




Self-Play Critic(SPC)!它通过“误导生成器”和“评判器”的对抗游戏,让模型在互相博弈中自我进化,无需依赖大量手动标注数据,就能有效提升大语言模型推理步骤的评估能力。

大家好,我是肆〇柒。今天,我想和大家聊一项创新的评估思路——Self-Play Critic(SPC)。大型语言模型(LLM)目前已成为我们生活和工作中不可或缺的工具。它们能够处理各种复杂的任务,从写作到翻译,再到解决数学难题。然而,随着这些模型的推理过程变得越来越复杂,如何确保它们的每一步推理都是可靠的?这个推理过程的可靠性评估,对于提升 LLM 的整体性能来说,至关重要。
现有的 CoT 训练方法,比如监督微调(SFT)和从人类反馈中强化学习(RLHF),虽然在提升模型推理能力方面取得了一定成果,但获取高质量步骤级监督数据的困难,以及模型快速更新迭代导致的标注过时等问题,都让现有的验证模型面临巨大挑战。
最近,我读到了一篇论文《SPC: Evolving Self-Play Critic via Adversarial Games for LLM Reasoning》,里面讲到了一种新方法——SPC。这个方法,通过自我对抗游戏机制,让评判器能够自我进化,无需依赖大量手动标注数据,为 LLM 推理评估提供了全新的思路。在这个机制中,误导生成器会创建包含细微错误的步骤,以此来挑战评判器,而评判器需要准确区分正确和错误的步骤,并提供批判。通过这种持续的对抗过程,SPC 不断为评判器生成正负样本,促使模型不断进化,从而提升其评估能力。
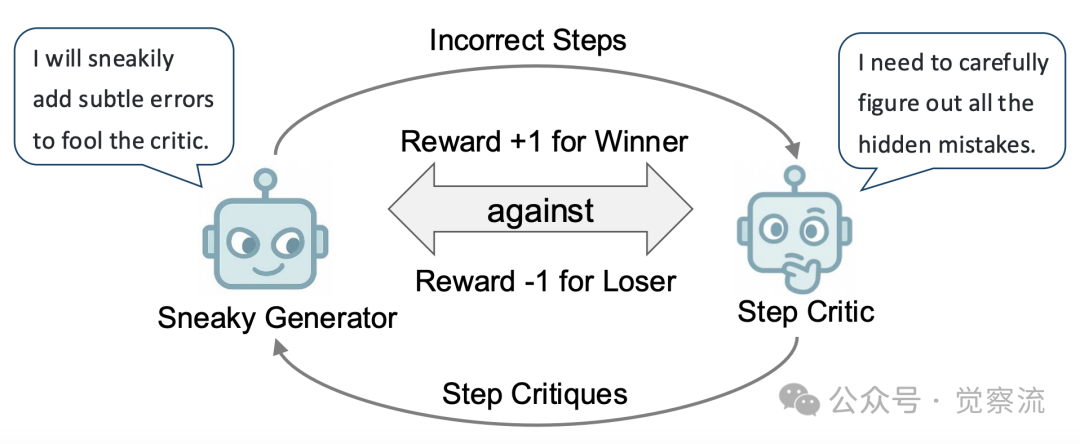
对抗游戏生成强化训练样本
上图就展示了SPC的核心思想。通过对抗游戏,SPC能够持续生成用于强化训练评判器的样本。误导生成器负责创建细微错误的步骤来挑战评判器,而评判器则需要准确区分正确和错误的步骤并提供批判。借助这种对抗优化机制,两个模型能够相互学习,不断提高自身能力,类似于人类通过棋类游戏提升技能的过程。
下面我们一起来看看这篇论文讲了什么。
研究背景与动机
LLM 复杂任务处理与 CoT 推理过程的紧密联系
大型语言模型(LLM)在处理复杂任务时,往往依赖于链式思考(CoT)推理过程。这种推理方式将复杂问题分解为多个步骤逐步解决,使得推理过程的可靠性直接关系到最终答案的准确性。例如,在解决数学应用题时,模型需要通过多步推理,包括理解题目、规划解题步骤、逐步计算等,每一步的准确性都会影响最终结果。LLM 通过 CoT 推理过程,能够在诸如数学求解、逻辑推理等多种复杂任务中展现出色的性能。但随着 LLM 生成的 CoT 日趋复杂和多样化,验证推理过程的可靠性、分析潜在错误并指导测试时搜索以改进推理过程变得尤为重要。近期研究发现,尽管一些先进的 LLM 擅长进行深度思考并生成长 CoT,但其自我批判的有效比例仍然很低,且存在对自身推理过程自我批判的偏差。因此,开发一个能够评估各种 LLM 推理步骤的简单外部评判器,提供步骤级批判显得尤为必要。
现有 CoT 训练方法的局限性及对可靠性评估的需求
现有的 CoT 训练方法,如监督微调(SFT)、从人类反馈中强化学习(RLHF)以及自我强化学习等,在提升模型推理能力方面取得了显著成果。然而,这些方法在获取高质量步骤级监督数据方面面临很多困难。一方面,提取最终答案以确定解决方案的正确性并自动收集训练数据相对简单,但确定推理步骤的正确性并获取用于训练过程验证器的高质量步骤级标注数据则要困难得多。另一方面,LLM 的快速更新迭代使得针对特定 LLM 输出的人工专家标注可能因分布差异而不适用于最新 LLM。再有,仅限于步骤正确性标注的数据集限制了评判模型的训练,使其无法提供实质性的反馈,而仅仅沦为一个评分机制。
SPC 方法论
SPC 框架概述
SPC(Self-Play Critic)是一种新颖的方法,它的核心思想是让两个模型:“误导生成器”(sneaky generator)和“评判器”(critic),相互对抗、共同进化。我们可以把这想象成一场智力游戏。误导生成器就像是一个捣蛋鬼,它的任务是故意制造错误,而且这些错误还要尽量隐蔽,能够骗过评判器。评判器则像是一个侦探,它的任务是仔细分析推理步骤,判断这些步骤是否正确,找出其中的错误。
这两个模型可以分别由两个相同的基模型微调而来。误导生成器通过学习如何将正确的推理步骤转换为错误的步骤,来制造 “陷阱”。而评判器则通过学习如何识别这些陷阱,来提升自己的评估能力。它们之间的对抗游戏,就像是一个永无止境的 “猫鼠游戏”。误导生成器不断尝试制造更难被发现的错误,评判器则不断努力提升自己的识别能力。通过这种方式,评判器的评估能力逐渐提升,最终能够准确地评估 LLM 的推理步骤。
举个例子,在解决一个数学问题时,误导生成器可能会故意在某个计算步骤中引入一个小小的错误,比如将一个简单的加法运算结果写错。评判器接收到这个错误步骤后,会仔细分析这个步骤,判断它是否正确。如果评判器成功识破了这个错误,它就会获得奖励;而误导生成器则会因为 “误导” 不够而受到惩罚。相反,如果误导生成器成功骗过了评判器,误导生成器就会获得奖励,评判器则会受到惩罚。就这样,通过不断地对抗和学习,两个模型都在不断地进步。
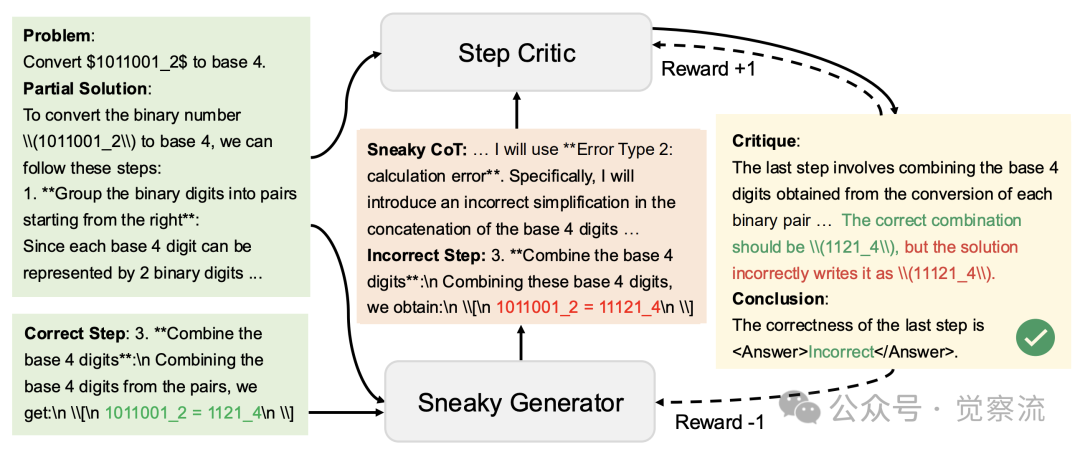
SPC 框架
SPC 框架中,部分解决方案和正确步骤输入到误导生成器中,生成错误步骤后由评判器进行评判。评判器成功识别错误获得正向奖励,反之则受到惩罚。这种机制推动模型不断进化。
误导生成器的初始化与优化
误导生成器的初始化过程就像是给一个新手捣蛋鬼传授一些基本技能。研究者首先使用了一个名为 Qwen2.5-7B-Instruct 的模型,并通过监督微调(SFT)的方式,让这个模型具备了一些基本的错误生成能力。他们利用了一个名为 PRM800K 的数据集,这个数据集包含了大量正确和错误的推理步骤对。

然而,只有错误的步骤还不够,这些错误必须能够真正影响问题解决的成功率,才能算作是有效的错误。因此,在验证误导生成器生成的错误步骤时,研究者采用了一种自动化验证方法。他们让一个开源的 LLM 模型分别从正确的步骤和错误的步骤开始,完成整
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









