 {i} 个文档块 ---") print(f"内容: {chunk.page_content}") print(f"元数据: {chunk.metadata}") print("-" * 50)
2.3 代码分块
- 普通递归分块
from langchain_text_splitters import RecursiveCharacterTextSplitter# 示例代码GAME_CODE = """class CombatSystem: def __init__(self): self.health = 100 self.stamina = 100 self.state = "IDLE" self.attack_patterns = { "NORMAL": 10, "SPECIAL": 30, "ULTIMATE": 50 } def update(self, delta_time): self._update_stats(delta_time) self._handle_combat() def _update_stats(self, delta_time): self.stamina = min(100, self.stamina + 5 * delta_time) def _handle_combat(self): if self.state == "ATTACKING": self._execute_attack() def _execute_attack(self): if self.stamina >= self.attack_patterns["SPECIAL"]: damage = 50 self.stamina -= self.attack_patterns["SPECIAL"] return damage return self.attack_patterns["NORMAL"]class InventorySystem: def __init__(self): self.items = {} self.capacity = 20 self.gold = 0 def add_item(self, item_id, quantity): if len(self.items) < self.capacity: if item_id in self.items: self.items[item_id] += quantity else: self.items[item_id] = quantity def remove_item(self, item_id, quantity): if item_id in self.items: self.items[item_id] -= quantity if self.items[item_id] <= 0: del self.items[item_id] def get_item_count(self, item_id): return self.items.get(item_id, 0)class QuestSystem: def __init__(self): self.active_quests = {} self.completed_quests = set() self.quest_log = [] def add_quest(self, quest_id, quest_data): if quest_id not in self.active_quests: self.active_quests[quest_id] = quest_data self.quest_log.append(f"Started quest: {quest_data['name']}") def complete_quest(self, quest_id): if quest_id in self.active_quests: self.completed_quests.add(quest_id) del self.active_quests[quest_id] def get_active_quests(self): return list(self.active_quests.keys())"""# 创建文本分割器text_splitter = RecursiveCharacterTextSplitter( chunk_size=1000, # 每个块的大小 chunk_overlap=00, # 相邻块之间的重叠大小 # separators=["\n\n", "\n", " ", ""] # 分割符列表)# 执行分块text_chunks = text_splitter.create_documents([GAME_CODE])# 打印分块结果print("\n=== 代码分块结果 ===")for i, chunk inenumerate(text_chunks, 1): print(f"\n--- 第 {i} 个代码块 ---") print(f"内容:\n{chunk.page_content}") print(f"元数据: {chunk.metadata}") print("-" * 50)
用通用递归分块器,靠默认分割符和字符长度限制,实现代码的 “无断裂拆分”;
分块结果与 3 个游戏系统类一一对应,每个块都能独立运行 / 理解,适配后续代码检索、问答等场景;
可以启用 Python 专属分割符,能应对更复杂的代码结构(如超长函数、无空行类)如下:
按照编程语言来进行划分
from langchain_text_splitters import RecursiveCharacterTextSplitterfrom langchain_text_splitters import Languageseparators = RecursiveCharacterTextSplitter.get_separators_for_language(Language.JS)print(separators)from langchain_text_splitters import ( Language, RecursiveCharacterTextSplitter,)GAME_CODE = """class CombatSystem: def __init__(self): self.health = 100 self.stamina = 100 self.state = "IDLE" self.attack_patterns = { "NORMAL": 10, "SPECIAL": 30, "ULTIMATE": 50 } def update(self, delta_time): self._update_stats(delta_time) self._handle_combat() def _update_stats(self, delta_time): self.stamina = min(100, self.stamina + 5 * delta_time) def _handle_combat(self): if self.state == "ATTACKING": self._execute_attack() def _execute_attack(self): if self.stamina >= self.attack_patterns["SPECIAL"]: damage = 50 self.stamina -= self.attack_patterns["SPECIAL"] return damage return self.attack_patterns["NORMAL"]class InventorySystem: def __init__(self): self.items = {} self.capacity = 20 self.gold = 0 def add_item(self, item_id, quantity): if len(self.items) < self.capacity: if item_id in self.items: self.items[item_id] += quantity else: self.items[item_id] = quantity def remove_item(self, item_id, quantity): if item_id in self.items: self.items[item_id] -= quantity if self.items[item_id] <= 0: del self.items[item_id] def get_item_count(self, item_id): return self.items.get(item_id, 0)class QuestSystem: def __init__(self): self.active_quests = {} self.completed_quests = set() self.quest_log = [] def add_quest(self, quest_id, quest_data): if quest_id not in self.active_quests: self.active_quests[quest_id] = quest_data self.quest_log.append(f"Started quest: {quest_data['name']}") def complete_quest(self, quest_id): if quest_id in self.active_quests: self.completed_quests.add(quest_id) del self.active_quests[quest_id] def get_active_quests(self): return list(self.active_quests.keys())"""python_splitter = RecursiveCharacterTextSplitter.from_language( language=Language.PYTHON, # 指定编程语言为Python chunk_size=1000, chunk_overlap=0)python_docs = python_splitter.create_documents([GAME_CODE])print("\n=== 代码分块结果 ===")for i, chunk inenumerate(python_docs, 1): print(f"\n--- 第 {i} 个代码块 ---") print(f"内容:\n{chunk.page_content}") print(f"元数据: {chunk.metadata}") print("-" * 50)
from_language()方法会自动加载 Python 语言的「语法分割符」(预设的,无需手动定义),比如:
高优先级:“\n\n”(代码空行)、“}”(类 / 函数结束符)、“;”(语句结束符)、“\n”(换行);
低优先级:" “(空格)、”"(硬截断,尽量不用);
分块逻辑:按 Python 语法规则递归拆分,优先保证「类、函数、代码块的语法完整性」(比如不会把一个 class 拆成两半,不会在函数中间截断)。
2.4 语义分块
from llama_index.core import SimpleDirectoryReaderfrom llama_index.core.node_parser import ( SentenceSplitter, SemanticSplitterNodeParser,)from llama_index.embeddings.openai import OpenAIEmbedding # from llama_index.embeddings.huggingface import HuggingFaceEmbedding # embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-small-zh")documents = SimpleDirectoryReader(input_files=["../90-文档-Data/黑悟空/黑悟空wiki.txt"]).load_data()# 创建语义分块器splitter = SemanticSplitterNodeParser( buffer_size=3, # 缓冲区大小 breakpoint_percentile_threshold=90, # 断点百分位阈值 embed_model=OpenAIEmbedding() # 使用的嵌入模型)# 创建基础句子分块器(作为对照)base_splitter = SentenceSplitter( # chunk_size=512)'''buffer_size:默认值为1这个参数控制评估语义相似度时,将多少个句子组合在一起当设置为1时,每个句子会被单独考虑当设置大于1时,会将多个句子组合在一起进行评估例如,如果设置为3,就会将每3个句子作为一个组来评估语义相似度breakpoint_percentile_threshold:默认值为95这个参数控制何时在句子组之间创建分割点,它表示余弦不相似度的百分位数阈值,当句子组之间的不相似度超过这个阈值时,就会创建一个新的节点数值越小,生成的节点就越多(因为更容易达到分割阈值)数值越大,生成的节点就越少(因为需要更大的不相似度才会分割)这两个参数共同影响文本的分割效果:buffer_size 决定了评估语义相似度的粒度breakpoint_percentile_threshold 决定了分割的严格程度例如:如果 buffer_size=2 且 breakpoint_percentile_threshold=90:每2个句子会被组合在一起,当组合之间的不相似度超过90%时就会分割,这会产生相对较多的节点如果 buffer_size=3 且 breakpoint_percentile_threshold=98:每3个句子会被组合在一起,需要更大的不相似度才会分割,这会产生相对较少的节点'''# 使用语义分块器对文档进行分块semantic_nodes = splitter.get_nodes_from_documents(documents)print("\n=== 语义分块结果 ===")print(f"语义分块器生成的块数:{len(semantic_nodes)}")for i, node inenumerate(semantic_nodes, 1): print(f"\n--- 第 {i} 个语义块 ---") print(f"内容:\n{node.text}") print("-" * 50)# 使用基础句子分块器对文档进行分块base_nodes = base_splitter.get_nodes_from_documents(documents)print("\n=== 基础句子分块结果 ===")print(f"基础句子分块器生成的块数:{len(base_nodes)}")for i, node inenumerate(base_nodes, 1): print(f"\n--- 第 {i} 个句子块 ---") print(f"内容:\n{node.text}") print("-" * 50)
2.5 Unstructured 工具
2.5.1 分块策略的原理:基于文档结构的智能拆分
Unstructured 的分块不是简单的“字符截断”,而是先识别文档的语义结构(标题、段落、表格等),再按策略聚合或拆分,确保分块“语义完整、主题聚焦”。图中 4 种分块策略的核心逻辑如下:
| 分块策略 | 原理核心 | 适用场景 | ||
| Basic | 按“预设字符大小”聚合文本元素,表格作为独立分块;若元素超长,对元素二次拆分 | 通用文档,需平衡分块大小与语义 | ||
| By Title | 检测到新标题时,立即关闭当前分块并开启新块,确保“标题+下属内容”语义完整 | 章节化文档(论文、报告、手册) | ||
| By Page | 强制按 PDF 页码拆分,每页内容作为独立分块 | 需保留“页面边界”的场景(合同、法律文书) | ||
| 用嵌入模型计算文本元素的语义相似度,将主题相似的元素聚合成块 | 跨位置的主题聚合(如多处讨论同一概念的文档) |
| 参数名 | 作用 | 示例值 ||-----------------------|----------------------------------------------------------------------|-----------------|| `chunking_strategy` | 指定分块策略(`"basic"`/`"by_title"`/`"by_page"`/`"by_similarity"`)| `"by_title"` || `max_characters` | 分块的最大字符数(Basic 策略的硬限制)| `500` || `new_after_n_chars` | 分块的“软限制”(超过该字符数则停止聚合新元素)| `400` || `embed_model` | By Similarity 策略的嵌入模型(如 OpenAI、HuggingFace 模型)| `OpenAIEmbedding()` || `breakpoint_threshold` | By Similarity 策略的相似度阈值(值越高,分块越少)| `0.7` |#### 2.5.2 案例实例1. Basic 策略(按字符大小分块,表格独立)```pythonfrom unstructured.partition.pdf import partition_pdf# 读取PDF并按Basic策略分块elements = partition_pdf( filename="黑悟空wiki.pdf", chunking_strategy="basic", # 启用Basic分块 max_characters=500, # 每个分块最多500字符 new_after_n_chars=400 # 软限制400字符)# 打印分块结果for i, el in enumerate(elements, 1): print(f"--- 第 {i} 个分块 ---") print(f"类型: {el.category}") print(f"内容: {el.text[:100]}...\n")
- By Title 策略(按标题拆分,确保章节完整)
from unstructured.partition.pdf import partition_pdffrom unstructured.chunking.title import chunk_by_title# 先分区(识别文档元素)elements = partition_pdf(filename="黑悟空wiki.pdf", strategy="hi_res")# 按标题分块chunks = chunk_by_title( elements, combine_text_under_n_chars=200, # 合并短文本 multipage_sections=True # 跨页章节合并)# 打印分块结果for i, chunk inenumerate(chunks, 1): print(f"--- 第 {i} 个分块(标题驱动)---") print(f"内容: {chunk.text[:100]}...\n")
- By Page 策略(按页码强制拆分)
from unstructured.partition.pdf import partition_pdf# 按页码分块(每页一个分块)elements = partition_pdf( filename="黑悟空wiki.pdf", chunking_strategy="by_page")# 打印分块结果(按页码区分)for el in elements: print(f"--- 第 {el.metadata.page_number} 页分块 ---") print(f"内容: {el.text[:100]}...\n")
- By Similarity 策略(语义相似性聚合)
from unstructured.partition.pdf import partition_pdffrom unstructured.chunking.similarity import chunk_by_similarityfrom unstructured.embeddings.openai import OpenAIEmbedding# 先分区elements = partition_pdf(filename="黑悟空wiki.pdf")# 按语义相似性分块chunks = chunk_by_similarity( elements, embed_model=OpenAIEmbedding(), # 用OpenAI嵌入模型计算相似度 breakpoint_threshold=0.7 # 相似度阈值(值越高,分块越少))# 打印分块结果for i, chunk inenumerate(chunks, 1): print(f"--- 第 {i} 个语义分块 ---") print(f"内容: {chunk.text[:100]}...\n")
Unstructured 支持“Partition 时直接 Chunk”和“先 Partition 再 Chunk”两种流程,区别如下:
| 流程类型 | 说明 | 适用场景 | ||
| Partition 时直接 Chunk | 分区和分块一步完成(如示例 1、3),代码更简洁 | 快速验证分块效果,场景简单 | ||
| 先识别文档元素(标题、段落、表格),再针对性分块(如示例 2、4) | 需精细化控制分块逻辑,场景复杂 |
Unstructured 的分块能力核心是**“先理解文档结构,再智能拆分”**——通过 4 种分块策略(Basic、By Title、By Page、By Similarity),适配不同类型的 PDF 文档。代码实现上,只需通过 partition_pdf 函数或专用分块函数(chunk_by_title 等),结合参数配置即可完成分块。
选择策略时,可参考:
通用文档 → Basic;
章节化文档 → By Title;
需保留页码 → By Page;
跨位置主题聚合 → By Similarity。
这种“结构感知”的分块方式,能大幅提升后续 RAG 检索或大模型问答的精准度,是处理非结构化 PDF 文档的高效工具。
3. 与分块相关的高级索引技巧
3.1 带滑动窗口的句子切分(Sliding Windows)
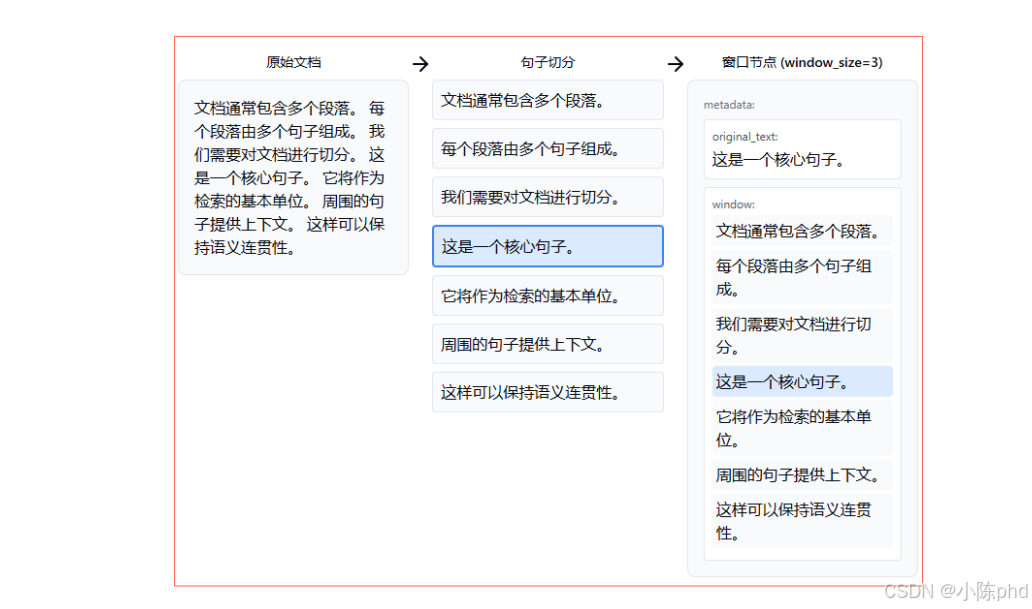
在这里插入图片描述
3.2 分块时混合生成父子文本块(Parent-Child Docs)

在这里插入图片描述
3.3 分块时为文本块创建元数据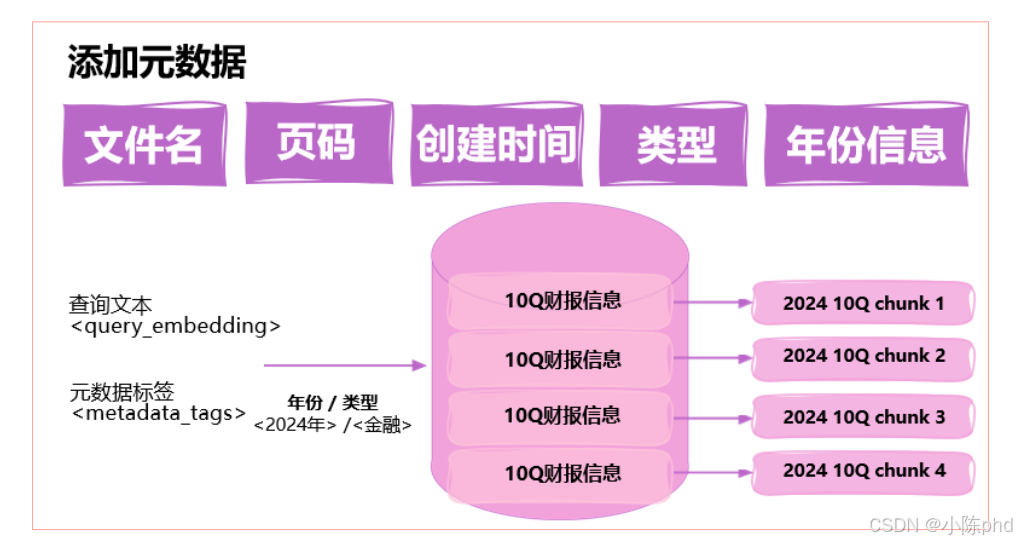
在这里插入图片描述
3.4 在分块时形成有级别的索引(Summary→Details )
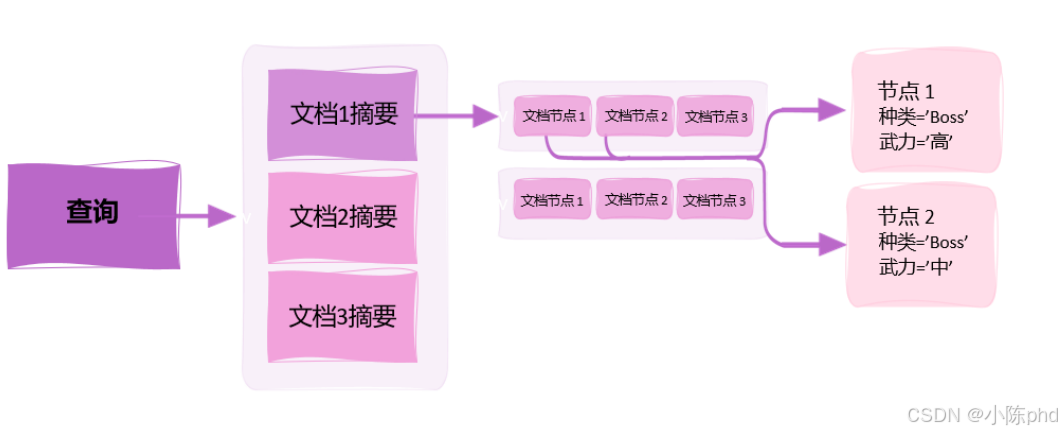
在这里插入图片描述
3.5 文档转换为嵌入对象
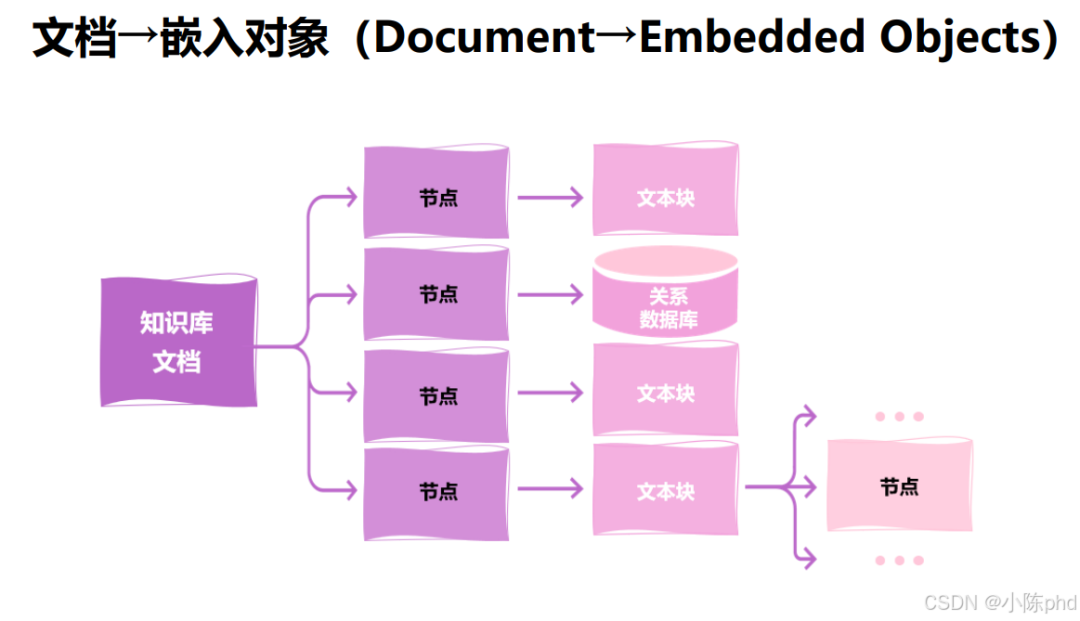
如何高效转型Al大模型领域?
作为一名在一线互联网行业奋斗多年的老兵,我深知持续学习和进步的重要性,尤其是在复杂且深入的Al大模型开发领域。为什么精准学习如此关键?
系统的技术路线图:帮助你从入门到精通,明确所需掌握的知识点。
高效有序的学习路径:避免无效学习,节省时间,提升效率。
完整的知识体系:建立系统的知识框架,为职业发展打下坚实基础。
AI大模型从业者的核心竞争力
持续学习能力:Al技术日新月异,保持学习是关键。
跨领域思维:Al大模型需要结合业务场景,具备跨领域思考能力的从业者更受欢迎。
解决问题的能力:AI大模型的应用需要解决实际问题,你的编程经验将大放异彩。
以前总有人问我说:老师能不能帮我预测预测将来的风口在哪里?
现在没什么可说了,一定是Al;我们国家已经提出来:算力即国力!
未来已来,大模型在未来必然走向人类的生活中,无论你是前端,后端还是数据分析,都可以在这个领域上来,我还是那句话,在大语言AI模型时代,只要你有想法,你就有结果!只要你愿意去学习,你就能卷动的过别人!
现在,你需要的只是一份清晰的转型计划和一群志同道合的伙伴。作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。
第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
大模型 AI 能干什么?
大模型是怎样获得「智能」的?
用好 AI 的核心心法
大模型应用业务架构
大模型应用技术架构
代码示例:向 GPT-3.5 灌入新知识
提示工程的意义和核心思想
Prompt 典型构成
指令调优方法论
思维链和思维树
Prompt 攻击和防范
…
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
为什么要做 RAG
搭建一个简单的 ChatPDF
检索的基础概念
什么是向量表示(Embeddings)
向量数据库与向量检索
基于向量检索的 RAG
搭建 RAG 系统的扩展知识
混合检索与 RAG-Fusion 简介
向量模型本地部署
…
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
为什么要做 RAG
什么是模型
什么是模型训练
求解器 & 损失函数简介
小实验2:手写一个简单的神经网络并训练它
什么是训练/预训练/微调/轻量化微调
Transformer结构简介
轻量化微调
实验数据集的构建
…
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
硬件选型
带你了解全球大模型
使用国产大模型服务
搭建 OpenAI 代理
热身:基于阿里云 PAI 部署 Stable Diffusion
在本地计算机运行大模型
大模型的私有化部署
基于 vLLM 部署大模型
案例:如何优雅地在阿里云私有部署开源大模型
部署一套开源 LLM 项目
内容安全
互联网信息服务算法备案
…
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取。

















 2041
2041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









