



未来的AI竞争,不是比谁的模型大,而是比谁的数据好。就像石油时代,掌握油田的人掌握了能源;AI时代,掌握数据的人掌握了智能。所以,如果你在做AI,别再纠结于模型架构了。多想想:你的数据护城河在哪里?

一位做AI创业的朋友跟我抱怨:"模型架构都差不多,算力也能买到,为什么我们的模型就是比不过大厂?"
我问他:"你们用什么数据训练的?"
他说:"Common Crawl啊,大家不都用这个吗?"
我笑了。这就像用同样的食材,同样的锅,就想做出米其林三星的味道。 AI圈有个公开的秘密:模型架构已经不是秘密,算力可以用钱堆,唯独数据,成了真正的护城河。
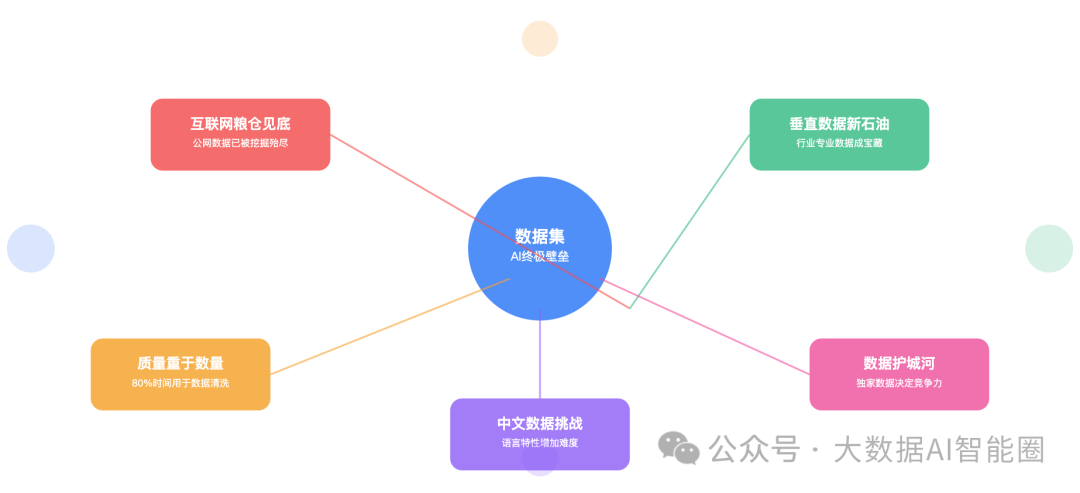
互联网的"粮仓"快见底了
OpenAI的Sam Altman说过一句话:"我们可能已经用完了互联网上所有高质量的文本数据。"
这话听起来很夸张,实际上一点都不夸张。
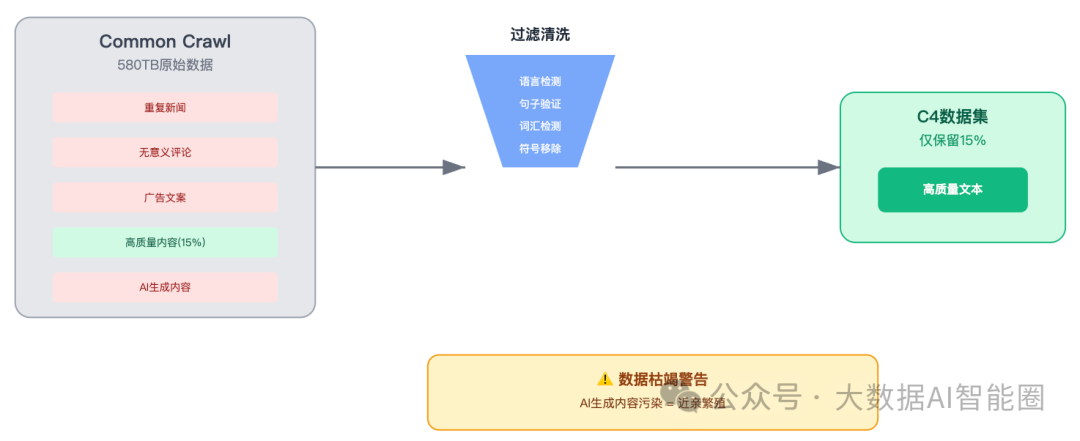
Common Crawl这个全球最大的网页数据库,580TB的原始数据,听起来很多对吧?Google拿来训练C4数据集,过滤完只剩15%。为什么?因为大部分都是垃圾。
重复的新闻、无意义的评论、各种广告文案...真正有价值的内容,少得可怜。
更要命的是,现在AI生成的内容越来越多。用AI生成的数据再去训练AI,这不就是近亲繁殖吗?
一位在某大厂做数据工程的朋友告诉我,他们现在最头疼的不是模型调参,而是去哪儿找新鲜的、高质量的数据。
"公网上的数据,基本被各家大模型公司翻了个遍。现在谁手里有独家数据,谁就有了竞争优势。"
垂直数据成了新的石油
既然公网数据不够用了,那去哪儿找数据?
答案是:垂直领域。
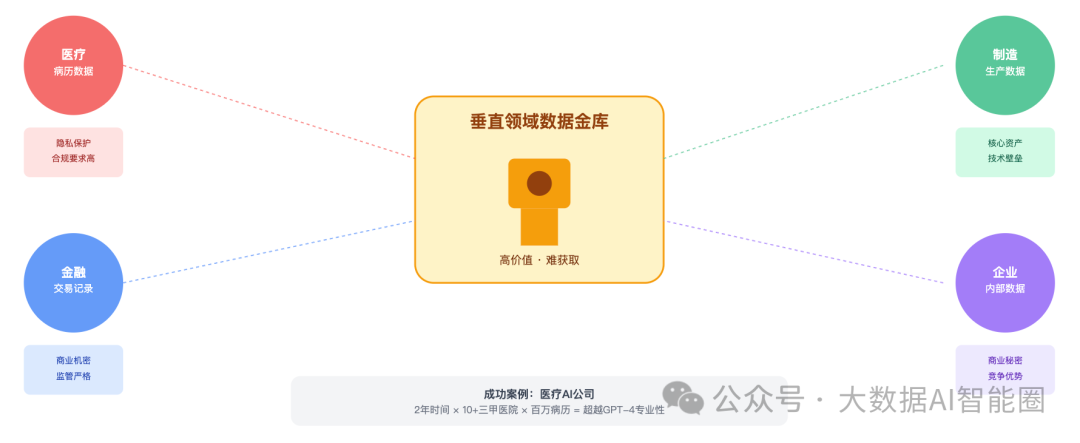
医疗行业的病历、金融行业的交易记录、制造业的生产数据...这些深藏在各个行业里的专业数据,才是真正的宝藏。
我认识一家做医疗AI的公司,他们花了两年时间,跟十几家三甲医院合作,整理了上百万份脱敏病历。就凭这个独家数据集,他们的医疗问答模型在专业性上甚至超过了GPT-4。
但这里有个悖论:越是有价值的数据,越难获取。
医院的病历涉及隐私,金融数据涉及商业机密,企业内部数据更是核心资产。想要这些数据?先过合规这一关。
所以你会发现,现在做AI的公司,不是在训模型,就是在谈数据合作。
技术能力反而成了基础配置,数据获取能力才是核心竞争力。
数据质量比数量更重要
"我们有10TB的训练数据!"
每次听到这种话,我都想问一句:这10TB里,有多少是真正有用的?
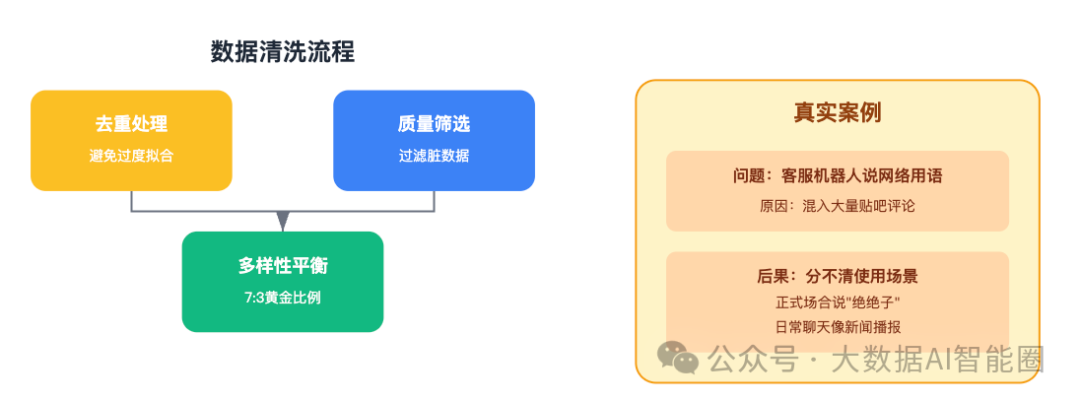
数据集构建有个"二八定律":80%的时间都花在数据清洗上,只有20%的时间在真正训练模型。
为什么要花这么多时间清洗?因为脏数据会毁掉你的模型。
一个做NLP的朋友跟我分享过一个案例。他们训练的客服机器人,经常会蹦出一些奇怪的网络用语。一查才发现,训练数据里混入了大量的贴吧评论。
"你知道最可怕的是什么吗?"他说,"不是模型学会了网络用语,而是它分不清什么时候该用,什么时候不该用。"
如果某个网页在数据集里重复了100次,模型就会过度学习这部分内容。这就像一个学生把同一道题做了100遍,考试的时候只会做这道题。
更深层的问题是数据的多样性。如果你的数据都来自新闻网站,训练出来的模型说话就像个新闻主播。想让模型既能写学术论文,又能日常聊天,还能编程?那就需要各种类型的数据均衡搭配。
有经验的团队都知道,通用数据和专业数据的黄金比例大概是7:3。但这个比例也不是绝对的,要根据具体场景调整。
中文数据的特殊挑战
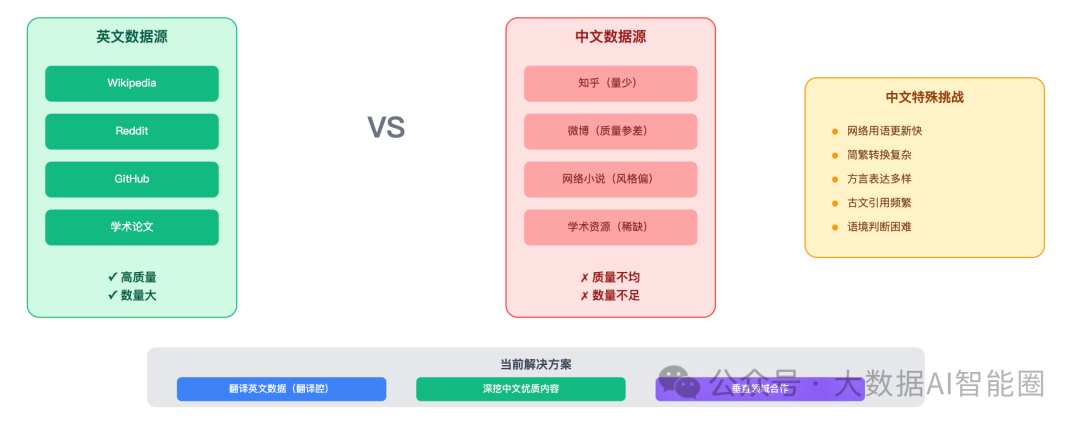
做中文大模型,难度直接翻倍。
英文互联网内容丰富,维基百科、Reddit、GitHub...高质量数据源很多。中文呢?
知乎算是质量比较高的,但内容量跟Reddit比差远了。微博倒是量大,但你敢直接用吗?网络小说倒是不少,但训练出来的模型可能会把商业报告写成霸道总裁文。
更麻烦的是中文特有的语言现象。
网络用语更新太快,"绝绝子"、"拿捏了"...模型刚学会,可能就过时了。简繁转换、方言、古文引用,每一个都是坑。
一位做中文NLP的朋友吐槽:"最难的不是让模型理解中文,而是让它理解什么时候该用网络用语,什么时候该用书面语。"
所以现在很多团队的做法是:翻译英文数据。但翻译过来的数据总有一股"翻译腔",用多了模型说话也变味了。
真正的解决方案?
还是要深挖中文互联网的优质内容,同时跟各个垂直领域合作,获取原生的中文专业数据。
结语
回到开头那位朋友的问题:为什么大厂的模型就是比创业公司强?
不是因为他们的算法有多高明,而是因为他们有数据。
Google有YouTube、搜索记录;Meta有Facebook、Instagram;微软有GitHub、LinkedIn。这些独家数据源,是多少钱都买不来的。
创业公司想突围,只能另辟蹊径。要么深耕某个垂直领域,用专业数据建立壁垒;要么创新数据获取方式,比如众包、合成、交换。
未来的AI竞争,不是比谁的模型大,而是比谁的数据好。
就像石油时代,掌握油田的人掌握了能源;AI时代,掌握数据的人掌握了智能。
所以,如果你在做AI,别再纠结于模型架构了。多想想:你的数据护城河在哪里?
毕竟,同样的GPT架构,OpenAI能做出ChatGPT,你能吗?
差别就在数据上。
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获取
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击文章最下方名片即可前往获
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量.

















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









