 重复采样解锁大模型推理新潜能
重复采样解锁大模型推理新潜能




本篇是一篇复习之作,重复采样的方法,现在已经每天都可见到了。

大家好,我是肆〇柒。如果看我文章的朋友,可能看到过前些天发的这样一篇文章《LLM 推理新境界:多语言思考的力量》。这篇文章就提到过与重复(Repeat)采样的性能对比。当时发出这篇文章以后,我在社区和小伙伴探讨过一些问题,所以引出了今天这篇重复采样的内容。这篇论文《Large Language Monkeys: Scaling Inference Compute with Repeated Sampling》,我曾在去年读到过,并且在具体的项目中落地过这个重复采样的方法。因为讨论时被重新提起,所以复习一下,下面我们就一起看看这个可以让模型性能提升的方法。
研究背景
大型语言模型在解决编程、数学以及各种复杂推理任务方面的能力提升简直可以用 “飞速” 来形容。这一切的背后,离不开训练时对计算资源的大量投入。研究人员们发现,通过扩大模型规模、延长预训练时间以及采用更庞大的数据集进行训练,模型的性能就像被施了魔法一样,不断地取得突破。无论是处理自然语言理解任务,还是生成复杂的文本内容,亦或是解决数学和编程难题,模型都展现出了惊人的进步。
然而,在推理阶段,情况却有些不尽如人意。与训练阶段的繁荣景象形成鲜明对比的是,对于如何合理利用推理阶段的计算资源,相关研究却相对较少。在实际应用中,模型往往只能老老实实地进行单次尝试。而且,随着人们对模型性能要求的不断提高,这种局限性愈发明显,成为了制约大型语言模型进一步发展的瓶颈之一。
不过,重复采样这一方法的提出,为解决这一问题提供了一个全新的思路。在一些特定场景下,比如数学、编程以及解谜任务中,重复采样已经展现出了一定的潜在益处。它就像是一个隐藏的宝藏,等待着人们去挖掘它的无限价值。例如,AlphaCode 在编程竞赛任务中,通过使用大规模采样策略,性能随着采样次数的增加而不断提高,最终在与人类选手的较量中取得了令人瞩目的成绩。这充分证明了重复采样在提升模型推理能力方面的巨大潜力,让人们对它在更广泛领域的应用充满了期待。
研究方法
重复采样的核心思想其实很简单,但却蕴含着巨大的力量。它主要可以分为以下几个关键步骤:
1. 候选方案生成 :当模型面对一个需要解决的问题时,它会根据自身的训练知识以及设定的采样参数(比如温度值等),开始生成各种各样的解决方案。温度值在这里就像是一个 “创意调节器”,较高的温度值会让模型生成更加多样化、富有创意的方案,而较低的温度值则会使生成的方案更加集中于模型认为最有可能正确的方向。这些方案就像是从模型脑海深处涌出的多条思路,形态各异,各有特点,为后续的挑选提供了丰富的素材。
2. 验证器筛选 :在生成一定数量的候选方案后,验证器就开始登场发挥作用了。验证器就像是一个严格的裁判,它的任务是对每个候选方案进行仔细审查和评判。不同的任务对应着不同的验证规则和标准。比如在数学问题中,验证器会根据数学公式、定理等规则,检查候选方案中的计算过程和结果是否正确;在编程任务中,验证器则会运行代码,查看其是否能通过预设的测试用例,输出正确的结果。只有那些经得起验证器严格审查的方案,才有资格进入下一步。
3. 最终答案确定 :经过验证器的筛选后,会留下一些被认为是正确的候选方案。这时,就需要根据一定的策略从这些方案中挑选出一个最合适的作为最终答案。这个过程就像是在众多优秀的选手中选出冠军一样,可能会考虑方案的简洁性、效率、创新性等多种因素,从而确定出一个最佳的方案呈现给用户。
在研究中,为了全面评估重复采样的效果,研究人员精心挑选了多个不同类型的模型和任务进行实验。模型方面,除了常见的 Llama - 3、Gemma、Pythia 等,还涵盖了不同规模、不同训练方式的版本。这些模型有的擅长处理文本生成任务,有的在代码理解和生成方面表现出色,还有的在数学推理上有着独特的优势,它们对问题的思考和回答方式也因此各有差异,就像是一个由不同专业背景的专家组成的团队。
而在任务选择上,研究人员也是费了一番心思。例如 SWE - bench Lite 是一个涉及真实世界 GitHub 问题的复杂任务,它要求模型能够在理解问题描述的基础上,对代码仓库进行编辑修改,并且通过一系列单元测试来验证修改的正确性;CodeContests 则是一个编程竞赛任务集合,模型需要根据问题描述编写 Python 代码,并且代码要能通过隐藏的输入输出测试用例;MATH 数据集则专注于数学问题求解,涵盖了从初等数学到高等数学的多个领域,模型需要输出详细的解题步骤和最终答案。这些任务就像是不同类型的竞技场,能够让模型在各种场景下充分展示自己的能力。
评估指标方面,覆盖率(Coverage)和精确度(Precision)是两个关键的衡量标准。覆盖率的计算方法是,对于所有测试问题,只要有一个候选方案被验证为正确,就算作覆盖了一个问题。它反映了模型在面对不同问题时,能够产生有效解决方案的广度,就像是在统计模型能够解决的问题范围有多大一样。而精确度则更加注重从众多候选方案中准确挑选出正确答案的能力,它的计算方式是将最终确定的正确答案数量与所有确定的答案数量之比。在不同的任务中,这两个指标的具体定义和计算方式会根据任务的特点进行相应的调整,以确保评估结果能够真实地反映模型和验证器的性能。
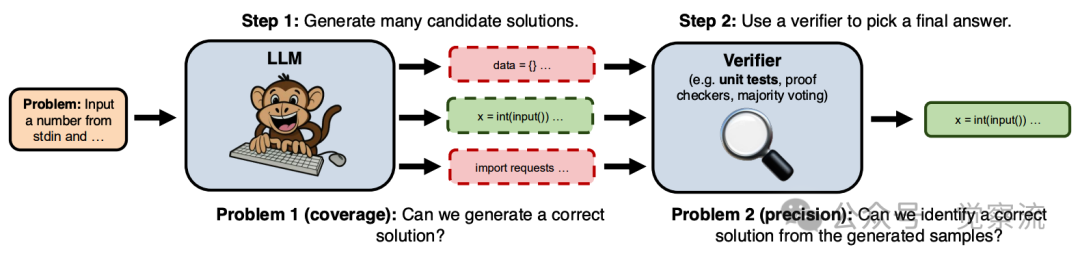
在本文中遵循的重复采样过程。1)我们通过从具有正温度的大型语言模型(LLM)中采样,为给定问题生成许多独立的候选解决方案。2)我们使用领域特定的验证器(例如,代码的单元测试)从生成的样本中选择最终答案。
实验结果
实验结果可谓是相当振奋人心。在代码生成任务中,比如使用 Gemma - 2B 模型解决 CodeContests 编程问题时,情况发生了翻天覆地的变化。当采样次数仅为 1 次时,覆盖率仅为 0.02%,这就好比在广阔的沙漠中几乎找不到一丝绿洲的踪迹。然而,随着采样次数不断增加,当采样次数达到 10,000 次时,覆盖率竟然飙升至 7.1%,这就像是在沙漠中发现了一片郁郁葱葱的绿洲,模型解决问题的能力得到了质的飞跃。而在形式证明领域,使用 Llama - 3 - 8B - Instruct 模型对 MiniF2F - MATH 中的数学问题进行证明时,表现同样出色。随着采样次数的不断增加,覆盖率如同稳步攀升的阶梯,从相对较低的水平逐步攀升至较高的数值,每一个采样次数的增加都带来了覆盖率的提升,就像是攀登高峰时每一步都离顶点更近了一点。
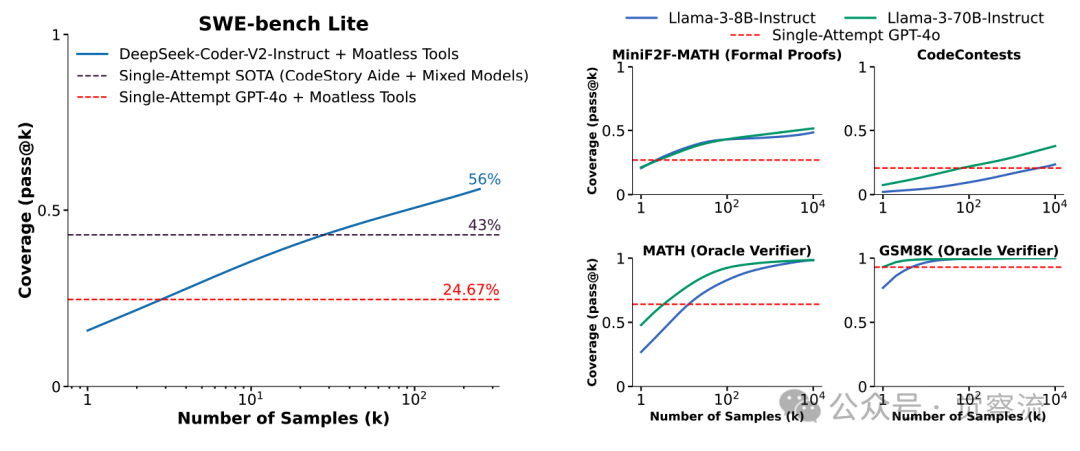
在五个任务中,覆盖率(至少有一个生成样本解决的问题比例)随着样本数量的增加而提高。值得注意的是,通过重复采样,用一种开源方法在SWE-bench Lite上的解决率从15.9%提高到了56%。在数学问题求解方面,模型的表现也没有让人失望。以 Llama - 3 为例,在解决 MATH 数据集中的难题时,随着采样次数从 100 增加到 10,000,覆盖率从 82.9% 迅速增长至 98.44%。这意味着,模型能够解决的问题范围在不断扩大,几乎涵盖了数据集中的绝大多数问题。然而,在使用多数投票和奖励模型等方法挑选最终答案时,性能提升却相对有限。例如,在 GSM8K 数据集上,当采样次数从 100 增加到 10,000 时,多数投票方法的准确率仅从 40.50% 提升到 41.41%。这就好比是,虽然模型在不断产生更多的正确答案,但在没有得力的验证工具时,这些正确答案就像是被埋在沙子里的金子,难以被挖掘出来,最终只能挑选出少量的正确答案,导致整体性能提升幅度较小。
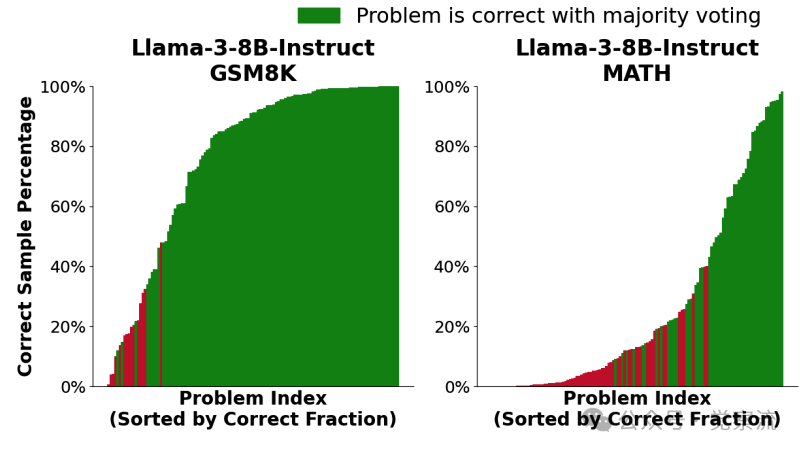
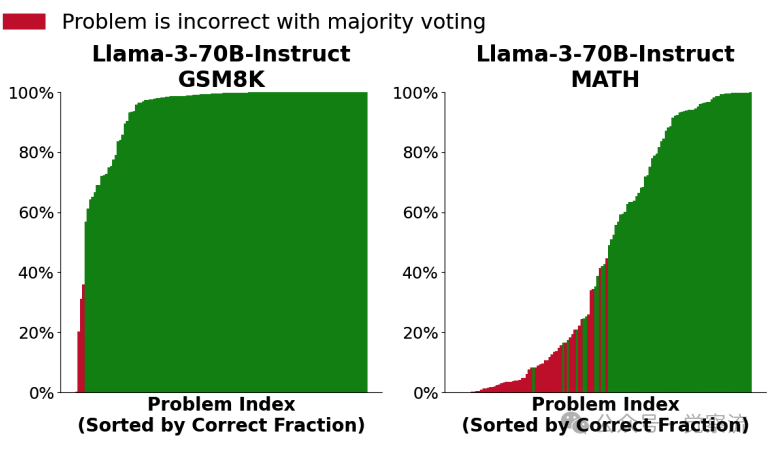
柱状图显示了在评估的GSM8K和MATH子集中的每个问题中,正确样本的比例(在10,000个样本中)。每个问题有一个柱子,柱子的高度对应于得出正确答案的样本比例。如果自洽性选择了正确答案,则柱子为绿色,否则为红色。注意,有许多问题存在正确答案,但这些正确答案的采样频率很低。此外,在不同的任务中,同一模型的覆盖率变化趋势也呈现出多样性。例如,在 MATH 数据集上,Llama - 3 - 8B - Instruct 模型的覆盖率曲线随着采样次数的增加呈现出较为平稳的上升趋势,而 Llama - 3 - 70B - Instruct 模型的覆盖率曲线则相对陡峭一些,这表明模型规模的扩大在一定程度上能够加速覆盖率的提升。而在 CodeContests 任务中,Gemma - 2B 模型的覆盖率曲线则呈现出一种从低到高逐步跃升的态势,这反映出该模型在编程任务上的适应性和潜力。这些结果以直观的图表形式呈现了出来。在上图,我们可以清晰地看到,随着采样次数的增加,不同模型在各个任务上的覆盖率曲线呈现出稳步上升的趋势。例如,在 SWE - bench Lite 任务上,DeepSeek - Coder - V2 - Instruct 模型的覆盖率从单次采样的较低水平,随着采样次数增加到 250 次时,一举超越了单次尝试的最先进水平(43%),达到了 56%。这就像是一匹黑马,在不断的尝试中逐渐崭露头角,最终超越了传统强国,夺得了冠军。而在 CodeContests 任务上,Gemma - 2B 模型的覆盖率曲线同样展现出惊人的增长势头,从最初的几乎为零,一路上扬,最终在 10,000 次采样时达到了 7.1% 的覆盖率,完美诠释了什么叫做 “厚积薄发”。

使用Moatless工具 Agent 框架比较不同模型在SWE-bench Lite数据集上的API成本(以美元计)和性能。结果显示,当采样数量增加时,开源的DeepSeek-Coder-V2-Instruct模型能够以不到闭源前沿模型三分之一的价格,达到相同的解决问题的比率。
同时,下图展示了不同模型在同一任务上的表现对比。在 MATH 数据集上,较小的 Pythia - 70M 模型在单次采样时的覆盖率几乎为零,但随着采样次数增加到 10,000 次,覆盖率竟然达到了 57%,远超其单次采样的表现。这就好比是一个初出茅庐的选手,虽然一开始表现平平,但通过不断的努力和尝试,最终展现出了惊人的潜力。而相比之下,一些大型模型在单次采样时表现优异,但在采样次数增加后的提升幅度却相对较小,这说明模型的大小并不是决定重复采样效果的唯一因素,模型的架构、训练方式等多种因素都会对结果产生影响。
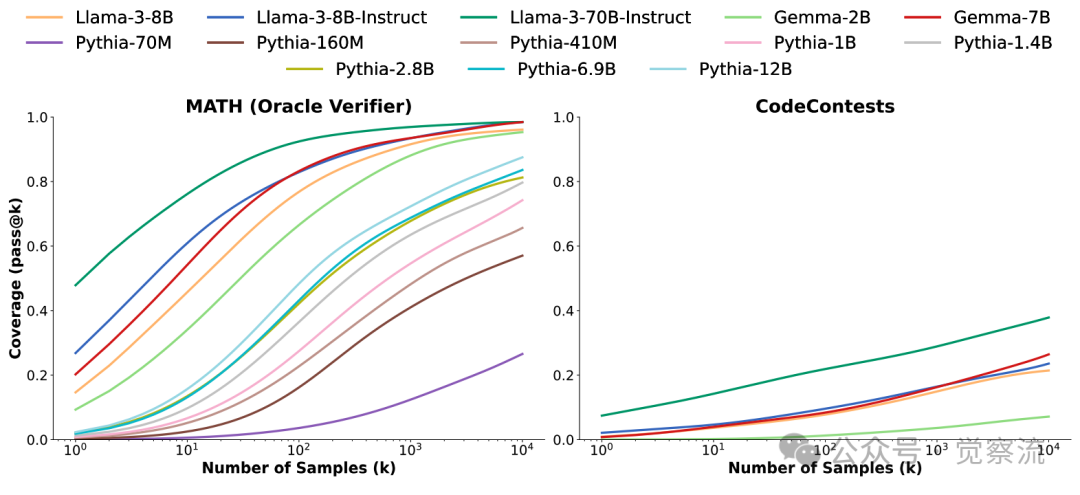
通过重复采样来扩展推理时间计算,可以在多种模型大小(70M-70B)、模型家族(Llama、Gemma和Pythia)以及不同级别的训练后阶段(基础模型和指令模型)中实现一致的覆盖率提升
关键结论
重复采样对覆盖率的提升效果简直可以用 “惊人” 来形容。它让那些原本在单次采样时表现平平的模型,通过多次尝试,能够解决更多的问题,就像是给这些模型插上了翅膀,让它们能够飞得更高、更远。在一些场景下,它甚至能够让一些原本性能稍弱的模型通过多次采样,实现对单次采样更强模型的超越。这就像是在一场赛跑中,原本不被看好的选手通过不懈努力和多次冲刺,最终超越了那些一开始领先的选手,夺得了冠军。例如,在 SWE - bench Lite 数据集上,DeepSeek - Coder - V2 - Instruct 模型在单次采样时的性能仅为 15.9%,但随着采样次数增加到 250 次,其性能一举提升至 56%,超过了单次采样的最先进水平(43%)。
![]()
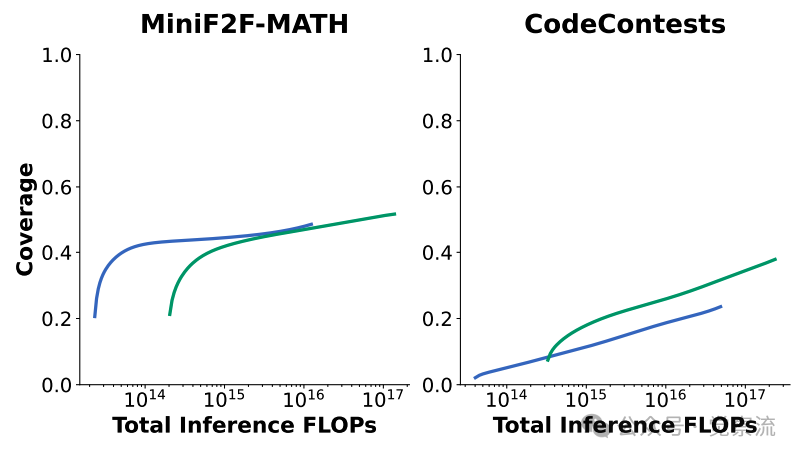
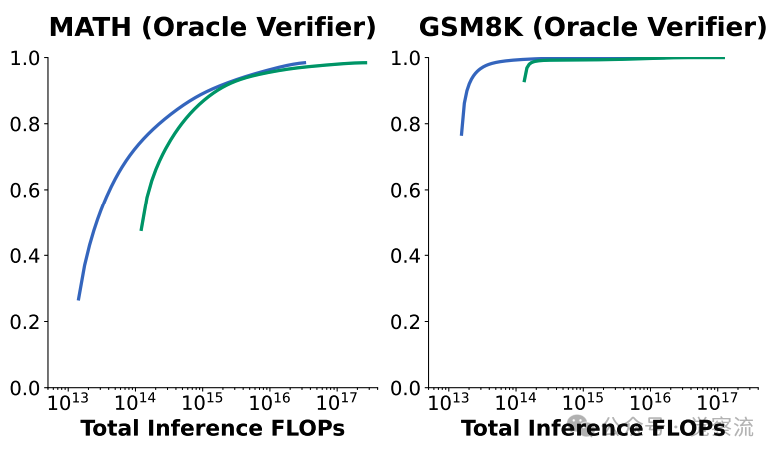
对Llama-3-8B-Instruct和Llama3-70B-Instruct的推理FLOPs数量(用于衡量成本)和覆盖范围进行比较。可以发现,理想的模型大小取决于任务、计算预算以及覆盖范围的要求。需要注意的是,Llama-3-70B-Instruct在GSM8K上未能达到100%的覆盖范围,原因是存在一个标注错误的真实答案。
而且,在推理成本方面,重复采样也展现出了独特的优势。在固定的计算预算下,使用较小规模的模型进行多次采样,有时候会比使用大型模型进行单次采样更具成本效益。这就好比是在有限的经费下,我们选择购买多件性价比高的物品,而不是一件昂贵却使用次数有限的奢侈品。对于一些对成本敏感的应用场景来说,重复采样提供了一种更加灵活且经济实惠的选择,能够让用户在有限的预算内获得更好的性能表现。例如,上图展示了在不同任务和模型尺寸下,推理成本(以 FLOPs 为单位)与覆盖率之间的关系。对于 MiniF2F - MATH、GSM8K 和 MATH 任务,Llama - 3 - 8B - Instruct 模型在固定 FLOPs 预算下通常能够获得比 Llama - 3 - 70B - Instruct 模型更高的覆盖率,这表明在这些任务上,较小的模型通过多次采样更具优势。然而,在 CodeContests 任务中,Llama - 70B - Instruct 模型则在大多数情况下更为划算。这说明,选择最优的模型和采样策略需要综合考虑任务特点、计算预算和性能要求。
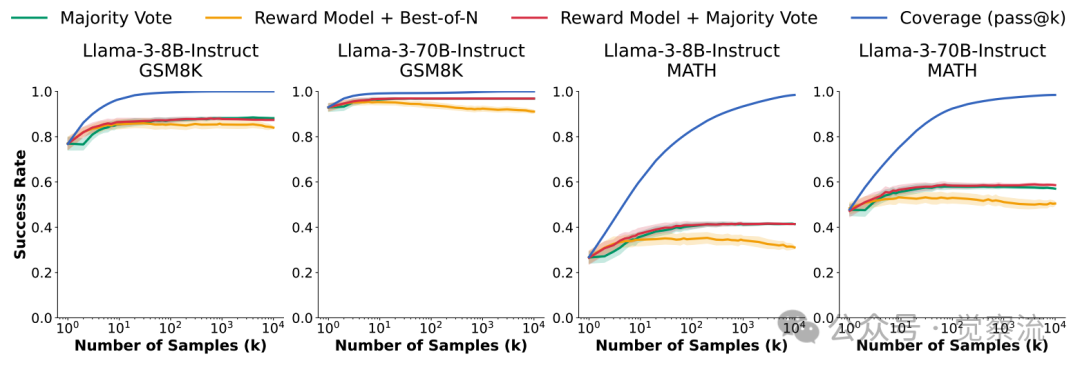
不过,这里也有一个关键因素不容忽视,那就是自动验证工具。它们就像是黑暗中的灯塔,为重复采样指引着方向。如果在没有自动验证工具的情况下,那些常见的验证方法往往会很快遇到瓶颈。以多数投票方法为例,当采样次数增加到一定程度后,其性能提升非常有限,这就导致了一个尴尬的局面 —— 模型虽然能够生成越来越多的候选方案,但却无法有效地从中挑选出正确的答案,就好像在一堆宝藏中迷失了方向,不知道哪一颗才是真正的宝石。这充分说明了自动验证工具在重复采样过程中的重要性,它们能够帮助我们从海量的候选方案中精准地找到正确的答案,从而实现重复采样的最大价值。
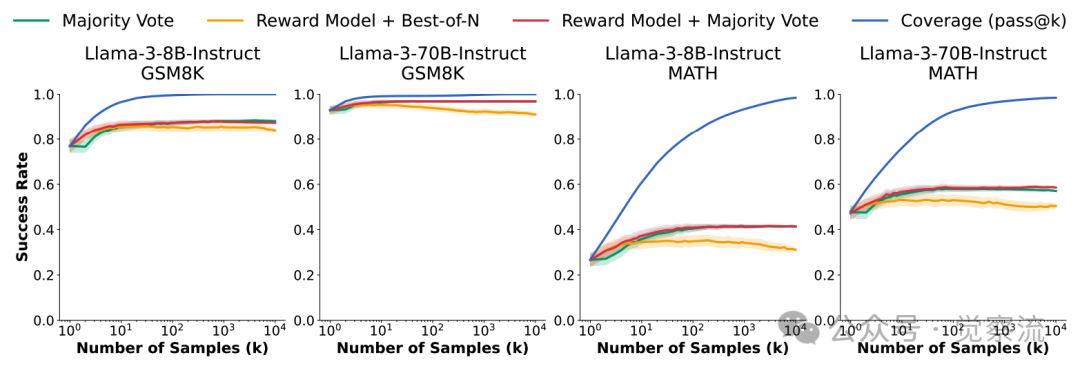
随着样本数量的增加,将覆盖率(与理想验证器的性能比较)与主流的正确答案选择方法(多数投票、奖励模型选择和奖励模型多数投票)进行了比较。尽管接近完美的覆盖率得以实现,但所有样本选择方法都未能达到覆盖率的上限,并且在达到100个样本之前就已经饱和。对于每一个k值,在大小为k的100个子集上计算该指标,然后绘制子集的平均值以及一个标准差。
方法细节与观点
重复采样作为一种扩展推理计算的新方法,它的优势不仅仅体现在性能的提升上,还在于为模型提供了一种更灵活的思考方式。传统的单次采样就像是让模型在瞬间做出一个重大的决定,而重复采样则更像是给模型提供了一个思考和探索的过程。模型不再局限于一次性的 “灵光乍现”,而是可以通过多次尝试,不断地调整和优化自己的答案。这就好比我们在解决一个复杂问题时,常常会先尝试不同的思路,然后根据每次尝试的结果进行反思和调整,最终找到最优的解决方案一样。
然而,重复采样也并非十全十美,它同样存在一些局限性和挑战。例如,在生成众多候选方案时,如何确保这些方案之间的多样性是一个需要解决的问题。如果所有方案都大同小异,那么即使采样次数再多,也很难找到真正优秀的答案。这就像是在一个创新设计比赛中,如果所有的参赛作品都采用了相同的思路和设计风格,那么比赛的精彩程度和创新性就会大打折扣。因此,研究人员需要不断探索新的方法来提高解的多样性,比如引入不同的采样策略,如温度采样、核采样等,调整模型的参数,或者对模型进行微调,让模型能够在思考时更加发散和自由。
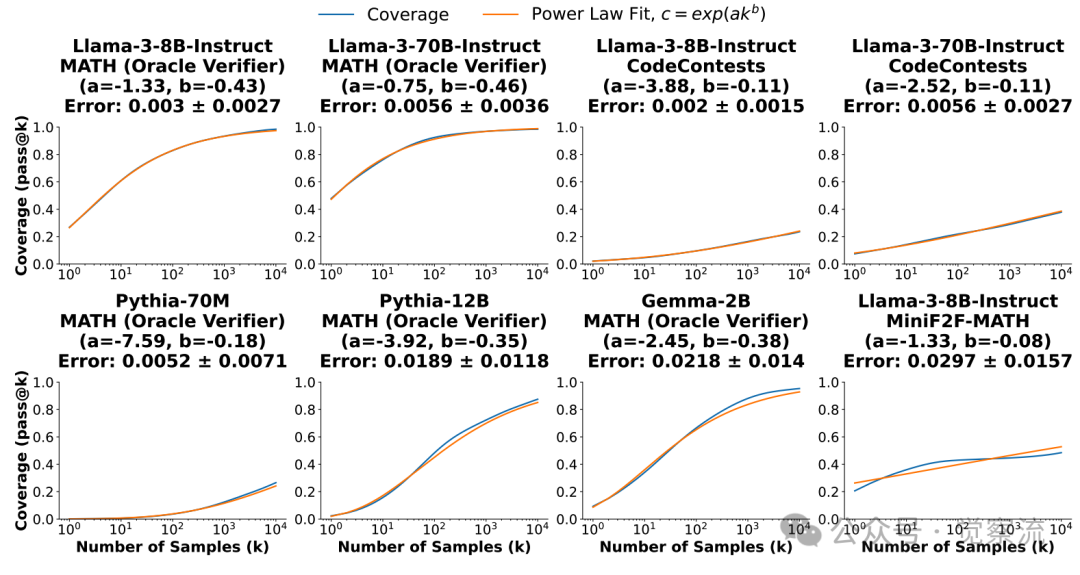
覆盖范围与样本数量之间的关系可以用幂律指数模型来描述,这适用于大多数任务和模型。我们特别指出,某些曲线(例如在MiniF2F-MATH任务上的Llama-3-8B-Instruct模型)并不严格遵循这一趋势。我们展示了在对数尺度上均匀采样的100个点处,覆盖曲线与幂律拟合之间的误差的均值和标准差还有,引入多轮交互也是一个值得深挖的方向。在一些任务中,模型可以利用前一次尝试的结果来指导下一次的采样。例如,在代码生成任务中,模型可以根据前一次生成的代码在测试用例中的表现,分析错误的原因,然后在下一次采样时针对性地修改代码。这样就像我们在解决问题时,会根据之前的尝试经验不断地调整自己的方法,从而一步步靠近正确的答案。同时,从未次尝试中学习也是提高重复采样效果的关键。通过对失败方案的分析,模型可以总结经验教训,避免在后续采样中再犯同样的错误,这就好比是从挫折中汲取智慧,让自己变得更加聪明和强大。
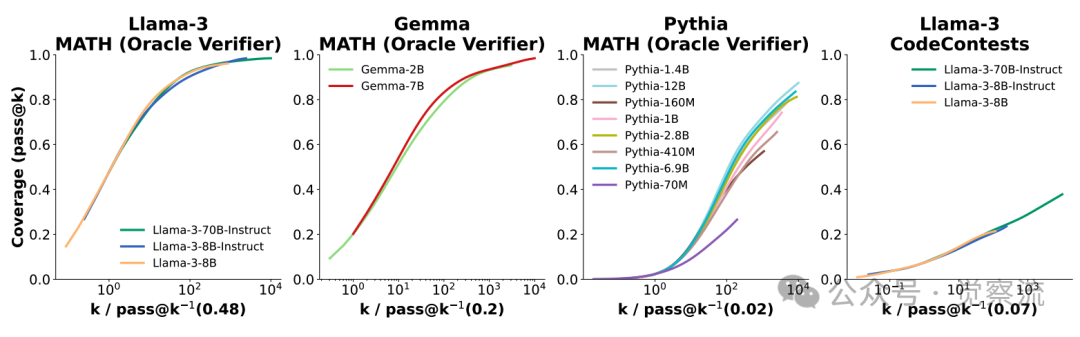
将同一模型家族中不同模型的覆盖曲线叠加在一起。通过水平移动每条曲线(x轴为对数刻度)来实现这种叠加,使得所有曲线都通过点(1,c)。选择c为图中所有模型的最大pass@1分数。可以看到,曲线在平移后的相似性表明,在一个模型家族内,采样扩展曲线具有相似的形状。
而对于推理系统和验证器来说,重复采样也提出了新的要求。推理系统需要能够高效地处理大量的采样任务,这就像是在一个繁忙的港口同时装卸大量的货物,需要合理安排资源和流程,以确保效率和质量。它需要具备强大的并行处理能力,能够同时生成多个候选方案,并且在生成过程中合理利用计算资源,避免资源的浪费。而验证器则需要更加精准和可靠,能够在众多候选方案中迅速而准确地挑选出正确的答案。这就如同在一场大型选秀中,评委需要有一双慧眼,能够从众多选手中发现真正的明星。验证器需要不断优化自身的验证规则和算法,提高验证的效率和准确性,同时还要能够适应不同任务和模型的特点,具有良好的通用性和扩展性。
七、现象与洞察
在重复采样的过程中,研究人员发现了一些非常有趣且富有启发性的现象。有些模型在特定任务上,随着采样次数的增加,覆盖率会出现显著的提升。例如,Gemma - 2B 模型在 CodeContests 编程任务上,从单次采样的 0.02% 的覆盖率,随着采样次数增加到 10,000 次,覆盖率升至 7.1%。这就好像这些模型在这个任务领域有着独特的天赋,只要给予足够的机会,它们就能充分展现自己的才华。而另一方面,有些模型在某些任务上即使采样次数再多,覆盖率的提升也非常有限,这就像是有些选手在特定的赛场上始终找不到感觉,难以发挥出自己的真实水平。
深入分析这些现象,研究人员发现,这与模型的训练数据、架构以及任务的特点都有着密切的关系。例如,那些在编程任务上表现出色的模型,往往是在训练数据中接触了大量的代码相关知识,并且模型的架构也更适合处理编程语言的结构和逻辑。而对于一些数学推理任务,模型的表现则更多地取决于其对数学概念的理解和推理能力,这可能需要模型具备更深层次的语义理解和逻辑推理机制。

对Llama-3-8B-Instruct在解答GSM8K问题时的链式思维(Chain-of-Thought)推理的有效性进行人工评估。每个问题评估了3条链式思维。即使在模型正确率仅为≤10%的难题中,链式思维也几乎总是遵循有效的逻辑步骤。
另外在不同的任务中,验证的难度也有所不同。例如,在数学问题中,验证一个答案的正确性可能需要复杂的逻辑推理和计算。这就像是在解开一个个错综复杂的谜团,验证器需要仔细检查每一步推理是否正确,每一个计算步骤是否符合数学规则,稍有不慎就可能遗漏错误或者误判正确。而对于一些编程任务,虽然有自动测试工具辅助验证,但也会受到测试用例的局限性影响。有些代码可能通过了现有的测试用例,但却存在潜在的漏洞或者在一些边界条件下无法正常运行,这就像是在检查一件工艺品时,只能从某些特定的角度去观察,可能会遗漏一些细节。例如,下图展示了在 GSM8K 和 MATH 数据集上,随着采样次数的增加,多数投票、奖励模型等主流验证方法的性能与覆盖率(基于 oracle 验证器)之间的差距。尽管覆盖率接近完美,但这些验证方法的性能却在采样次数达到 100 左右时就趋于饱和,无法充分利用大量的采样结果。这表明,在没有自动验证工具的情况下,验证方法的局限性成为了限制重复采样性能提升的关键因素。
为了应对这些挑战,研究人员也在不断探索各种可能的解决方法。例如,通过改进模型的训练方式,让模型在生成答案时更加注重中间过程的合理性,而不仅仅是最终结果的正确性。这就像是在培养一个学者时,不仅要关注其最终的研究成果,还要注重其研究过程的严谨性和科学性。同时,开发更加智能的验证技术也是提高重复采样效果的关键。例如,利用深度学习技术构建更加精准的奖励模型,或者结合多种验证方法进行综合判断,从而更全面、更深入地分析候选方案的质量,让每一个优秀的答案都有机会被发现和认可。
讨论、总结
重复采样为大型语言模型的研究和应用带来了一系列新的启示。在模型设计方面,它让我们重新审视模型的大小和性能之间的关系。过去,人们往往认为模型越大,性能就一定越好。然而,重复采样的研究表明,一个中等规模的模型通过巧妙的采样策略和优化的验证方法,能够在某些任务上取得比大型模型更好的效果。这就像是在建筑设计中,有时候一个小而精巧的建筑反而比庞大而笨重的建筑更具实用性。
在推理策略上,重复采样提供了一种全新的思路。我们不再局限于单次尝试,而是可以通过多次采样和优化,让模型在推理过程中拥有更多的灵活性和适应性。这就像是给模型配备了一套精良的装备,让它在面对各种复杂任务时能够更加游刃有余。例如,在处理开放性问题时,模型可以通过多次采样生成多种可能的答案,并根据用户的反馈不断调整和完善答案,从而更好地满足用户的需求。
而对于验证方法来说,重复采样更是提出了一项艰巨的任务 —— 开发更加高效、精准的验证技术。这不仅需要我们在技术上不断创新,还需要我们从应用需求和实际场景出发,设计出更加符合现实要求的验证工具和方法。例如,在医疗、金融等对准确性和可靠性要求极高的领域,验证器需要具备极高的精度和稳定性,以确保模型的输出能够真正满足专业的要求和标准。
未来,一方面,我们可以通过进一步优化重复采样的方法,比如提高采样的效率、增强方案的多样性、引入更加智能的采样控制策略等,来让模型在推理阶段发挥出更大的潜力。另一方面,开发更加高效的验证技术也是一个重要的突破口。如果我们能够创造出一种能够自动理解、分析和评估模型输出的智能验证器,那么重复采样的效果将会得到极大的提升,模型的应用范围也将得到极大的拓展。
这篇研究通过对重复采样技术的深入探索和实验验证,为我们展示了它在提升大型语言模型推理性能方面的巨大潜力。无论是让原本平平无奇的模型通过多次采样实现逆袭,还是在有限的计算预算下实现性能和成本的平衡,重复采样都展现出了其独特的价值。
本文如我开头所提及,是篇复习之作,发出来是分享给需要的伙伴。毕竟重复采样的方法,在当下依然有效。即便你没有用到过这样的工程方法,你也可能用过DeepSeek-R1这样的 Reason Model。重复采样,可以通过 CoT、反思等 prompt 实现或者通过训练 Reason Model 实现,还可以通过多线程的 Agent 经批次推理实现。其本质原理都是类似的,通俗的讲就是“问一遍不行,那就多问几遍,总有回复令人满意”。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量

















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









