







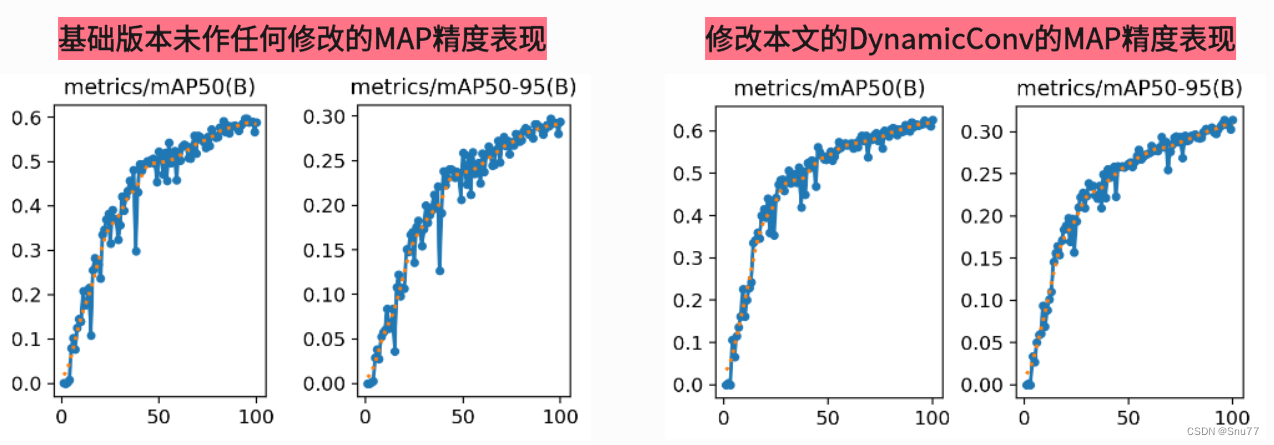
 本文介绍了CVPR2024的最新技术DynamicConv,它增加了网络参数而几乎不增加FLOPs。动态卷积通过根据输入样本动态选择卷积核来提高模型的参数效率和适应性,特别适合资源有限的环境。文中提供了详细的原理介绍、核心代码和手把手的添加教程,包括修改步骤和成功的运行截图。
本文介绍了CVPR2024的最新技术DynamicConv,它增加了网络参数而几乎不增加FLOPs。动态卷积通过根据输入样本动态选择卷积核来提高模型的参数效率和适应性,特别适合资源有限的环境。文中提供了详细的原理介绍、核心代码和手把手的添加教程,包括修改步骤和成功的运行截图。
一、本文介绍
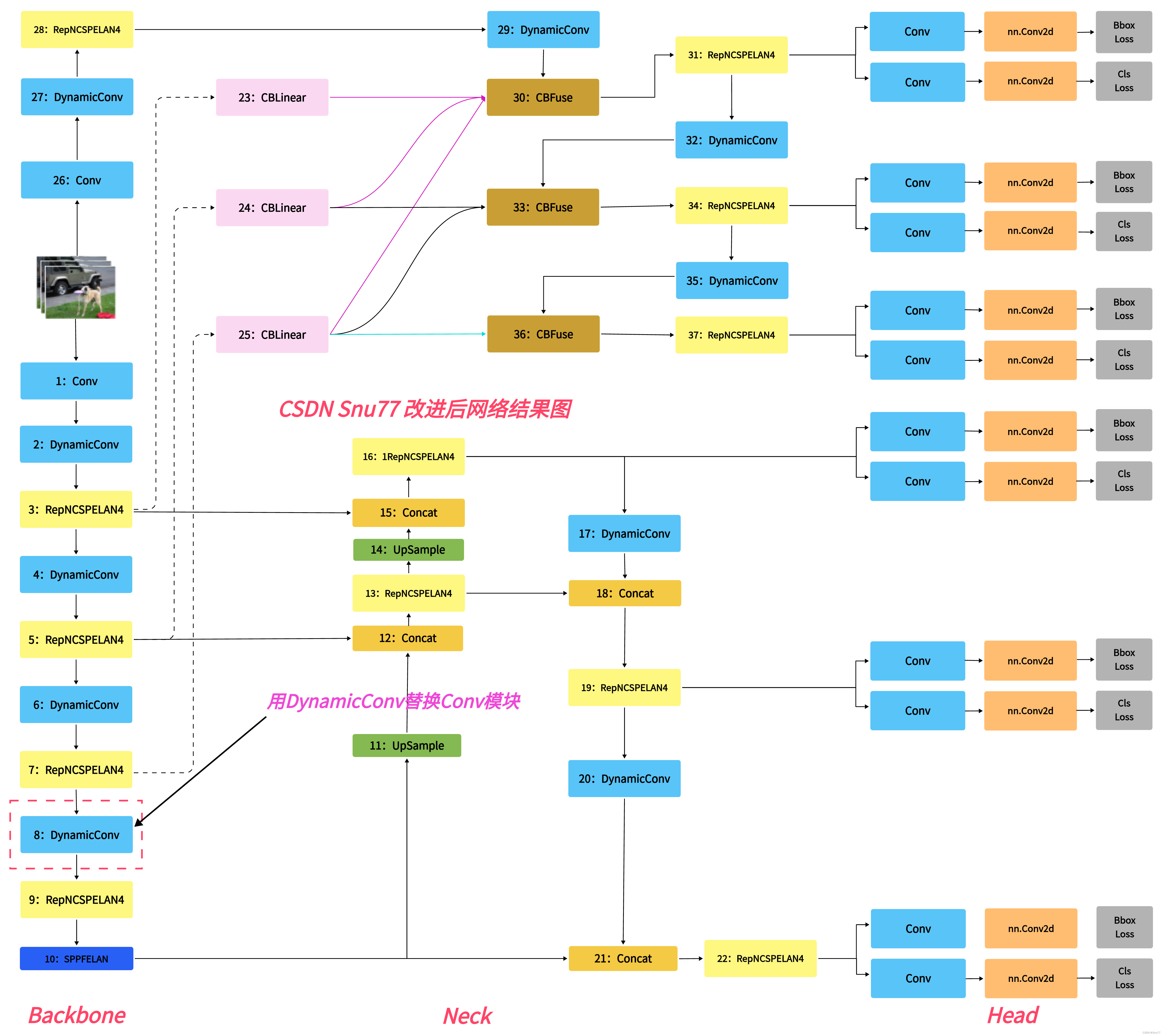
本文给大家带来的改进机制是CVPR2024的最新改进机制DynamicConv其是CVPR2024的最新改进机制,这个论文中介绍了一个名为ParameterNet的新型设计原则,它旨在在大规模视觉预训练模型中增加参数数量,同时尽量不增加浮点运算(FLOPs),所以本文的DynamicConv被提出来了,使得网络在保持低FLOPs的同时增加参数量,从而允许这些网络从大规模视觉预训练中获益,本文内容包含详细教程 + 代码 + 原理介绍。
欢迎大家订阅我的专栏一起学习YOLO!
目录
4.2 DynamicConv的yaml文件(仔细看这个否则会报错)
二、原理介绍

官方论文地址: 官方论文地址点击此处即可跳转
官方代码地址:

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 28
28




 到【灌水乐园】发言
到【灌水乐园】发言









