







 该专栏为热销专栏榜 第15名
该专栏为热销专栏榜 第15名一、本文介绍
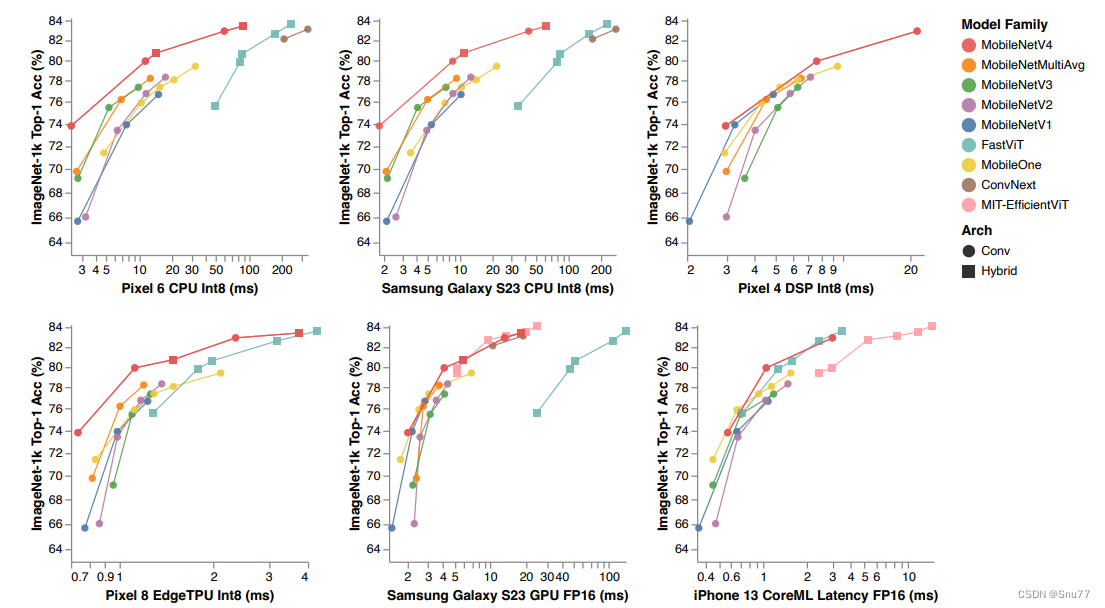
本文给大家带来的最新改进机制是利用MobileNetV4的UIB模块二次创新C3k2,其中UIB模块来自2024.5月发布的MobileNetV4网络,其是一种高度优化的神经网络架构,专为移动设备设计。它最新的改动总结主要有两点,采用了通用反向瓶颈(UIB,也就是本文利用的结构)和针对移动加速器优化的Mobile MQA注意力模块(一种全新的注意力机制)。我将其用于C3k2的二次创新在V11n上参数量为250W),计算量为6.0GFLOPs,非常适用于想要轻量化网络模型的读者来使用,同时本文结构为本专栏独家创新。
欢迎大家订阅我的专栏一起学习YOLO!
目录
二、原理介绍

官方论文地址: 官方论文地址点击此处即可跳转
官方代码地址: 官方代码地址点击此处即可跳转

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











