







 该专栏为热销专栏榜 第6名
该专栏为热销专栏榜 第6名 本文介绍了YOLOv8改进中使用的ODConv(全维度动态卷积),这是一种减少计算量、提升检测精度的卷积模块。ODConv通过多维动态注意力机制,实现了在空间大小、输入通道数、输出通道数和卷积核数量四个维度上的动态调整,从而增强网络的灵活性。文章包含ODConv的基本原理、代码实现和在模型中的应用步骤,适合目标检测领域的研究者和开发者参考。
本文介绍了YOLOv8改进中使用的ODConv(全维度动态卷积),这是一种减少计算量、提升检测精度的卷积模块。ODConv通过多维动态注意力机制,实现了在空间大小、输入通道数、输出通道数和卷积核数量四个维度上的动态调整,从而增强网络的灵活性。文章包含ODConv的基本原理、代码实现和在模型中的应用步骤,适合目标检测领域的研究者和开发者参考。
一、本文介绍
这篇文章给大家带来的是发表于2022年的ODConv(Omni-Dimensional Dynamic Convolution)中文名字全维度动态卷积,该卷积可以即插即用,可以直接替换网络结构中的任何一个卷积模块,在本文的末尾提供可以直接替换卷积模块的ODConv,添加ODConv模块的C2f和Bottleneck(配合教程将代码复制粘贴到你自己的代码中即可运行)给大家,该卷积模块主要具有更小的计算量和更高的精度,其中添加ODConv模块的网络(只替换了一处C2f中的卷积)参数量由8.9GFLOPS减小到8.8GFLOPS,精度也有提高->下面的图片是精度的对比(因为训练成本我只是用了相同的数据集100张图片除了修改了ODConv以后其他配置都相同下面是效果对比图左面为修改版本,右面为基础版本)
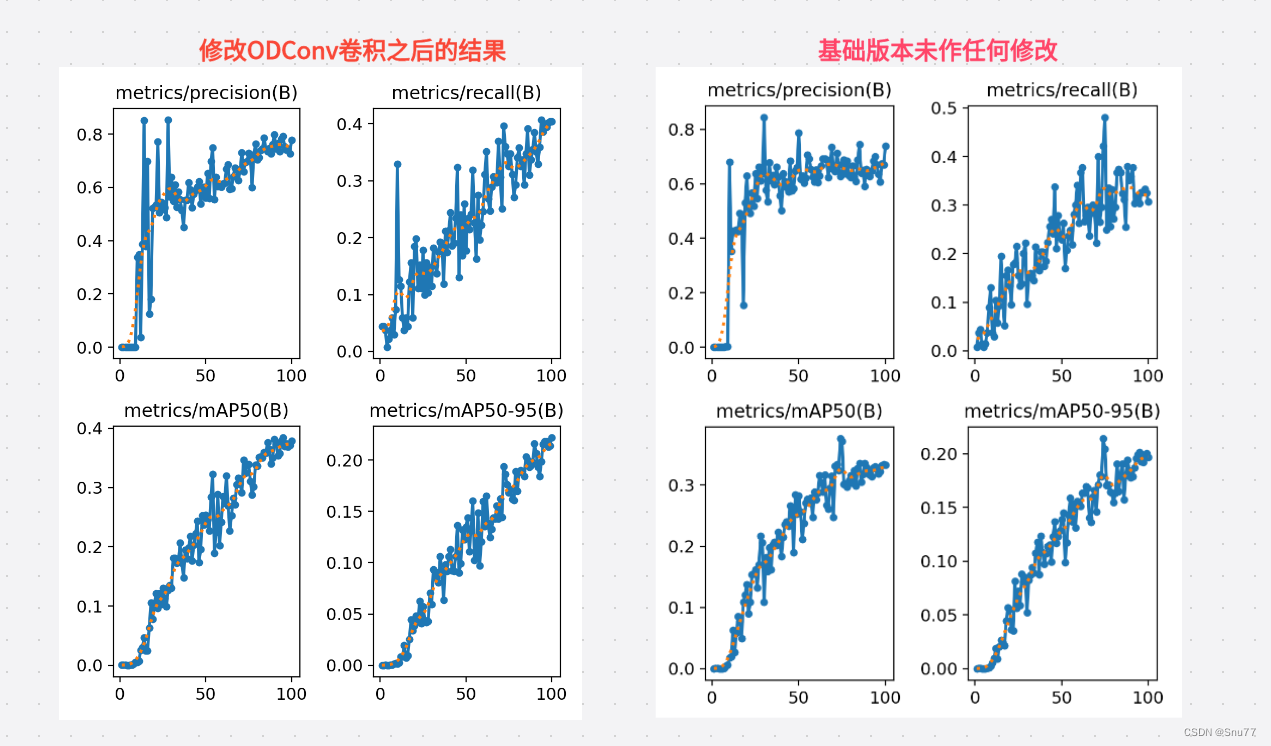
适用场景:轻量化、所有检测目标时均可使用进行有效涨点
目录
二、基本原理介绍

论文地址:论文地址点击即可跳转阅读
代码地址:文末提供复制粘贴的代码块

大家估计只是冲着代码来看,估计很少想要看其原理的,所以我们这里

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 849
849







 到【灌水乐园】发言
到【灌水乐园】发言









