




2D卷积和3D卷积
Note:在讨论卷积核的维度的时候,是不把channel维加进去的(或者说,卷积核的维度指的的进行滑窗操作的维度,而滑窗操作是不在channel维度上进行的,因为每个channel共享同一个滑窗位置, 但每个channel上的卷积核权重是独立的)。所以2D conv的卷积核其实是(c, k_h, k_w),3D conv的卷积核就是(c, k_d, k_h, k_w),其中k_d就是多出来的第三维,根据具体应用,在视频中就是时间维,在CT图像中就是层数维。
- 2D 卷积
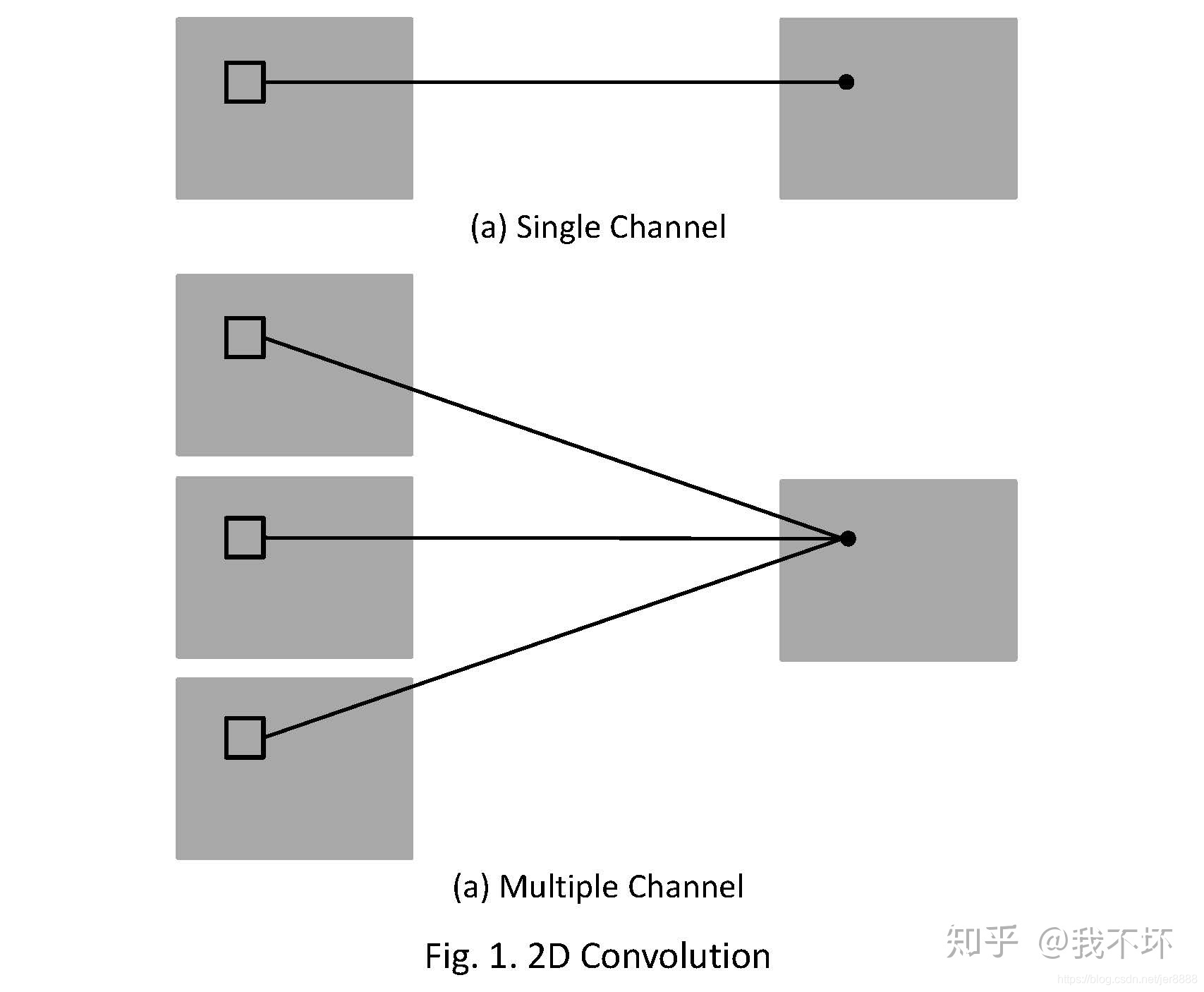
2D卷积操作如图1所示,为了解释的更清楚,分别展示了单通道和多通道的操作。且为了画图方便,假定只有1个filter,即输出图像只有一个chanel。其中,针对单通道,输入图像的channel为1,即输入大小为(1, height, weight),卷积核尺寸为 (1, k_h, k_w),卷积核在输入图像上的的空间维度(即(height, width)两维)上进行进行滑窗操作,每次滑窗和 (k_h, k_w) 窗口内的values进行卷积操作(现在都用相关操作取代),得到输出图像中的一个value。
针对多通道,假定输入图像的channel为3,即输入大小为(3, height, weight),卷积核尺寸为 (3, k_h, k_w), 卷积核在输入图像上的的空间维度(即(height, width)两维)上进行进行滑窗操作,每次滑窗与3个channels上的 (k_h, k_w) 窗口内的所有的values进行相关操作,得到输出图像中的一个value。
- 3D 卷积
3D卷积操作如图2所示,同样分为单通道和多通道,且只使用一个filter,输出一个channel。其中,针对单通道,与2D卷积不同之处在于,输入图像多了一个 depth 维度,故输入大小为(1, depth, height, width),卷积核也多了一个k_d维度,因
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1859
1859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









