



YOLO11
YOLO11 C++推理YOLO11是Ultralytics最新发布的 目标检测、实例分割、姿态评估的系列模型视觉轻量化框架,基于前代YOLO8版本进行了多项改进和优化。YOLO11在特征提取、效率和速度、准确性以及环境适应性方面都有显著提升,达到SOTA。
TensorRT C++ SDK
最新版本的TensorRT10.x版本已经修改了推理的接口函数与查询输入输出层的函数,其中以YOLO11对象检测为例,获取输入与输出层维度查询代码如下:
// 获取输入与输出维度
auto inputDims = this->engine->getTensorShape("images");
auto outDims = this->engine->getTensorShape("output0");
// 获取输入维度信息
this->input_h = inputDims.d[2];
this->input_w = inputDims.d[3];
printf("inputH : %d, inputW: %d \n", this->input_h, this->input_w);
// 获取输出维度信息
this->output_h = outDims.d[1];
this->output_w = outDims.d[2];
std::cout << "out data format: " << this->output_h << "x" << this->output_w << std::endl;
推理的API函数已经更新直接输入GPU缓存数据,代码如下:
cv::Mat blob = cv::dnn::blobFromImage(image, 1 / 255.0, cv::Size(this->input_w, this->input_h), cv::Scalar(0, 0, 0), true, false);
cudaMemcpyAsync(buffers[0], blob.ptr<float>(), 3 * this->input_h * this->input_w * sizeof(float), cudaMemcpyHostToDevice, stream);
// 推理
context->executeV2(buffers);
其中buffers为GPU数据缓存。
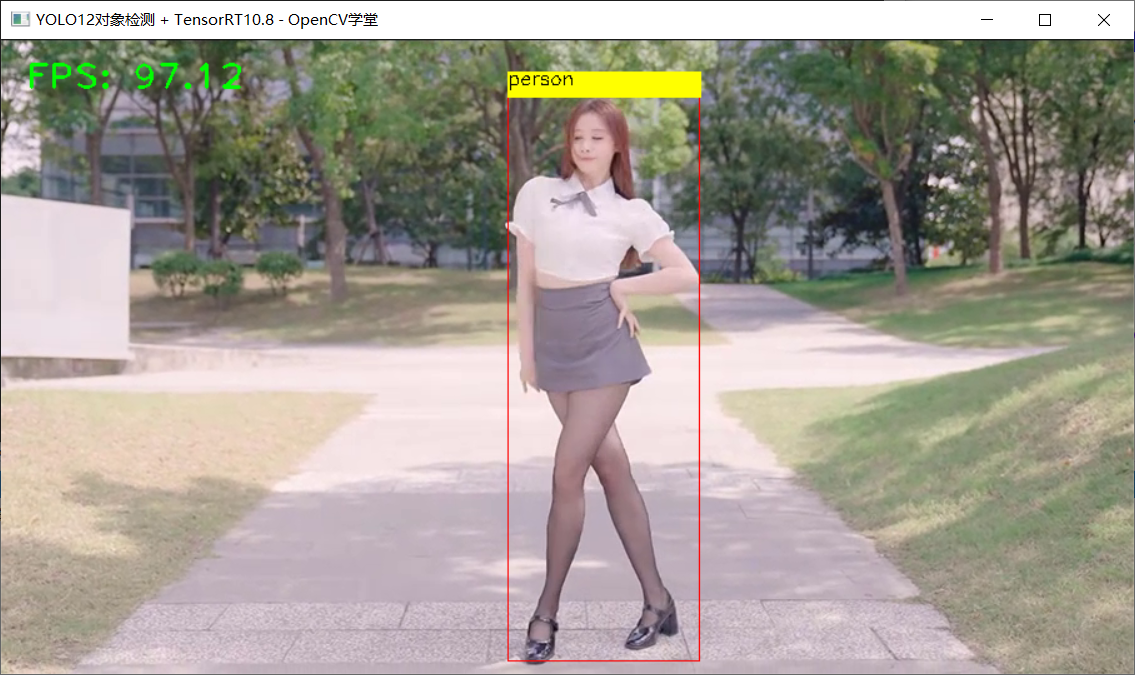
YOLO11对象检测 + TensorRT10.8推理演示:
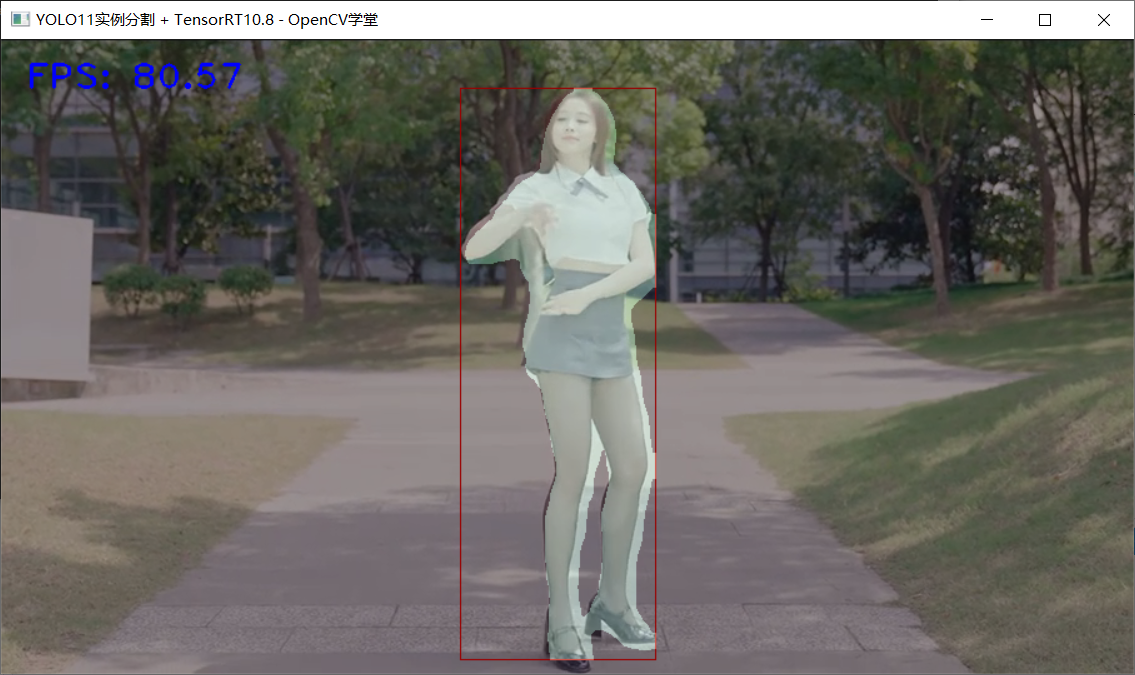
YOLO11实例分割 + TensorRT10.8推理演示:
YOLO11姿态评估 + TensorRT10.8推理演示:

上述代码我均已经完成C++的封装,SDK 三行代码即可客户端调用,调用演示的代码如下:
# include <tensorrt_yolo11_pose.h>
#include <iostream>
#include <fstream>
int main(int argc, char** argv) {
std::shared_ptr<YOLO11TRTPose> detector(new YOLO11TRTPose());
detector->initConfig("D:/python/yolov5-7.0/yolo11n-pose.engine", 0.25f);
//cv::Mat frame = cv::imread("D:/boogup.jpg");
//detector->detect(frame);
//cv::imshow("YOLO11姿态评估 + TensorRT10.8 - OpenCV学堂", frame);
//cv::waitKey(0);
//cv::destroyAllWindows();
cv::VideoCapture capture("D:/images/video/dance.mp4");
cv::Mat frame;
std::vector<DetectResult> results;
while (true) {
bool ret = capture.read(frame);
if (frame.empty()) {
break;
}
detector->detect(frame);
cv::imshow("YOLO12姿态评估 + TensorRT10.8 - OpenCV学堂", frame);
char c = cv::waitKey(1);
if (c == 27) { // ESC 退出
break;
}
}
cv::waitKey(0);
cv::destroyAllWindows();
return 0;
}
源码获取
掌握TensorRT10.8 C++如何部署图像分类,对象检测,实例分割,语义分割主流模型,自定义脚本一键INT8量化模型,使用OpenCV CUDA加速图像预处理等各种工程化部署推理技巧,实现推理部署的工程化封装支持,客户端三行代码即可调用,支持YOLOv5~YOLO12系列模型一键集成部署与量化!全部解锁上述技能与源码获取,点击这里


















 8589
8589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











