



从技术实现角度看,这个功能的核心在于在 saveg()函数中将 goroutine 的 ID 和起始 PC 信息复制到 StackRecord 中。但正如提案作者所说,这样做会让 StackRecord 变得不够通用。
今天给大家分享一个挺有意思的 Go 提案,是关于在runtime.GoroutineProfile中新增暴露goid和gopc字段。
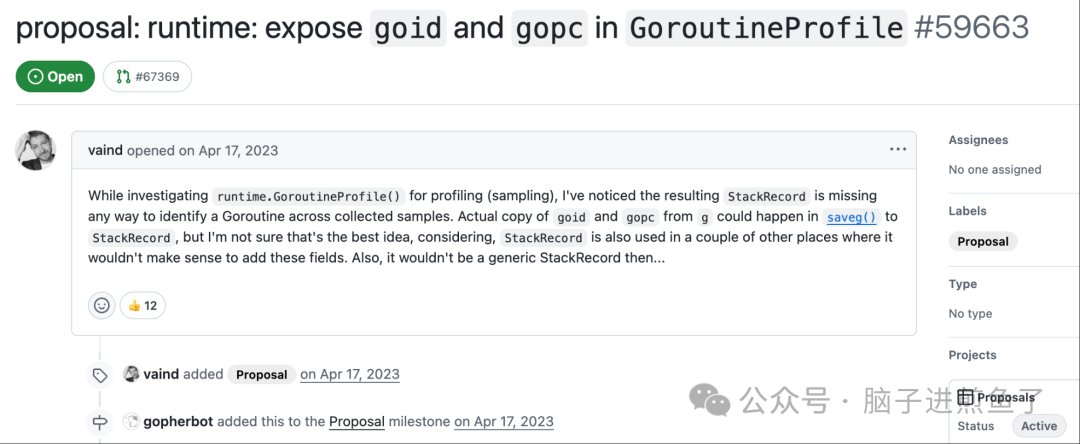
乍一眼一看。可能有些同学会疑惑,这两个字段是干嘛的,为啥要暴露它们?
这背后涉及到 Go 运行时性能分析的一个老大难 “诉求”。
背景
先来说说需求的上下文背景。主要诉求是:在 Go 的性能分析场景中,我们经常需要追踪 Goroutine 的执行情况。
目前主流的做法有两种:
- 第一种:使用
runtime.GoroutineProfile()函数,它能返回当前所有 Goroutine 的堆栈信息。但很无奈的是,返回的StackRecord结构体中没有包含任何能够跨采样周期识别同一个 Goroutine 的标识符。 - 第二种:调用
runtime.Stack(..., true)来获取所有 Goroutine 的堆栈跟踪,但这个方法 CPU 开销相当大,在 Goroutine 数量多的时候基本不可用。
如果使用分析工具想要追踪特定 Goroutine 在多个时间点的行为变化。
是没有合适的标识符来关联这些数据的。这很尴尬了。
例子
让我们看个具体例子来理解这个问题:
package main
import (
"fmt"
"runtime"
"time"
)
func worker(id int) {
for {
// 模拟一些工作
time.Sleep(time.Millisecond * 100)
fmt.Printf("Worker %d is running\n", id)
}
}
func main() {
// 启动几个worker goroutine
for i := 0; i < 3; i++ {
go worker(i)
}
// 定期采集goroutine profile
ticker := time.NewTicker(time.Second)
defer ticker.Stop()
for i := 0; i < 3; i++ {
<-ticker.C
// 获取当前的goroutine profile
profiles := make([]runtime.StackRecord, 10)
n, ok := runtime.GoroutineProfile(profiles)
if !ok {
profiles = make([]runtime.StackRecord, n)
n, _ = runtime.GoroutineProfile(profiles)
}
fmt.Printf("=== Sample %d ===\n", i+1)
for j, profile := range profiles[:n] {
fmt.Printf("Goroutine %d: %d stack frames\n", j, len(profile.Stack0))
// 问题:无法知道这个goroutine的ID,无法跨采样关联
}
}
}
运行这段代码,你会发现每次能采样得到的StackRecord数组,是无法确定哪个记录对应的是同一个 Goroutine,无法知道明确的 GoroutineID。
这对于性能分析来说是个致命问题。因为压根关联不上。谁来了都没办法。只能另外想办法关联上了。
提案内容
这个提案最初由 Sentry 团队的工程师提出,他们在开发 Go SDK 的性能分析功能时遇到了这个困扰。
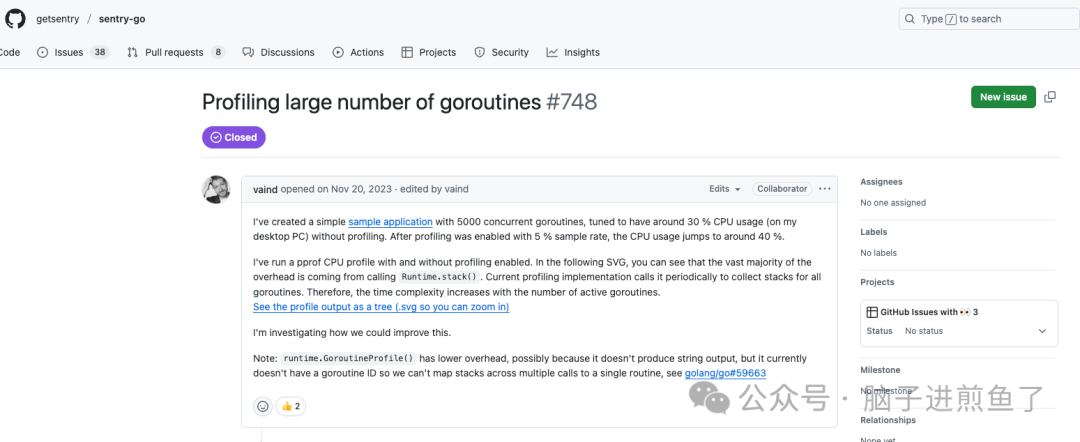
简单来说,他们希望在StackRecord中添加两个字段:
goid:Goroutine 的唯一标识符gopc:Goroutine 的起始程序计数器
但直接在现有的StackRecord结构体中添加字段也不太合适,因为StackRecord在其他地方也有使用,贸然添加字段会影响其他方面的兼容性。
可能的解决方案:
新增一个专门用于 Goroutine 分析的结构体去记录:
// 假设的新结构体
type GoroutineRecord struct {
ID int64 // goroutine ID
GoPC uintptr // goroutine起始PC
Stack []uintptr // 调用栈
// 其他相关字段
}
// 对应的新API
func GoroutineProfileWithID() []GoroutineRecord {
// 实现细节...
}
这样就能在采样时获取到 Goroutine 的身份信息了:
func trackGoroutines() {
// 第一次采样
sample1 := runtime.GoroutineProfileWithID()
time.Sleep(time.Second)
// 第二次采样
sample2 := runtime.GoroutineProfileWithID()
// 现在可以通过ID关联同一个goroutine了
for _, g1 := range sample1 {
for _, g2 := range sample2 {
if g1.ID == g2.ID {
fmt.Printf("Goroutine %d 在两次采样中都存在\n", g1.ID)
// 可以分析这个goroutine的行为变化
}
}
}
}
社区讨论
这个提案在 Go 社区引起了不少关注。Go 核心团队的成员@cherrymui 指出,如果要实现这个功能,可能还需要考虑在 pprof 格式的 goroutine profile 中也添加类似的支持。
从技术实现角度看,这个功能的核心在于在 saveg()函数中将 goroutine 的 ID 和起始 PC 信息复制到 StackRecord 中。但正如提案作者所说,这样做会让 StackRecord 变得不够通用。
我个人觉得,这个提案解决的是一个实际存在的痛点。目前很多性能分析工具都受限于无法追踪特定 Goroutine 的生命周期,这大大降低了分析的精度。
Sentry 团队甚至因为这个问题移除了他们 SDK 中的运行时性能分析功能。
实际影响
让我们来看看这个功能对实际开发的价值。
假设我们有一个 Web 服务,想要分析某些慢请求的根因:
// 当前的困境:无法跟踪特定请求的goroutine
func analyzeSlowRequests() {
// 采样1:请求刚开始
profiles1 := getGoroutineProfile()
// 等待一段时间
time.Sleep(5 * time.Second)
// 采样2:请求可能仍在处理
profiles2 := getGoroutineProfile()
// 问题:无法确定哪个goroutine处理的是同一个请求
// 只能看到所有goroutine的快照,但无法关联
}
// 有了新功能后的可能性
func analyzeSlowRequestsWithID() {
profiles1 := getGoroutineProfileWithID()
time.Sleep(5 * time.Second)
profiles2 := getGoroutineProfileWithID()
// 可以精确跟踪特定goroutine的执行轨迹
for _, g1 := range profiles1 {
for _, g2 := range profiles2 {
if g1.ID == g2.ID {
// 分析同一个goroutine在不同时间点的栈信息
// 找出性能瓶颈所在
}
}
}
}
这种能力对于诊断复杂的性能问题非常有价值,特别是在微服务架构中,一个请求可能会创建多个 goroutine 来处理不同的子任务。
总结
这个提案虽然看起来只是在现有 API 中添加两个字段,但解决的是 Go 运行时性能分析的一个基础能力缺失。
从提案的讨论情况来看,已经进入了 active 状态:
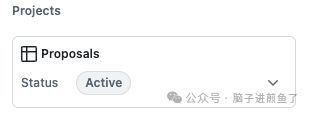
这说明 Go 核心团队正在认真考虑。
我觉得这个功能的落地只是时间问题,毕竟它解决的是一个广泛存在的实际需求。对于那些依赖精确性能分析的工具和服务来说,这将是一个重要的改进。
后续就看 Go 核心团队最终会选择什么样的实现方案了。是直接扩展现有的 API,还是新增专门的 API,都挺值得期待的。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 960
960

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









