







一、本文介绍
这篇文章主要给大家讲解如何在多个位置替换可变形卷积,它有三个版本分别是DCNv1、DCNv2、DCNv3,在本篇博文中会分别进行介绍同时进行对比,通过本文你可以学会在YOLOv8中各个位置添加可变形卷积包括(DCNv1、DCNv2、DCNv3),可替换的位置包括->替换C2f中的卷积、DarknetBottleneck中的卷积、主干网络(Backbone)中的卷积等多个位置,本文通过实战的角度进行分析,利用二分类数据集检测飞机为案例,训练结果,通过分析mAP、Loss、Recall等评估指标评估变形卷积的效果,在讲解的过程中有一部分知识点内容来自于论文,也有一部分是我个人的总结内容。
适用对象->适合魔改YOLOv8尝试多位置修改发表论文的用户
适用检测目标->各种类型的目标检测对象
目录
二、概念介绍
首先我们先来介绍一个大的概念DCN全称为Deformable Convolutional Networks,翻译过来就是可变形卷积的意思,其是一种用于目标检测和图像分割的卷积神经网络模块,通过引入可变形卷积操作来提升模型对目标形变的建模能力。
什么是可变形卷积?我们看下图来看一下就了解了。
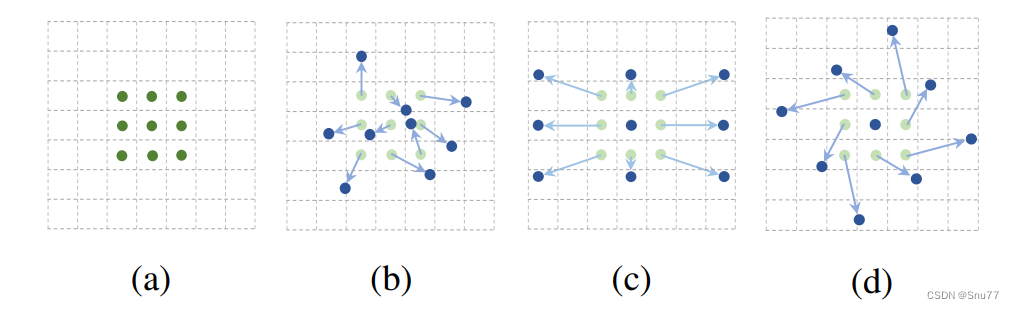
上图中展示了标准卷积和可变形卷积中的采样位置。在标准卷积(a)中,采样位置按照规则的网格形式排列(绿色点)。这意味着卷积核在进行卷积操作时,会在输入特征图的规则网格位置上进行采样。
而在可变形卷积(b)中,采样位置是通过引入偏移量进行变形的(深蓝色点),并用增强的偏移量(浅蓝色箭头)进行

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 3918
3918










 到【灌水乐园】发言
到【灌水乐园】发言









