







目录
| 序号 | 函数 | 说明 |
|---|---|---|
| 1 | replace()函数 | 替换元素 |
| 2 | map()函数 | 处理某一单独的列【最重要】—用于Series |
| 3 | rename()函数 | 替换索引 |
| 4 | apply()函数 | 对数据进行操作,既支持Series,也支持DataFrame |
| 5 | transform()函数 | 对数据进行操作,既支持Series,也支持DataFrame |
1. 源数据
def make_df(indexs, columns):
data = [[str(j) + str(i) for j in columns] for i in indexs]
df = pd.DataFrame(data=data, index=indexs, columns=columns)
return df
df = make_df([1, 2, 3, 4], list('ABCD'))

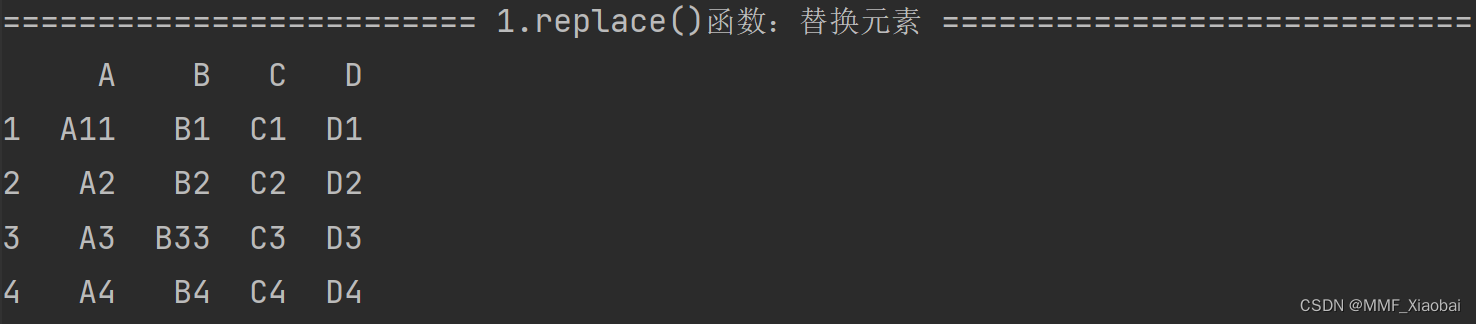
2. replace()函数【替换元素】
df.replace({'A1': 'A11', 'B3': 'B33'})
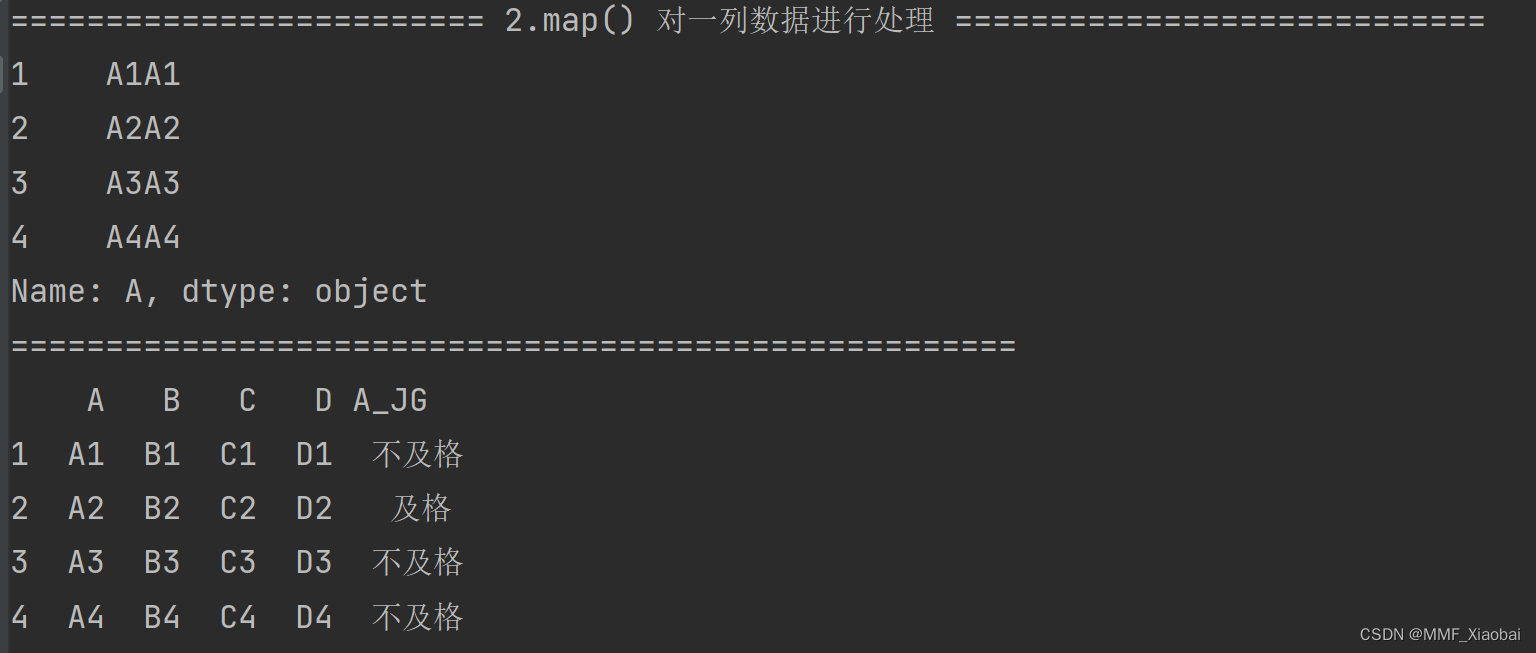
3. map()函数【对一列数据进行处理】
df2 = df.copy()
# map() 一般用在Series数据结构,不能用于DataFrame
# 将第一列中的数据 乘2
df2['A'].map(lambda x: x * 2)
# 新增一列:判断第一列的数据是否及格
df2['A_JG'] = df2['A'].map(lambda n: '及格' if n == 'A2' else '不及格')
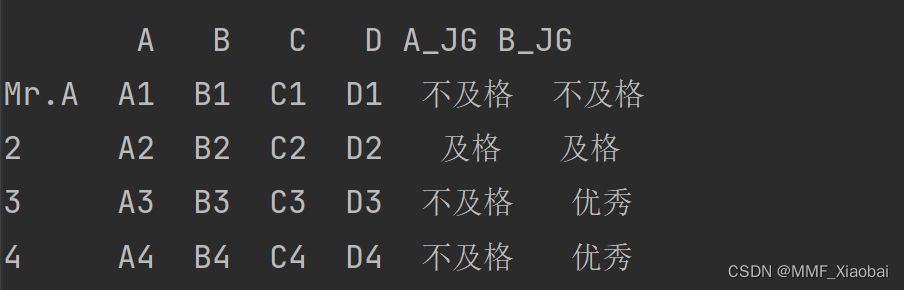
4. rename()函数【替换索引】
df2.rename(index={1: 'Mr.A'}) # 默认情况下 只修改行索引
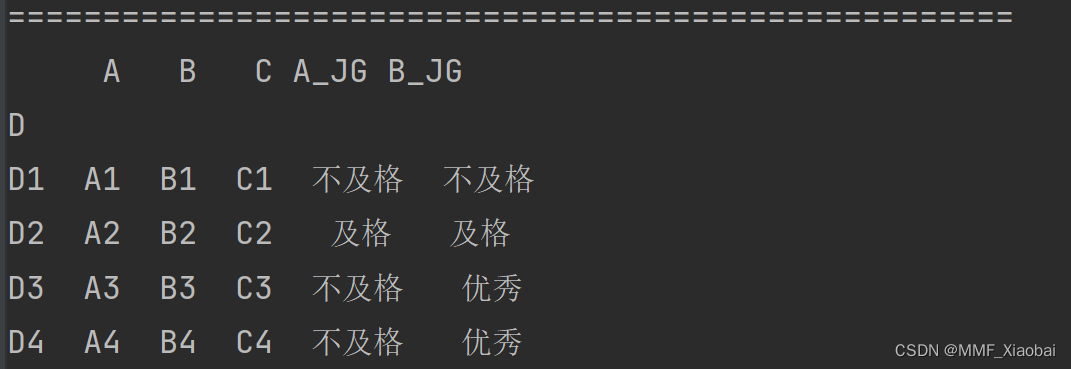
df2.rename(columns={'A': 'a_column'}, axis=1) # 修改列索引

# 重置索引,会生成0123这样的索引,原有的索引会生成index这一列的数据
df2.reset_index()

# 设置索引,将列变成行索引
df2.set_index(keys=['D'])
5. apply()函数
Pandas 的 apply() 方法是用来调用一个函数,让此函数对数据对象进行批量处理。
apply() 使用时,通常放入一个 lambda 函数表达式、或一个函数作为操作运算。
5.1 源数据
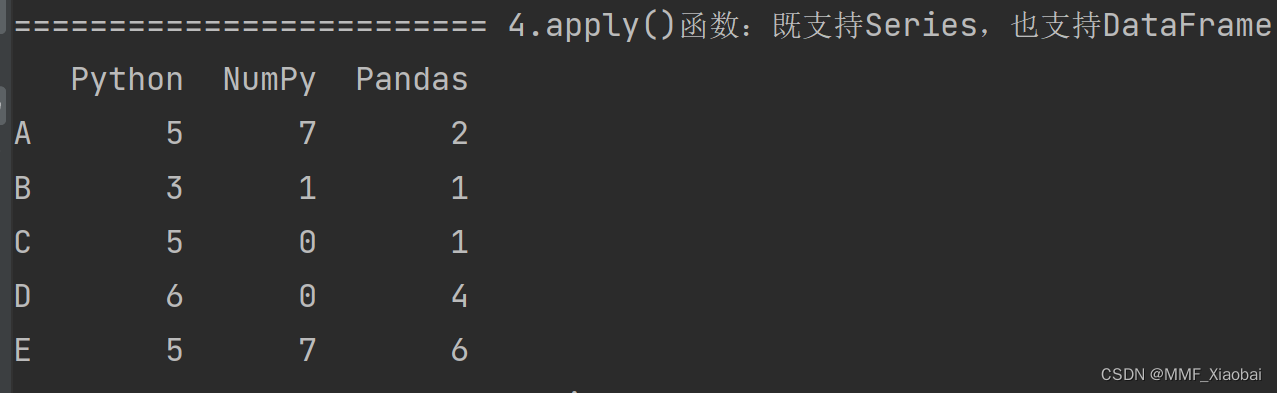
data = np.random.randint(0, 10, size=(5, 3))
df = pd.DataFrame(data=data, index=list('ABCDE'), columns=['Python', 'NumPy', 'Pandas'])
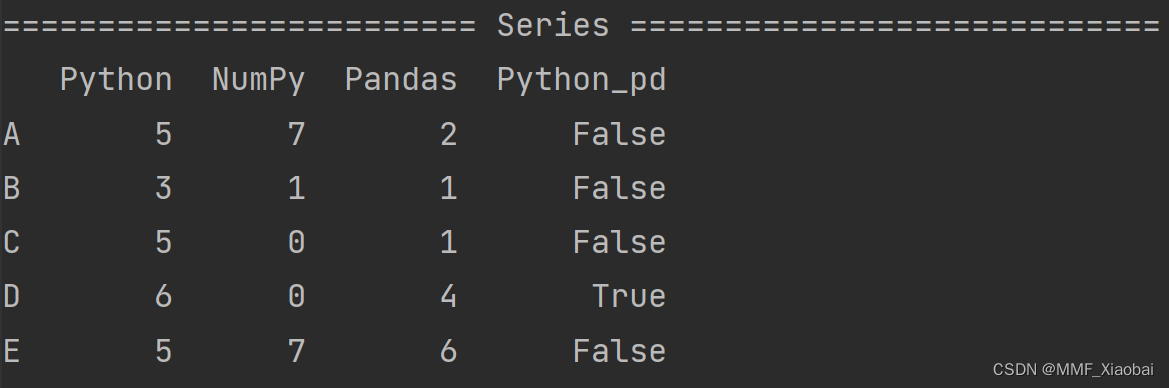
5.2 对Series进行操作,大于5的数据为True,否则为False
df['Python_pd'] = df['Python'].apply(lambda x: True if x > 5 else False)
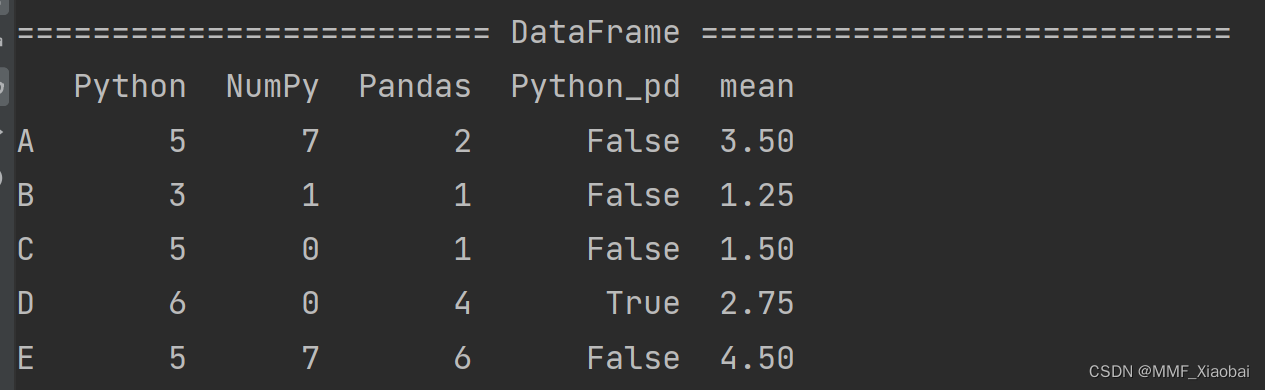
5.3 对DataFrame进行操作,求均值
# axis=0列 axis=1行
# x指的是DataFrame中某一列或某一行的Series数据
df['mean'] = df.apply(lambda x: x.mean(), axis=1)
5.4 applymap()是DataFrame专有的方法,其中的x是每一个元素
df.applymap(lambda x: x + 100)
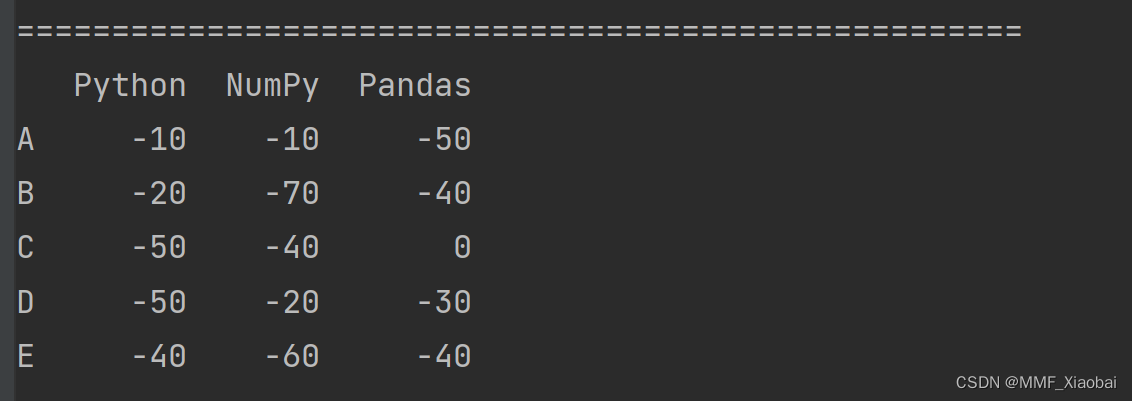
6. transform()函数【既支持Series,也支持DataFrame】
transform()是pandas中的转换函数,对DataFrame执行传入的函数后返回一个相同形状的DataFrame
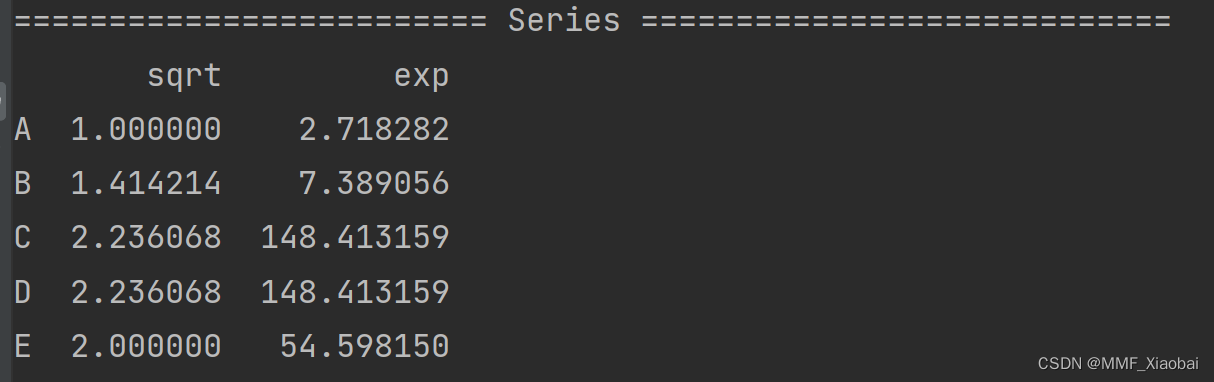
df2['Python'].transform([np.sqrt, np.exp])
def convert(x):
if x.mean() > 5:
return x * 10
else:
return x * (-10)
print(df2.transform(convert)) # 对列进行操作
# print(df2.transform(convert, axis=1)) # 对行进行操作



















 439
439

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











