



gpt-oss开源了,整个模型架构的设计真的是非常的simple & elegant,本文结合一些前段时间一些Infra相关的争议和自己开发Agent相关的分析, 来对未来模型架构演进做一些分析。
TL;DR
gpt-oss开源了,整个模型架构的设计真的是非常的simple & elegant。本文结合一些前段时间一些Infra相关的争议和自己开发Agent相关的分析, 来对未来模型架构演进做一些分析。
1. Overview
OpenAI这次开源的是gpt-oss-20b 和 gpt-oss-120b两个模型。

图片
在自己的mac m4pro上运行了一下20b的模型, 基于LM Studio输出为38 token/s, 非常快速了。一些专业问题回答思路和格式都也很不错, 这也使得很多小规模部署, 特别是基于它做一些简单的Agent任务成为可能。
Attention使用了GQA和Sliding-window GQA交替的方式, 当然Llama 4也这么干过, 同时还有一个Attention Sink来解决一些long context的任务. 同时这样的结构对于KVCache的处理有很多可以在推理优化中进一步挖掘的地方。
MoE上, 小的20b模型采用了4Active/32Routed, 而较大的120b采用了4Aactive/128Routed. 比较有趣的是Intermediate Size = Hidden Size = 2880. 为什么不升维度呢? 然后MLP还带了Bias. 激活函数用了SwiGLU带了clamp并且, 它的EP并行是如何实现的呢?
然后Reasoning的强度也有高中低的区别...另外和国内一些开源模型相比, 它的最大特点就是层数特别少. 120b只有36层....这样就直接的提高了TPS。
这些疑问都有很多值得推敲的地方。
2. Attention
在Attention这一块, 首先是使用了GQA和Sliding-window GQA交替的方式, 即Hybrid Attention. 在Llama 4中其实也见到过, 但是没有像OAI这样interleave的方式. 这样的好处有几点: 首先计算量少了很多, KVCache也少了很多, 特别是Long-context的情况下。
但是有一个疑问, 如果未来针对更大规模的模型例如一个1T参数左右的GPT-5如果还是这样的方式, 模型可能要继续加宽和加深? 那么势必也会进行一些分布式的推理, EP并行或者AFD怎么处理呢? GQA应该是可以有效的使用AFD和EP的, 而对于Sliding-window GQA本身计算时间会短很多, 那么可能还是和MLP融合? 对于这类hybrid attention的模型如何overlap是一个很好玩的事情。
另外是对于不同的请求context-length在Agent场景也会存在很大的差异, 是不是还有一个根据context不同来配对Decoding的调度算法呢? 实际上对于一个Stateful且计算量和存储长度都有很大差异的情况下, 类比于大数据中的一些Remote Shuffle方式处理数据偏斜, 通过layerwise的KVCache传输来处理呢? 这样来实现一些长context请求驱逐出某个decoding cluster? 同时有一些额外的KVCache内存池作为Stateful的存储似乎也有不少办法去做一些事情?
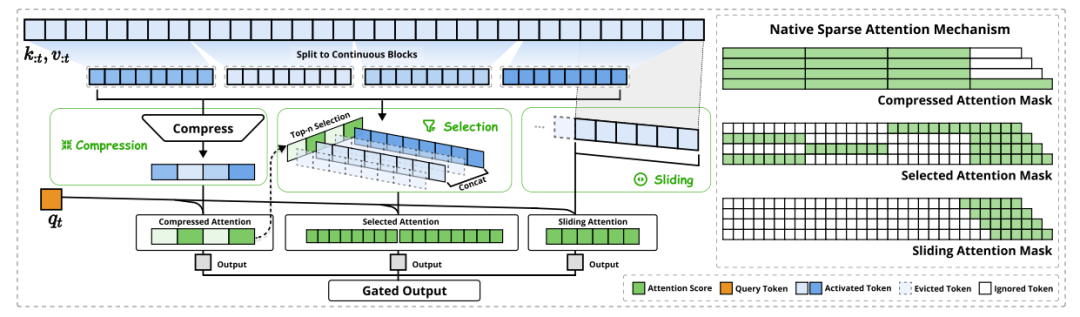
而本质上,针对不同的context长度, 如果有一种大家计算时间都差异不大的方式那不是更好么?们注意到DeepSeek的NSA其实也是使用了Sliding window的方式, 然后使用Gated Output。同时又采用了block selection机制使得整体的计算时间并不会随着context的差异变化过大。
图片
其实从个人的视角来看, 我可能会更偏向于NSA, 特别是Agent场景. 很多工具返回的结果刚好像内存管理那样, 按照Page可以填充到Block中。这样Agent context engineering和NSA本身可以做很多的协同设计了。
另一方面最近在看Google的一篇论文《Learning without training:The implicit dynamics of in-context learning》[1]
Attention本身产生两种输出, 一种是查询x的输出A(x), 另一种是有Context的输出A(C,x)。两者的delta就包含了上下文本身的信息. 当这个Delta经过MLP后, 等价于增加了一个很简单的scratchpad。

图片
然后这篇论文还有一个很好的结果, 使用原始的权重处理A(C,x)等同于使用新的权重 处理x。这样模型不用重新训练又可以进一步的根据上下文更新参数了, 似乎很值得期待, 特别是结合Sutton的The Era of Experience。前段时间我也在考虑如何通过模型推理的经验来动态改变prompt. 感觉这条路又可以做不少事情了。
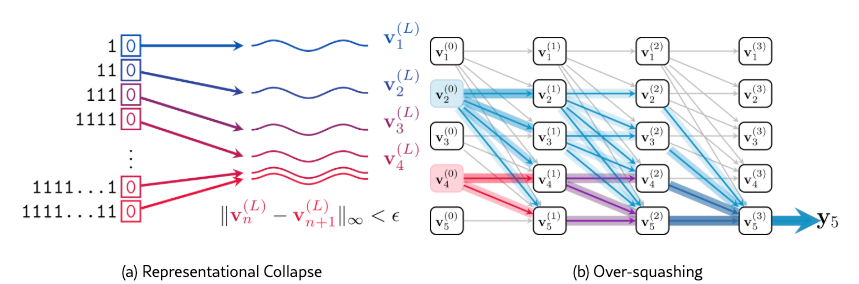
另一方面Attention的一个比较好的实现是Sink Attention, 大致意思是context长了以后, 注意力全中多集中在开始的几个token, 例如论文《Efficient Streaming Language Models with Attention Sinks》[2]
另一篇论文是DeepMind的《Transformers need glasses! Information over-squashing in language tasks》[3] 也提到了类似的问题。
图片
SteamingLLM的做法就是通过Attention Sink来分散注意力, 使得中段和尾段注意力.. gpt-oss创建了一些可学习sink参数, 然后处理如下:
复制
self.sinks = torch.nn.Parameter(
torch.empty(config.num_attention_heads, device=device, dtype=torch.bfloat16)
)
t = sdpa(q, k, v, self.sinks, self.sm_scale, self.sliding_window)
def sdpa(Q, K, V, S, sm_scale, sliding_window=0):
S = S.reshape(n_heads, q_mult, 1, 1).expand(-1, -1, n_tokens, -1)
...
QK = torch.einsum("qhmd,khmd->hmqk", Q, K)
...
QK = torch.cat([QK, S], dim=-1) #拼接Sink
W = torch.softmax(QK, dim=-1) #计算带Sink的softmax
W = W[..., :-1] #丢弃Sink权重
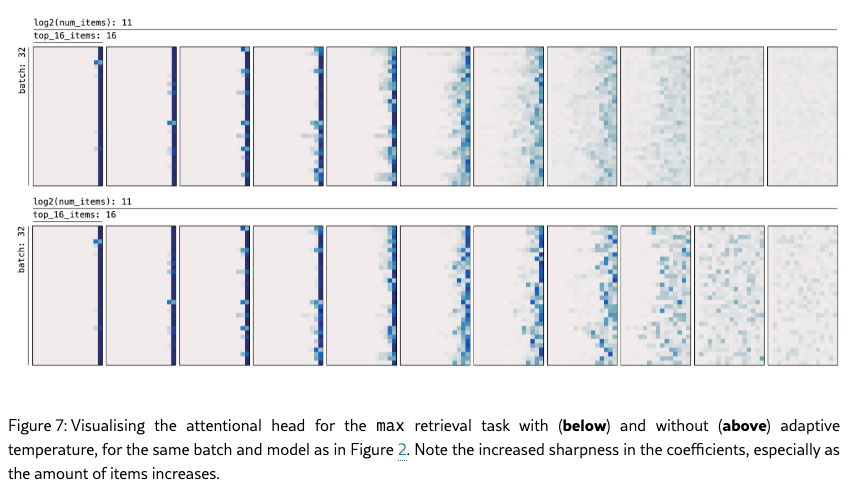
attn = torch.einsum("hmqk,khmd->qhmd", W, V)其实我觉得还有一个补充的点是做一些自适应温度的工作? 也是来自Deepmind 《Softmax is not Enough (for Sharp Size Generalisation) 》[4]
图片
最后还有一个小细节, attn head-dim =64 ? 小了很多, 查询了一下苏老师的文章《关于维度公式“n > 8.33 log N”的可用性分析》[5],好像只有在Sliding-window GQA上是匹配的. 为了迁就这个而构成的一个Trade-off?
另一个问题就来了, 针对国产的各种NPU算力又要怎么搞呢?
3. MoE
其实对于120B的模型, 还是采用的Finegrain的Experts, 专家数128个. 但是没有Shared Expert. 其实算法上去掉Shared也没啥问题. 但是Fine grain本身的意义就不在多说了. 关键的问题回到Intermediate Size = Hidden Size = 2880. 为什么不升维度呢? 因为这个模型本来大小就相对小一点, 新的B200一类的卡显存贼大. 4个Expert直接拼接在一起不就成了一个intermediate = 4 * hidden size大矩阵了么?
然后MLP还带了Bias. 激活函数用了SwiGLU带了clamp并且, 实际上也构成了一个残差项的连接. 这些设计的动机是什么我不知道...
其实这一块,如果我们要走hybrid attn的路, 做EP或者AFD似乎还有一些事情要处理. 特别是Sliding-window GQA的那一层. 突然想到一个idea, 两批请求错层去做overlap, 然后通过GreenContext去限制Full GQA和 Sliding-window GQA的计算资源是不是有收益呢?
至少我们看到的是在Attn上大家都在想方设法去解决long-context的各种效率问题, 这些问题解决了A和F之间的差异其实也就开始变小了...不过OAI这种Intermediate :hidden = 1:1 的设计是否在更大的模型上会采用, 还是针对小模型的时候拼接处理容易做的一些设计, 我不知道... 或许一些更大规模的模型, 例如1T参数的又绕到1:4. 感觉这里还是有不少设计空间的...
4. 总结
总体来看, 这次CloseAI再次Open带来了不少变化, 这些变化似乎又给Infra赏了一口饭吃. 模型-系统-硬件的协同又有好多活干了~ 还有一些gpt-oss-mcp-server和tools的API挺有趣的, 后面再花时间学习吧!
参考资料
[1] Learning without training: The implicit dynamics of in-context learning: https://arxiv.org/pdf/2507.16003
[2] Efficient Streaming Language Models with Attention Sinks: Efficient Streaming Language Models with Attention Sinks
[3] Transformers need glasses! \faGlasses Information over-squashing in language tasks: https://arxiv.org/html/2406.04267v2
[4] Softmax is not Enough (for Sharp Size Generalisation): https://arxiv.org/html/2410.01104v3
[5] 关于维度公式“n > 8.33 log N”的可用性分析: 关于维度公式“n > 8.33 log N”的可用性分析 - 科学空间|Scientific Spaces
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。
因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量


















 4306
4306

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









