








论文:LIMR: Less is More for RL Scaling
代码:https://github.com/GAIR-NLP/LIMR
出处:SJTU, SII, GAIR
一、背景
o1(OpenAI, 2024),Deepseek R1(Guo等,2025)和Kimi1.5(Team等,2025)等模型验证了通过 RL 训练,模型能够自然地产生复杂的推理能力,包括自我验证、反思和扩展的思维链。
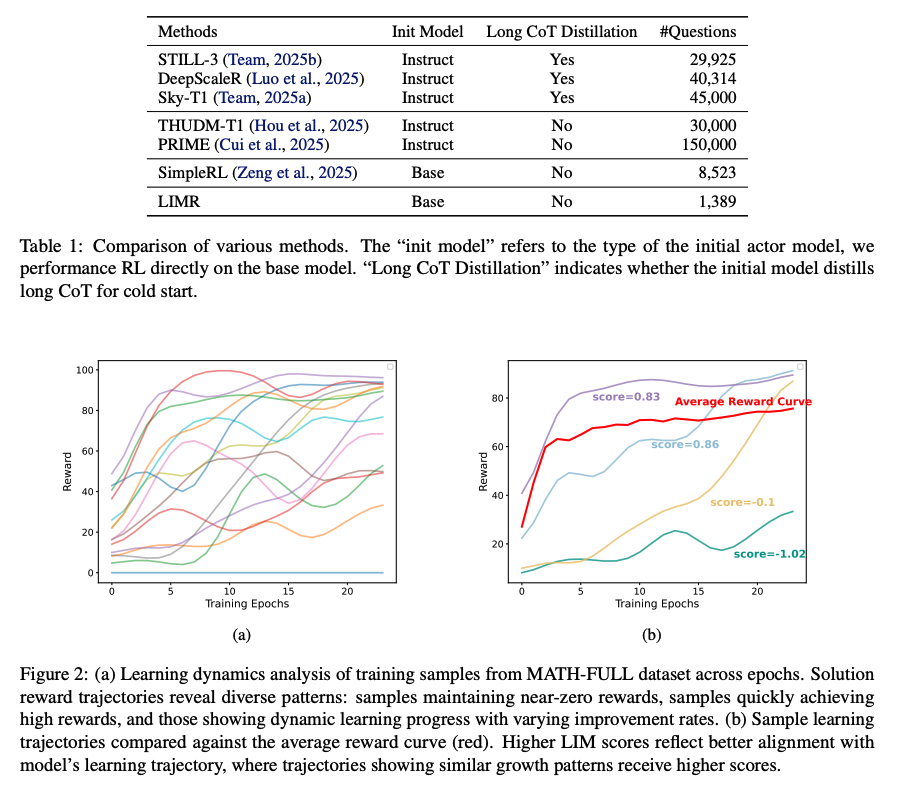
然而,这些厉害工作的训练数据和规模不透明,使得开源社区难以在其成功基础上进一步发展。后续的一些开源方案(如表1所示)探索了从基础模型到长链思维模型的各种实验场景,RL数据规模从8K(Zeng等,2025)到150K(Cui等,2025)不等,但缺乏关于最佳数据需求或扩展原则的明确指导,就会导致以下问题。
- 缺乏明确的数据规模基准,研究人员必须依靠反复试验,导致资源利用效率低下,并可能无法获得很好的结果。
- 该领域缺乏系统分析样本数量对模型性能的影响,难以就资源分配决策
一般来说,会有一个假设,即:“更大RL训练数据集必然会带来更好性能”。但是,本文作者验证发现训练样本的质量和相关性远比数量重要。
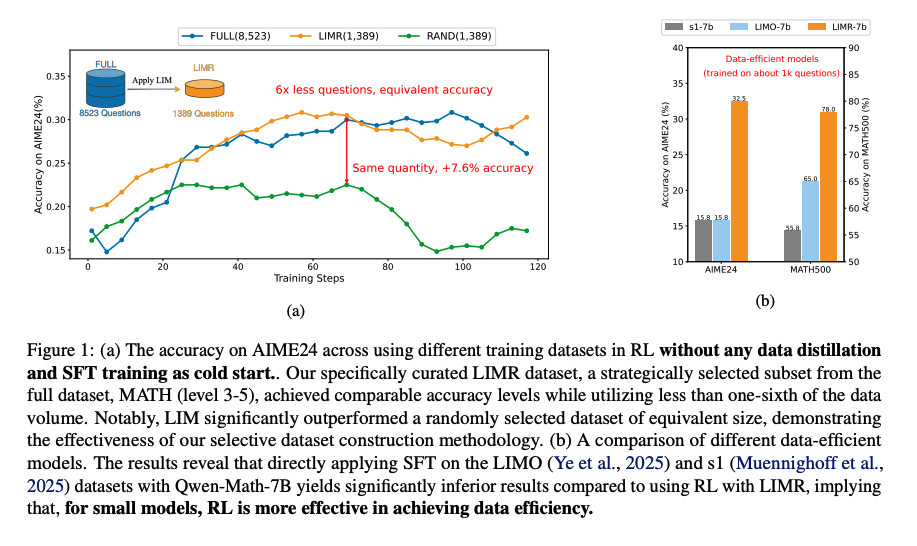
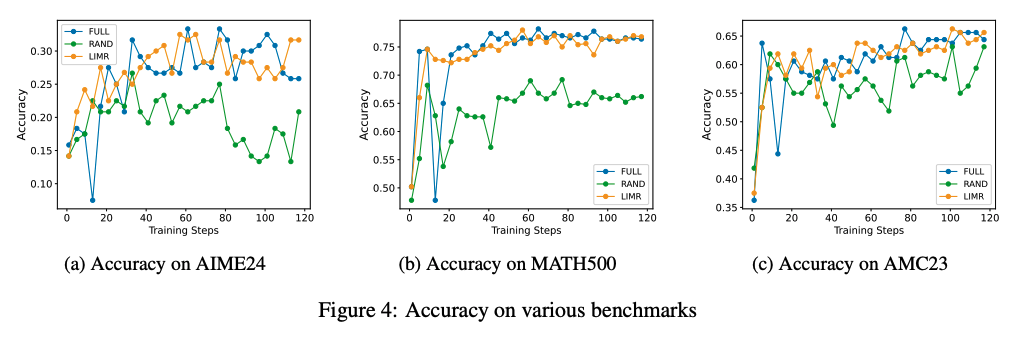
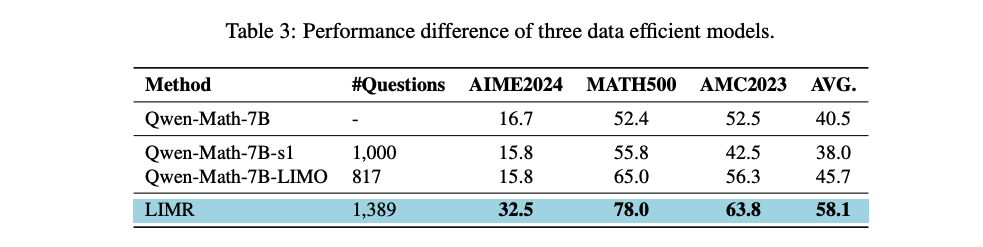
- 精心选择的一小部分RL训练样本(1389个)能够获得与完整数据集(8523个)相媲美甚至更优的性能。
- 开发了一种自动定量评估RL训练样本潜在价值的方法,称为 Learning Impact Measurement(LIM)。该方法能够有效预测哪些样本将对模型改进贡献最大,无需手动挑选样本
- 证明在数据稀缺的情况下,RL可能对增强推理能力更有效。
二、方法
作者提出的 LIM 方法,用于量化样本在强化学习优化过程中的价值,通过分析学习的动态从而挑选出对强化学习效果提升的最有效的样本
如何分析不同样本对应强化学习动态的影响?
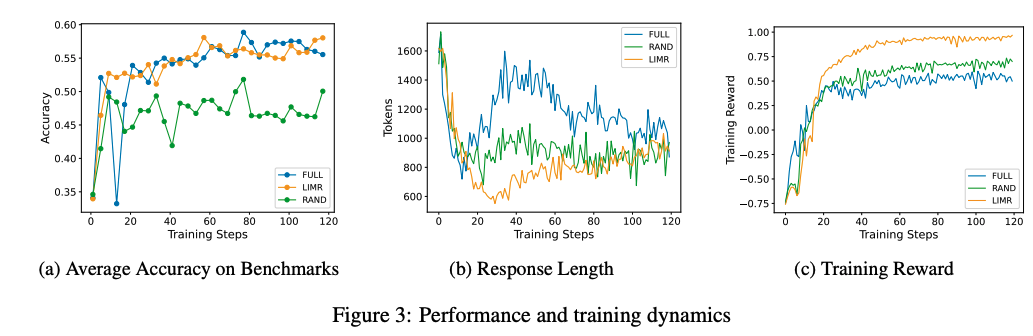
作者使用包含8,523个不同难度级别(3-5)的数学问题的数据集MATH-FULL进行分析,发现不同样本对模型学习的贡献是不均等的,不同于传统方法将所有样本一视同仁,如图2a,一些样本随着训练的进行表现的稳定,另一些样本则表现的比较复杂。
所以作者通过检查样本与模型整体学习进展的对齐程度,可以系统地衡量其在强化学习中训练数据的价值。LIM 以模型对齐的轨迹分析为核心,通过评估训练样本对模型学习的贡献来进行分析。而且作者发现,那些学习模式能够补充模型整体性能轨迹的样本往往在优化中更有价值。
2.1 LIM
前面我们知道了不同样本对模型的贡献程度是不同的,那如何衡量这些样本的质量从而提升强化学习模型的效果呢?
在神经网络学习通常遵循对数增长模式的情况下,所以作者使用模型的平均奖励曲线作为衡量样本效果的参考(图2b):
r avg k = 1 N ∑ i = 1 N r i k , k = 1 , … , K r_{\text{avg}}^k = \frac{1}{N} \sum_{i=1}^{N} r_i^k, \quad k = 1, \ldots, K ravgk=N1i=1∑Nrik,k=1,…,K
其中, r i k r_i^k rik 表示第i个样本在第k个epoch的奖励,N是样本的总数。
对于每一个样本,LIM计算一个归一化的对齐分数如下,这个分数可以衡量这个样本对模型的贡献或对齐程度,分数越高则对齐行越高。
s i = 1 − ∑ k = 1 K ( r i k − r avg k ) 2 ∑ k = 1 K ( 1 − r avg k ) 2 s_i = 1 - \frac{\sum_{k=1}^{K} (r_i^k - r_{\text{avg}}^k)^2}{\sum_{k=1}^{K} (1 - r_{\text{avg}}^k)^2} si=1−∑k=1K(1−ravgk)2∑k=1K(rik−ravgk)2
样本选择策略:
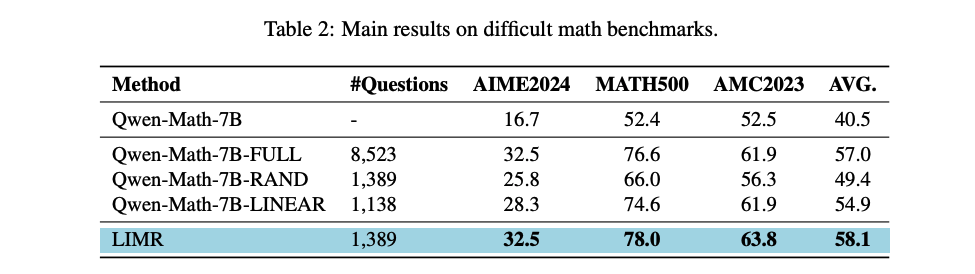
基于对齐分数,LIM 选取 s i > θ s_i > \theta si>θ 的样本,其中 θ \theta θ 作为质量阈值,本文的实验中,将 θ \theta θ 设置为0.6,从原始数据集中获取了1,389个高价值样本,形成优化后的数据集(LIMR)。
其他用于对比实验的基本选择策略:
- 随机采样基线(RAND): 随机选择1,389个样本自MATH-FULL数据集中,以匹配样本大小,从而提供一个评估选择性采样效果的基本参考点。
- 线性进展分析方法(LINEAR): 基于样本在训练周期中表现出稳定改善的连续性来评估样本。尽管这种方法能够捕捉到逐步进展的样本,但它经常忽略那些在早期快速收益然后趋于稳定的有价值样本。使用阈值 θ = 0.7 \theta = 0.7 θ=0.7,这种方法得到了1,189个样本。
奖励设计:
R ( answer ) = { 1 如果答案正确, − 0.5 如果答案不正确但格式正确, − 1 如果答案有格式错误。 R(\text{answer}) = \begin{cases} 1 & \text{如果答案正确,} \\ -0.5 & \text{如果答案不正确但格式正确,} \\ -1 & \text{如果答案有格式错误。} \end{cases} R(answer)=⎩ ⎨ ⎧1−0.5−1如果答案正确,如果答案不正确但格式正确,如果答案有格式错误。
三、效果
训练细节:
- PPO 训练 Qwen2.5-Math-7B
- batch size=256, 温度=1.2,每次采样8个样本
**RL 在少量数据下 超越了 SFT: **



















 450
450

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











