







 本文介绍了ACmix,一种结合自注意力和卷积运算的模型,通过1x1卷积降低计算成本,提高目标检测模型YOLOv5的性能。ACmix通过特征分解、运算共享和融合,实现自注意力和卷积的优势结合,详细解析了ACmix的框架原理,包括自注意力和卷积的整合以及运算分解与重构。此外,还提供了添加ACmix到YOLOv5的步骤和不同配置的yaml文件。
本文介绍了ACmix,一种结合自注意力和卷积运算的模型,通过1x1卷积降低计算成本,提高目标检测模型YOLOv5的性能。ACmix通过特征分解、运算共享和融合,实现自注意力和卷积的优势结合,详细解析了ACmix的框架原理,包括自注意力和卷积的整合以及运算分解与重构。此外,还提供了添加ACmix到YOLOv5的步骤和不同配置的yaml文件。
一、本文介绍
本文给大家带来的改进机制是ACmix自注意力机制的改进版本,它的核心思想是,传统卷积操作和自注意力模块的大部分计算都可以通过1x1的卷积来实现。ACmix首先使用1x1卷积对输入特征图进行投影,生成一组中间特征,然后根据不同的范式,即自注意力和卷积方式,分别重用和聚合这些中间特征。这样,ACmix既能利用自注意力的全局感知能力,又能通过卷积捕获局部特征,从而在保持较低计算成本的同时,提高模型的性能。同时在开始讲解之前推荐一下我的专栏,本专栏的内容支持(分类、检测、分割、追踪、关键点检测),专栏目前为限时折扣,欢迎大家订阅本专栏,本专栏每周更新3-5篇最新机制,更有包含我所有改进的文件和交流群提供给大家。
推荐指数:⭐⭐⭐⭐
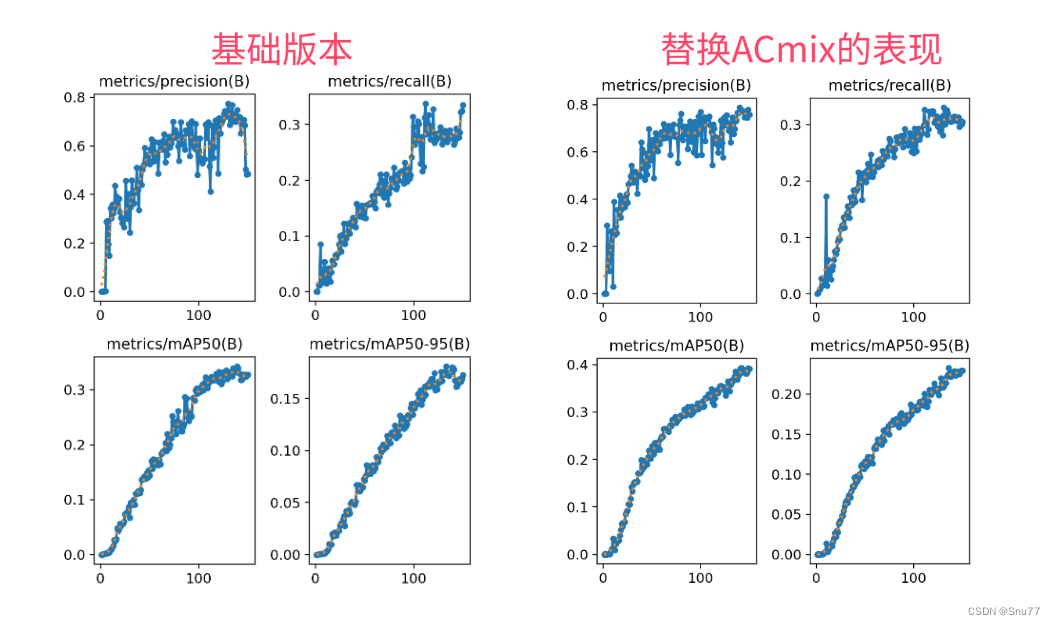
涨点效果:⭐⭐⭐⭐
目录

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 4832
4832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











