







1.均方误差MSE(L2)
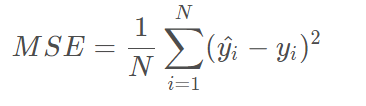
2.均方根误差RMSE
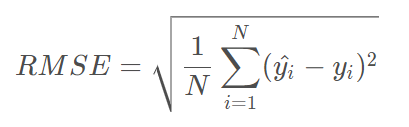
3.平均绝对误差MAE(L1)
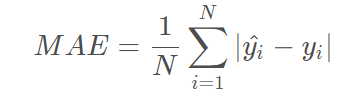
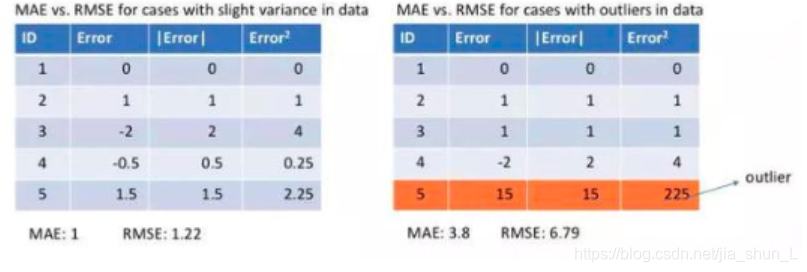
4.比较
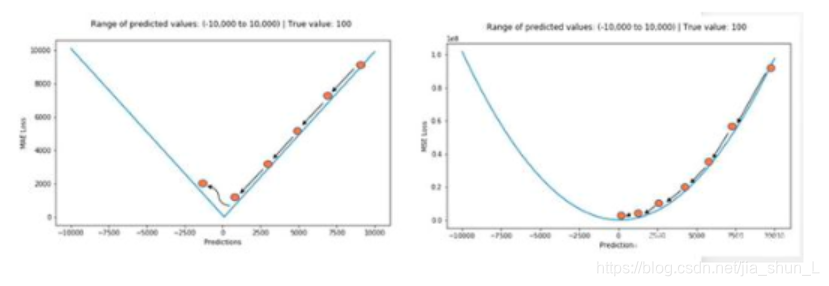
| MSE | MAE |
|---|---|
| 平均数 | 中位数 |
| 受异常点的影响较大 | 对异常点的鲁棒性较好 |
| 损失的梯度随损失的增大而增大,在损失趋于0时则会减少,因此结果更加精准 | 损失梯度不变,不利于学习 |
| 使用固定的学习率也有效收敛 | 使用变化的学习率,在损失接近最小值的时候减少学习率 |
| 导数连续,求解效率较高 | 导数不连续,求解效率较低 |
在实际应用中,按照不同情况选择不同的损失函数,然而L2以及L1都有不足的地方。于是我们引入huber损失函数。
5.Huber损失函数
huber损失函数本质上是绝对误差,只是在误差很小的时候,就变为平方误差。超参数delta的取值取决于对异常点的定义。
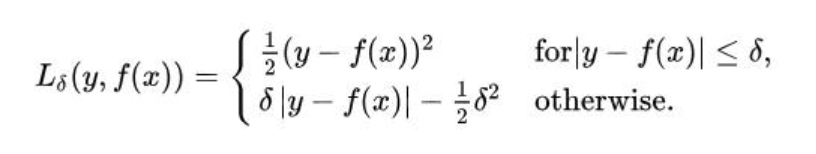
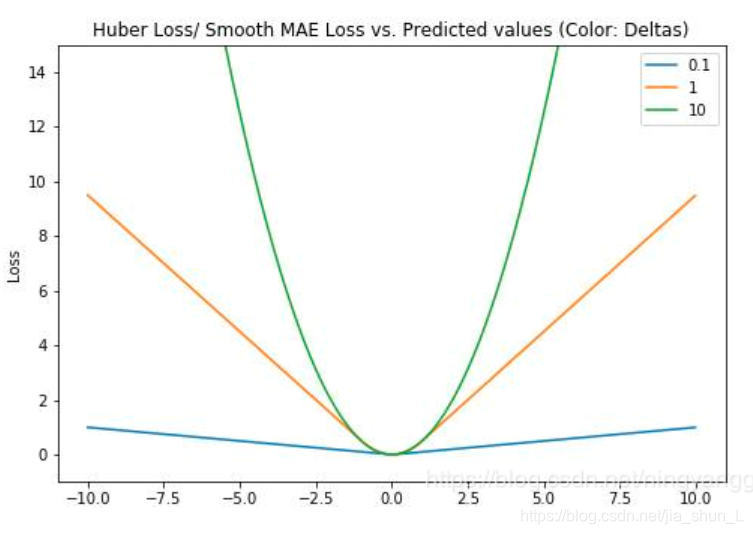
优点:梯度随着损失变化,有效收敛,导数连续而且对异常点更加鲁棒。
缺点:确定超参数delta

















 1917
1917

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









