







 本文详细介绍了CLLAHead,一种用于YOLOv5的独家目标检测头,旨在提升复杂场景下的目标识别和定位。核心思想包括分布焦点损失和注意力机制,具有较少的参数量。文章手把手教学如何添加CLLAHead,并提供相关代码和运行记录,适合深度学习和计算机视觉爱好者参考学习。
本文详细介绍了CLLAHead,一种用于YOLOv5的独家目标检测头,旨在提升复杂场景下的目标识别和定位。核心思想包括分布焦点损失和注意力机制,具有较少的参数量。文章手把手教学如何添加CLLAHead,并提供相关代码和运行记录,适合深度学习和计算机视觉爱好者参考学习。
一、本文介绍
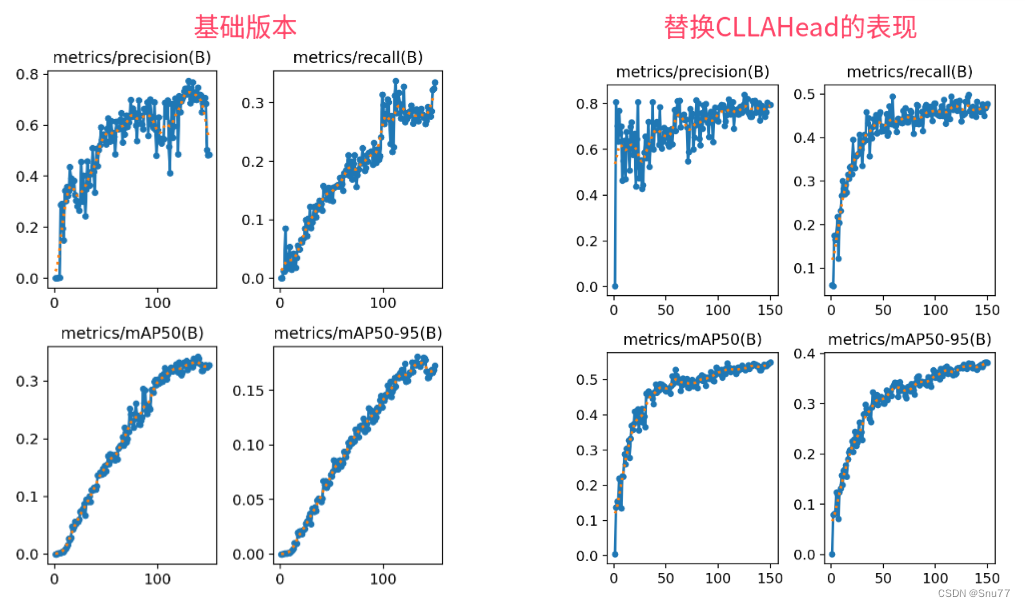
本文给大家带来的改进机制是CLLAHead,该检测头为我独家全网首发,该检测头通过多层次的特征提取和整合,利用分布焦点损失损失函数和一种注意力机制,来提高对图像中目标的识别和定位能力。这种结构特别适合于处理复杂的图像场景,其中包含多个不同大小和形状的目标,同时该检测头的参数量非常微量(之前发的一个检测头大家说参数量大,这次发一个参数量小的)。同时欢迎大家订阅本专栏,本专栏每周更新3-5篇最新机制,更有包含我所有改进的文件和交流群提供给大家。
欢迎大家订阅我的专栏一起学习YOLO!
目录
二、CLLAHead的核心思想
独家创新~
三、CLLAHead的核心代码
import torch
import torch.nn as nn
from utils.general import check_version
__all__ = ['CLLAHead', 'Segment_CLLA']
def autopad(k, p=None, d=1): # kernel, padding, dilation
# Pad to 'same' shape outputs
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
# Standard c
 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











