







 本文深入探讨MSDA(多尺度空洞注意力)机制,其在YOLOv9中提升模型性能,尤其在小目标检测中显著提高mAP。通过线性投影和多尺度SWDA,MSDA实现多尺度特征提取和稀疏性利用,减少了计算冗余。文章提供详细的手动添加MSDA模块教程,并分享了训练过程和yaml配置文件。
本文深入探讨MSDA(多尺度空洞注意力)机制,其在YOLOv9中提升模型性能,尤其在小目标检测中显著提高mAP。通过线性投影和多尺度SWDA,MSDA实现多尺度特征提取和稀疏性利用,减少了计算冗余。文章提供详细的手动添加MSDA模块教程,并分享了训练过程和yaml配置文件。
一、本文介绍
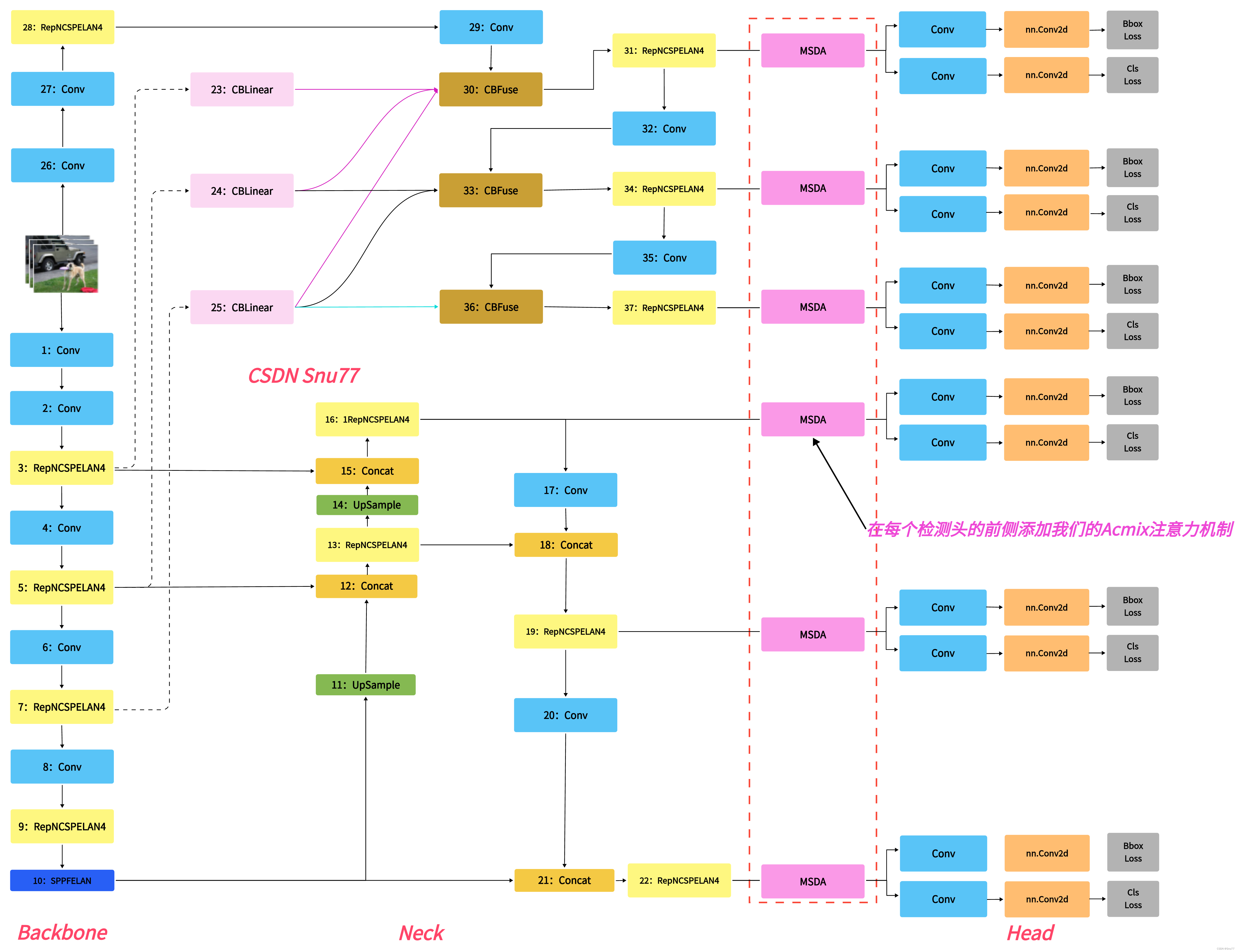
本文给大家带来的改进机制是MSDA(多尺度空洞注意力)发表于今年的中科院一区(算是国内计算机领域的最高期刊了),其全称是"DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition"。MSDA的主要思想是通过线性投影得到特征图X的相应查询、键和值。然后,将特征图的通道分成n个不同的头部,并在不同的头部中以不同的扩张率执行多尺度SWDA来提高模型的处理效率和检测精度。亲测在小目标检测和大尺度目标检测的数据集上都有大幅度的涨点效果(mAP直接涨了大概有0.06左右)。最后本文会手把手教你添加MSDA模块到网络结构中。
目录
二、MSDA框架原理

论文地址:官方论文地址点击即可跳转
代码地址:官方代码地址点击即可跳转

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 9632
9632

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











