 SimCLR: 简单框架实现视觉表征对比学习
SimCLR: 简单框架实现视觉表征对比学习





论文:A Simple Framework for Contrastive Learning of Visual Representations
论文链接:https://arxiv.org/pdf/2002.05709.pdf
Lecun在2020的AAAI上表示看好自监督学习,在近两年,self-supervised learning的成果也越来越多,如MoCo,CPC等等。Hinton组的这篇SimCLR,比之前的SOTA方法在InageNet的top1的accuracy上提高了7个百分点,虽然有人说这篇文章属于暴力美学,但还是值得一读的。
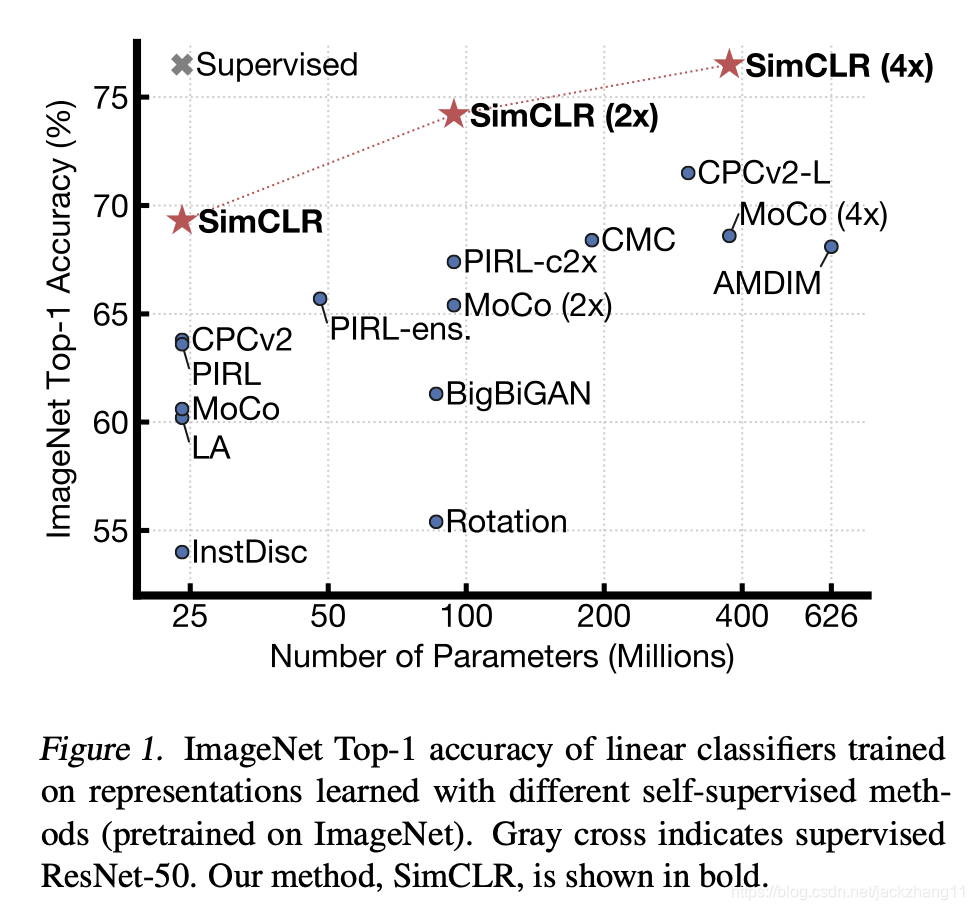
在参数相同的情况下,ImageNet的top1 accuracy高于其他SOTA方法7个百分点及以上,更加接近supervised learning。
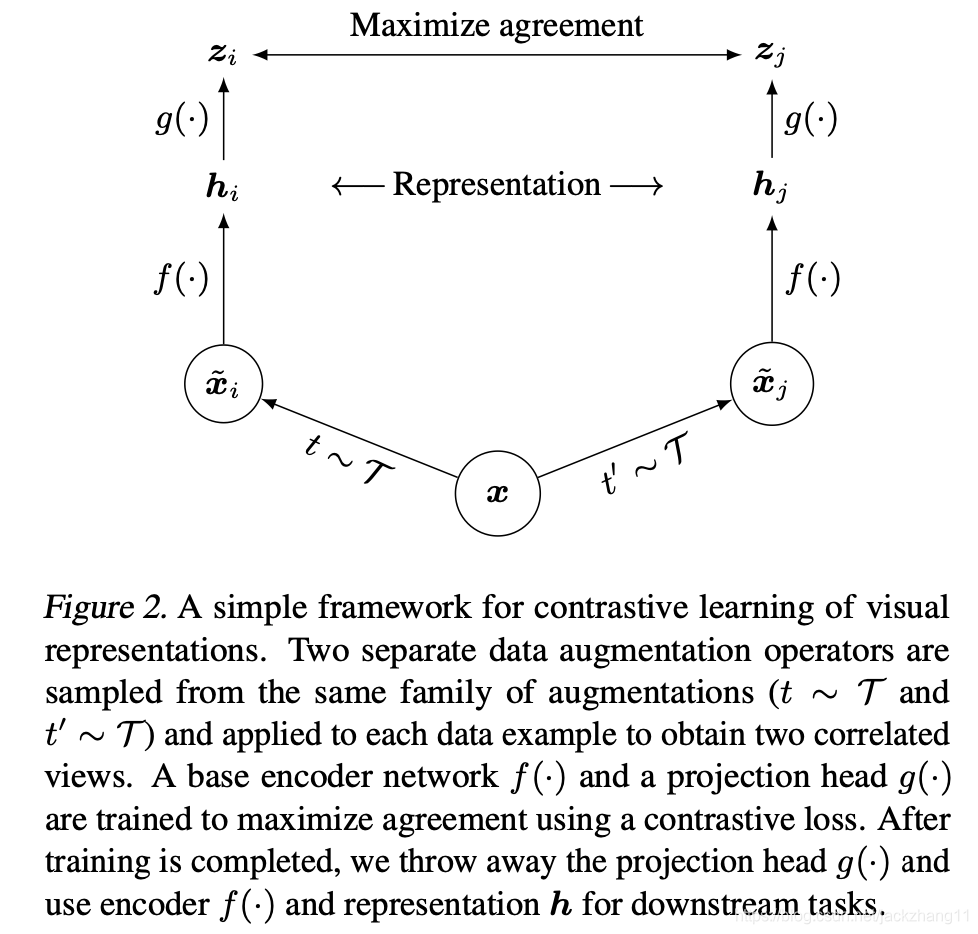
网络结构如上图:
(1)对于样本xxx,首先进行data augmentation(本文的三种augmentation分别为:随机裁剪并resize,color distortion以及Gaussian Blur),经过两种不同的操作得到xi~\widetilde{x_{i}}xi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2189
2189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









