







 本文介绍了将Haar小波的下采样HWD应用于YOLOv9,以替代传统的卷积下采样,以此降低模型参数和计算量。实验证明,这种方法能显著减少参数量和GFLOPs,并提供了详细的修改步骤和训练记录。
本文介绍了将Haar小波的下采样HWD应用于YOLOv9,以替代传统的卷积下采样,以此降低模型参数和计算量。实验证明,这种方法能显著减少参数量和GFLOPs,并提供了详细的修改步骤和训练记录。
一、本文介绍
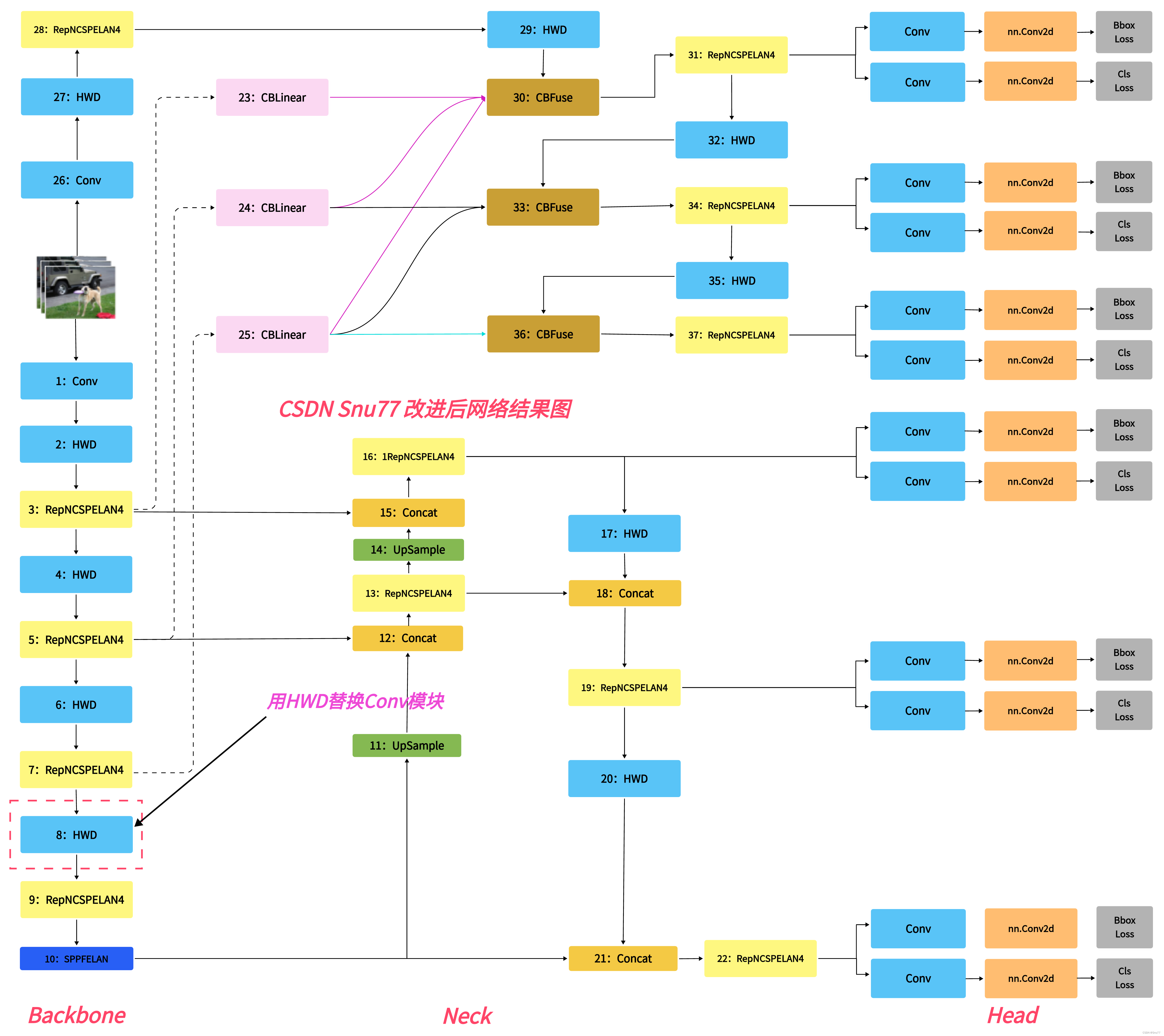
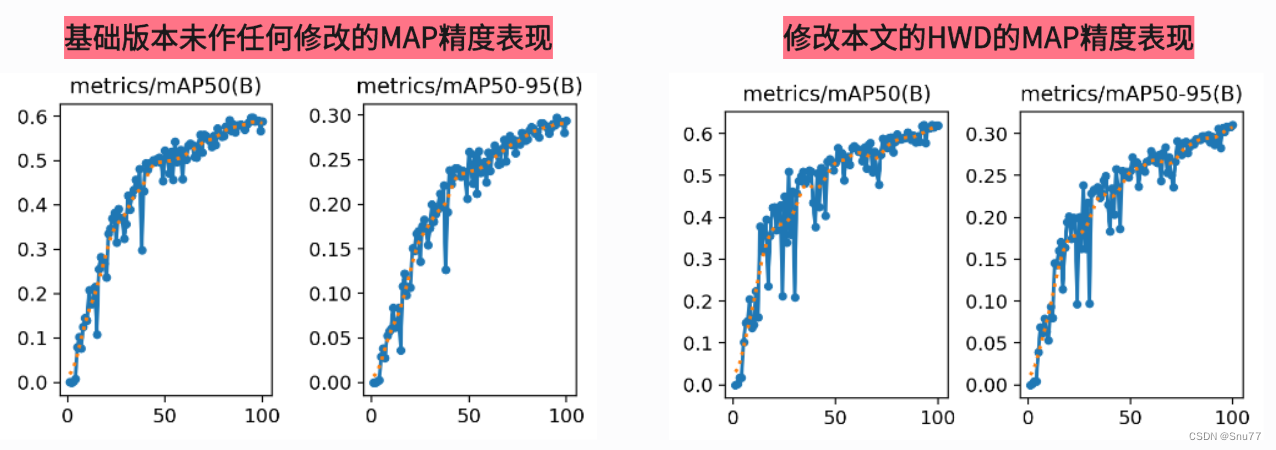
本文给大家带来的改进机制是Haar 小波的下采样HWD替换传统下采样(改变YOLO传统的Conv下采样)在小波变换中,Haar小波作为一种基本的小波函数,用于将图像数据分解为多个层次的近似和细节信息,这是一种多分辨率的分析方法。我将其用在YOLOv9上其明显降低参数和GFLOPs在V9上使用该机制后参数量为530W计算量GFLOPs为240(均有大幅度下降),欢迎大家订阅本专栏,本专栏每周更新3-5篇最新机制,更有包含我所有改进的文件和交流群提供给大家。
欢迎大家订阅我的专栏一起学习YOLO!
目录
二、原理介绍
官方论文地址:官方论文地址点击此处即可跳转(论文需要花钱此论文)
官方代码地址:官方代码地址点击此处即可跳转
论文介绍了一种基于Haar小波变换的图像压缩方法及其压缩图像质量的评估方法。下面是对论文内容的详细分析:
主要内容和方法
1. Haar小波变换的介绍:
- Haar小波是最简单的小波形式之一,具有易于计算和实现的优点。

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 4941
4941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











