






 本文提出SimCLR这一简单的视觉表征对比学习框架,无需专门架构或内存库。研究表明,数据增强组合对定义预测任务关键,对比学习比监督学习需更强增强;引入非线性投影头可提高表示质量;对比学习受益于更大批规模和更长训练时间,该框架优于以往自监督和半监督学习方法。
本文提出SimCLR这一简单的视觉表征对比学习框架,无需专门架构或内存库。研究表明,数据增强组合对定义预测任务关键,对比学习比监督学习需更强增强;引入非线性投影头可提高表示质量;对比学习受益于更大批规模和更长训练时间,该框架优于以往自监督和半监督学习方法。
文章汇总
文章提出了一个简易但高效的对比学习框架,并且发现了一些无监督对比学习中的规律。
流程:
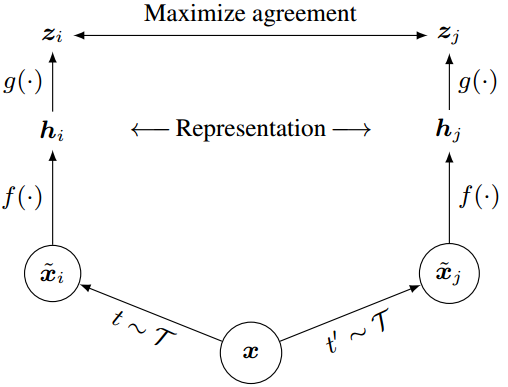
1:对一张图像做随机的增强,产生两张图像
2:这个两张增强后的图像送到网络里,产生两个特征向量
3:经过MLP(也就是全连接网络),也就是投影操作
,产生
4:用于计算Contrastive loss
5:我们想要的Representation是,最终的特征提取器是
损失函数设计
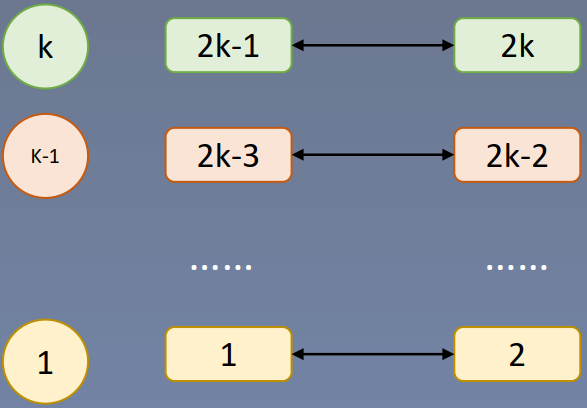
一个batch里面有k张图片,每个图片经过不同的2次数据增强,得到一个正样本对。
同颜色的(说明来自同一个原始样本)就拉近他们之间的距离,比如说1,2,不同颜色的就距离推远。
损失函数如下
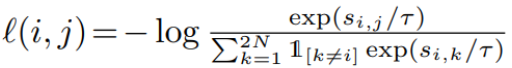
关于Projection head
Projection head我认为是该文章最新颖的创新点
投影头即流程图中的,文章使用的是
可以从实验中看出来,作者更推荐非线性的投影头。
结合论文,个人认为投影头的添加之所以可以涨点,是因为可以删除可能对下游任务有用的信息,例如对象的颜色或方向。而在训练时,通过添加非线性的
来提升训练的难度,因此让投影头之前的h形成和保持更多的信息。
需要注意的是,的添加是不利于特征的表示,所以在训练完之后的预测结果是不需要添加
的,文章也提及到了这个注意点。

如图所示,的视觉表示是不如,甚至是远远不如
的。
文章发现的规律
1.单一的某种数据增强并没有很大效果。
2.组合的数据增强中,随机裁剪+随机颜色表现最突出(random cropping and random color distortion),先裁剪,后颜色失真。
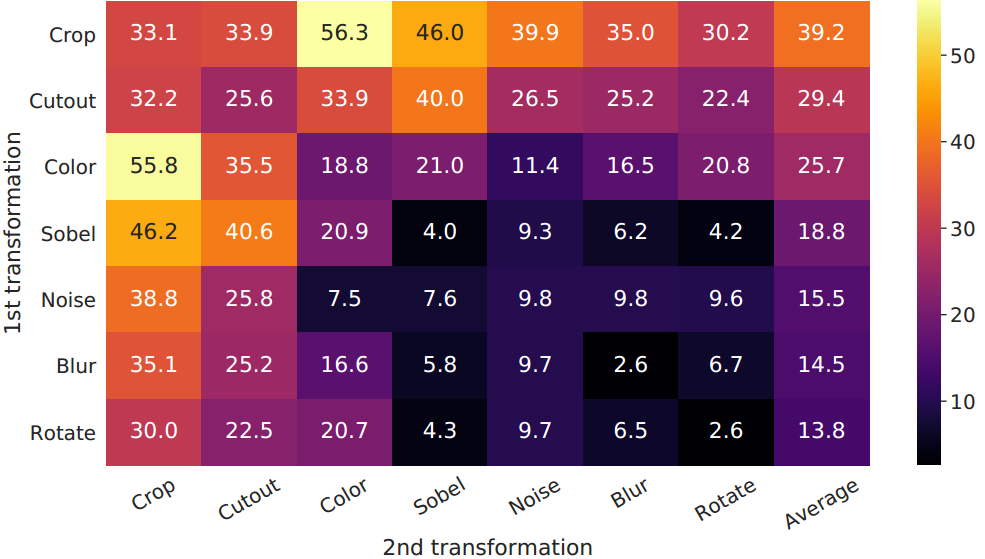
3.对比学习比监督学习需要更强的数据增强

4.无监督对比学习比纯粹的监督学习从更大的模型中获益更多
5.非线性投影头的添加提高了前一层的表示质量
摘要
本文提出了SimCLR:一个简单的视觉表征对比学习框架。我们简化了最近提出的对比自监督学习算法,而不需要专门的架构或内存库。为了理解是什么使对比预测任务能够学习有用的表示,我们系统地研究了我们框架的主要组成部分。我们表明:
(1)数据增强的组成在定义有效的预测任务中起着关键作用;
(2)在表征和对比损失之间引入可学习的非线性转换,大大提高了学习表征的质量;
(3)与监督学习相比,对比学习受益于更大的批处理规模和更多的训练步骤。
通过结合这些发现,我们能够大大优于以前在ImageNet上进行自监督和半监督学习的方法。在SimCLR学习的自监督表示上训练的线性分类器达到了76.5%的top-1准确率,这比以前的技术水平相对提高了7%,与监督的ResNet-50的性能相当。当只对1%的标签进行微调时,我们达到了85.8%的前5名准确率,比AlexNet少100倍的标签表现更好。1
1. 介绍
在没有人类监督的情况下学习有效的视觉表征是一个长期存在的问题。大多数主流方法可分为两类:生成式或判别式。生成式方法学习在输入空间中生成或以其他方式建模像素(Hinton等人,2006;Kingma & Welling, 2013;Goodfellow et al, 2014)。
然而,像素级生成在计算上是昂贵的,并且对于表示学习可能不是必需的。判别方法使用类似于用于监督学习的目标函数来学习表征,但训练网络执行文本预训练任务,其中输入和标签都来自未标记的数据集。许多这样的方法都依赖于启发式来设计文本预训练任务(Doersch等人,2015;Zhang等,2016;Noroozi & Favaro, 2016;Gidaris等人,2018),这可能会限制学习表征的一般性。基于潜在空间中对比学习的判别方法最近显示出很大的前景,取得了最先进的结果(Hadsell等人,2006;Dosovitskiy等,2014;Oord等人,2018;Bachman et al, 2019)。
在这项工作中,我们为视觉表征的对比学习引入了一个简单的框架,我们称之为SimCLR。SimCLR不仅优于以前的工作(图1),而且更简单,不需要专门的架构(Bachman et al, 2019;hsamnaff等人,2019)也不是记忆库(Wu等人,2018;田等人,2019;他等人,2019;Misra & van der Maaten, 2019)。
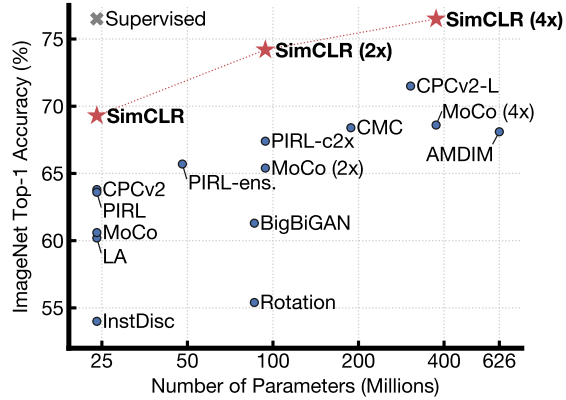
图1所示。用不同的自监督方法(在ImageNet上预训练)学习表征训练的线性分类器的ImageNet Top-1精度。灰色叉表示有监督的ResNet-50。我们的方法SimCLR以粗体显示。
为了理解是什么促成了良好的对比表征学习,我们系统地研究了框架的主要组成部分,并表明:
•多个数据增强操作的组合对于定义产生有效表示的对比预测任务至关重要。此外,与有监督学习相比,无监督对比学习受益于更强的数据增强。
•在表示和对比损失之间引入可学习的非线性变换(Projection head),大大提高了学习到的表示的质量。
•具有对比交叉熵损失的表示学习受益于规范化嵌入和适当调整的温度参数。
•与监督学习相比,对比学习受益于更大的批处理规模和更长的训练时间。与监督式学习一样,对比式学习也受益于更深入、更广泛的网络。
我们结合这些发现,在ImageNet ILSVRC-2012上实现了自监督和半监督学习的新技术(Russakovsky et al ., 2015)。在线性评估方案下,SimCLR达到了76.5%的顶级1精度,比以前的最先进技术相对提高了7% (hsamnaff et al, 2019)。当仅使用1%的ImageNet标签进行微调时,SimCLR达到85.8%的前5准确率,相对提高10% (hsamnaff et al, 2019)。当对其他自然图像分类数据集进行微调时,SimCLR在12个数据集中的10个上的表现与强监督基线相当或更好(Kornblith等人,2019)。
2. 方法
2.1. 对比学习框架
通过一个视频理解
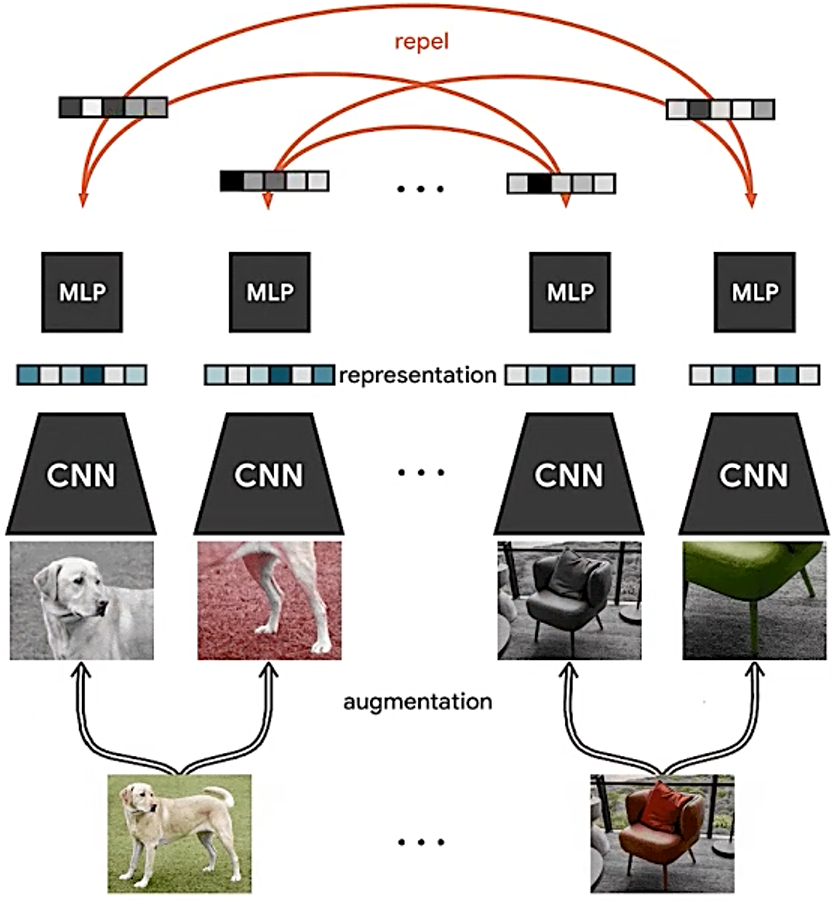
受最近的对比学习算法的启发(参见第7节的概述),SimCLR通过潜在空间中的对比损失来最大化相同数据示例的不同增强视图之间的一致性来学习表示。如图2所示,该框架由以下四个主要组件组成。
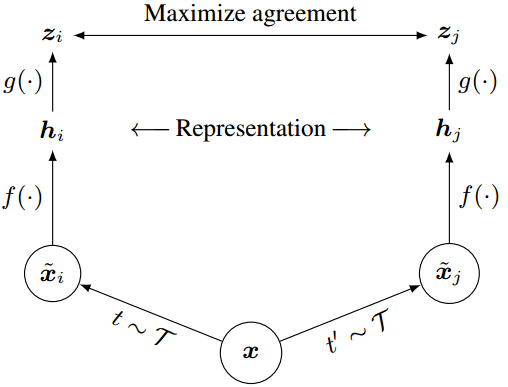
图2。视觉表征对比学习的简单框架。两个独立的数据增广算子从相同的增广族()中采样,并应用于每个数据示例以获得两个相关视图。一个基本编码器网络f(·)和一个投影头g(·)被训练来使用对比损失最大化一致性。训练完成后,我们扔掉投影头g(·),使用编码器f(·)和表示h来完成下游任务。
•一个随机数据增强模块,它将任意给定的数据样本随机变换为同一样本的两个相关视图,表示为,我们将其视为正对。在这项工作中,我们依次应用三种简单的增强:随机裁剪,然后将大小调整回原始大小,随机颜色失真和随机高斯模糊。如第3节所示,随机裁剪和颜色失真的结合对于获得良好的性能至关重要。
•一个神经网络基础编码器f(·),从增强的数据示例中提取表示向量。我们的框架允许在没有任何限制的情况下选择各种网络架构。我们选择简单,采用常用的ResNet (He et al, 2016)得到
为平均池化层后的输出。
•一个小的神经网络投影头g(·),它将表示映射到应用对比损失的空间。我们使用具有一个隐藏层的MLP得到,其中σ是一个ReLU非线性。如第4节所示,我们发现将对比损失定义在
上而不是
上是有益的。
•为对比预测任务定义的对比损失函数。给定一个集合,其中包含一对正的例子
,对比预测任务的目的是在给定的
中识别
中的
。
我们随机抽取一个包含N个样本的小批样本,并在从小批样本中得到的成对增广样本上定义对比预测任务,得到2N个数据点。我们不会明确地选取负面例子。相反,给定一个正对,类似于(Chen等人,2017),我们将minibatch中的其他2(N−1)个增强示例视为负示例。让表示
归一化u与v的点积(即余弦相似度)。然后对正对的例子
定义为
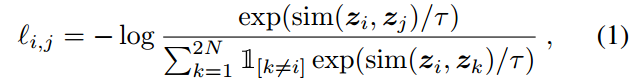
其中是在
时取值为1的指示函数,τ表示温度参数。最终损失是在所有正样本对上计算的,包括
小批量生产。在之前的工作中已经使用了这种损失(Sohn, 2016;Wu et al ., 2018;Oord等人,2018);为方便起见,我们称其为NT-Xent(归一化温度标度交叉熵损失)。

算法1总结了所提出的方法。
3. 对比表征学习的数据增强

图4。所研究的数据增广运算符的示例。每次增强都可以用一些内部参数(如旋转度、噪声水平)随机变换数据。请注意,我们只在消融中测试这些算子,用于训练模型的增强策略只包括随机裁剪(翻转和调整大小)、颜色失真和高斯模糊。(图片来源:Von.grzanka)
数据增强定义了预测性任务
虽然数据增强在有监督和无监督表示学习中都得到了广泛的应用(Krizhevsky等人,2012;hsamnaff等,2019;巴赫曼等人,2019),它还没有被认为是一种系统的方法来定义对比预测任务。许多现有的方法通过改变体系结构来定义对比预测任务。例如,Hjelm等人(2018);Bachman等人(2019)通过限制网络架构中的接受场来实现全局到局部的视图预测,而Oord等人(2018);hsamnaff等(2019)通过固定的图像分割过程和上下文聚合网络实现相邻视图预测。我们展示了可以通过对目标图像执行简单的随机裁剪(调整大小)来避免这种复杂性,这创建了一系列包含上述两个任务的预测任务,如图3所示。这种简单的设计选择方便地将预测任务与其他组件(如神经网络架构)解耦。通过扩展增广族并将其随机组合,可以定义更广泛的对比预测任务。

图3。实矩形是图像,虚线矩形是随机裁剪。通过随机裁剪图像,我们采样对比预测任务,包括全局到局部视图或相邻视图
预测。
3.1. 数据增强操作的组合对于学习良好的表示是至关重要的
文章发现:
1.单一的某种数据增强并没有很大效果
2.组合的数据增强中,随机裁剪+随机颜色表现最突出(random cropping and random color distortion),先裁剪,后颜色失真。
图5。线性评估(ImageNet top-1精度)在单个或组合数据增强下,仅应用于一个分支。对于除最后一列之外的所有列,对角线项对应于单个转换,而非对角线项对应于两个转换的组合(顺序应用)。最后一列反映了该行的平均值。
3.颜色失真为什么重要?如果没有颜色失真,仅仅靠直方图就能判断处两个图像是不是从一张图片crop的,即是不是同类。
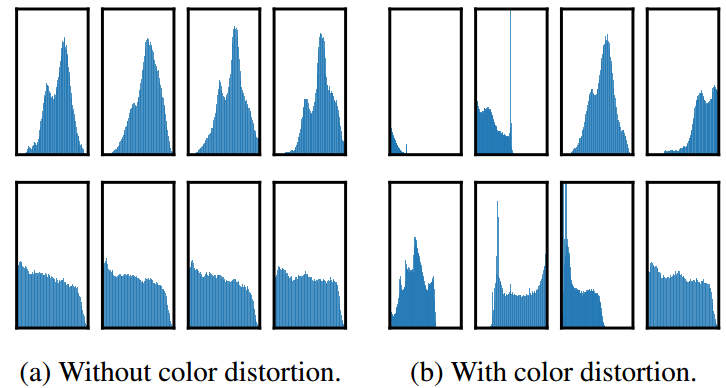
图6。两个不同图像(即两行)的不同作物的像素强度直方图(在所有通道上)。第一行的图像来自图4。所有的轴都有相同的范围。
3.2. 对比学习比监督学习需要更强的数据增强
一网友观点:这个我很认同,对于大而精确标注的数据集使用有监督方法,如果数据增强随意施加一大堆,可能效果并不好。
表1。在不同颜色失真强度(见附录A)和其他数据转换下,使用线性评估和监督ResNet-505的无监督ResNet-50的Top-1精度。强度1(+模糊)是我们默认的数据增强策略。
4. 编码器和头的体系结构
4.1. 无监督对比学习从更大的模型中获益更多
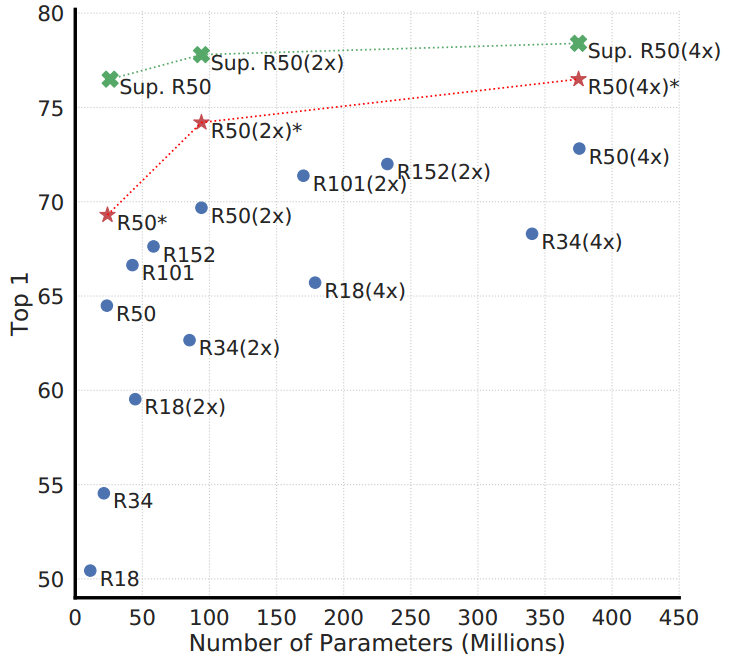
图7。不同深度和宽度模型的线性评价。蓝点的模型是我们训练了100个epoch的模型,红星的模型是我们训练了1000个epoch的模型,绿叉的模型是训练了90个epoch的ResNets模型(He et al, 2016)。
图7显示,增加深度和宽度都可以提高性能,这也许并不令人感到意外。虽然类似的发现也适用于监督学习(He et al, 2016),但我们发现随着模型大小的增加,监督模型和在无监督模型上训练的线性分类器之间的差距会缩小,这表明无监督学习从更大的模型中获得的好处比有监督模型更多。
4.2. 非线性投影头提高了前一层的表示质量
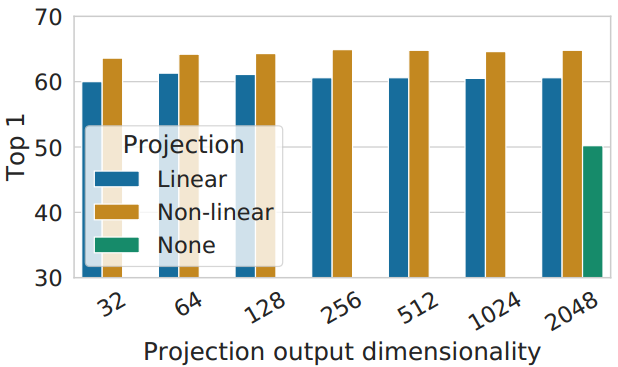
图8。具有不同投影头g(·)和z = g(h)的不同维度的表示的线性评估。h(投影前)在这里是2048维的。
然后我们研究了包含一个投影头的重要性,即g(h)。图8显示了对头部使用三种不同架构的线性评估结果:(1)完全相同映射;(2)线性投影,如之前几种方法所使用的(Wu et al, 2018);(3)带有一个额外隐藏层(和ReLU激活)的默认非线性投影,类似于Bachman等人(2019)。我们观察到,非线性投影比线性投影好(+3%),比没有投影好得多(>10%)。当使用投影头时,无论输出尺寸如何,都可以观察到类似的结果。此外,即使使用非线性投影,投影头之前的层h仍然比之后的层要好得多(>10%),这表明投影头之前的隐藏层比之后的层更好。
我们推测,在非线性投影之前使用表示的重要性是由于对比损失引起的信息损失。特别地,被训练成对数据变换不变量。因此,g可以删除可能对下游任务有用的信息,例如对象的颜色或方向。通过利用非线性变换
,可以在h中形成和保持更多的信息。为了验证这一假设,我们进行了实验,使用h或g(h)来学习预测预训练过程中应用的变换。在这里,我们设置
,具有相同的输入和输出维度(即2048)。表3显示h包含了更多关于应用的转换的信息,而g(h)丢失了信息。进一步的分析可以见附录B.4。
表3。在不同表示上训练额外mlp以预测转换应用的准确性。除了裁剪和颜色增强,我们还独立添加了旋转(其中一个为),高斯噪声和索贝尔滤波变换在最后三行预训练期间。h和g(h)具有相同的维数,即2048。
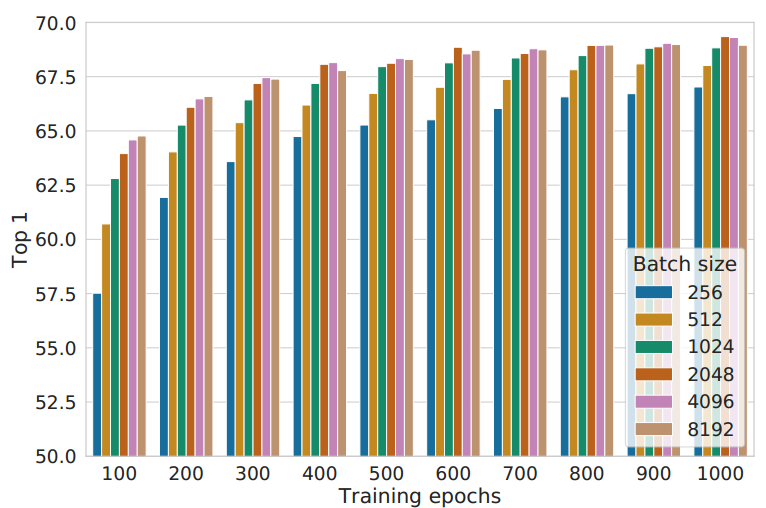
5. 损失函数和批大小
7. 相关工作
在小的变换下使图像的表现形式彼此一致的想法可以追溯到Becker & Hinton(1992)。我们通过利用数据增强、网络架构和对比损耗方面的最新进展来扩展它。类似的一致性想法,但用于类标签预测,已经在其他环境中进行了探索,如半监督学习(Xie等人,2019;Berthelot et al, 2019)。
手工制作的预训练文本任务
最近自我监督学习的复兴始于人为设计的借口任务,例如相对补丁预测(Doersch等人,2015),拼图游戏(Noroozi & Favaro, 2016),着色(Zhang等人,2016)和旋转预测(Gidaris等人,2018;Chen et al, 2019)。虽然通过更大的网络和更长的训练可以获得良好的结果(Kolesnikov等人,2019),但这些借口任务依赖于某种程度上的临时启发式,这限制了学习表征的一般性。
对比视觉表征学习
追溯到Hadsell等人(2006),这些方法通过对比正对和负对来学习表征。沿着这些思路,Dosovitskiy等人(2014)建议将每个实例视为由特征向量(以参数形式)表示的类。Wu等人(2018)提出使用内存库来存储实例类表示向量,这是最近几篇论文采用并扩展的方法(Zhuang等人,2019;田等人,2019;他等人,2019;Misra & van der Maaten, 2019)。其他工作探讨了使用批内样本进行负采样,而不是使用记忆库(Doersch & Zisserman, 2017;Ye et al, 2019;Ji et al, 2019)。
最近的文献试图将他们的方法的成功与潜在表征之间的相互信息最大化联系起来(Oord等人,2018;hsamnaff等,2019;Hjelm et al, 2018;Bachman et al, 2019)。然而,尚不清楚对比方法的成功是由相互信息决定的,还是由对比损失的具体形式决定的(Tschannen et al ., 2019)
我们注意到,我们框架的几乎所有单独组件都出现在以前的工作中,尽管具体的实例可能不同。我们的框架相对于以前的工作的优越性不是由任何单一的设计选择来解释的,而是由它们的组成来解释的。在附录C中,我们将我们的设计选择与之前的工作进行了全面的比较。
8. 结论
在这项工作中,我们提出了一个简单的框架及其实例对比视觉表征学习。我们仔细研究了它的组成部分,并展示了不同设计选择的效果。通过结合我们的发现,我们大大改进了以前的自监督、半监督和迁移学习方法。
我们的方法与ImageNet上的标准监督学习的不同之处在于数据增强的选择、网络末端非线性头部的使用以及损失函数。这个简单框架的力量表明,尽管最近人们对自我监督学习的兴趣激增,但它仍然被低估了。
参考资料
论文下载(ICML'2020)
https://arxiv.org/abs/2002.05709

代码地址
projection_head代码示例
from absl import flags
FLAGS = flags.FLAGS
def projection_head(hiddens, is_training, name='head_contrastive'):
"""Head for projecting hiddens fo contrastive loss."""
with tf.variable_scope(name, reuse=tf.AUTO_REUSE):
mid_dim = hiddens.shape[-1]
out_dim = FLAGS.proj_out_dim
hiddens_list = [hiddens]
if FLAGS.proj_head_mode == 'none':
pass # directly use the output hiddens as hiddens.
elif FLAGS.proj_head_mode == 'linear':
hiddens = linear_layer(
hiddens, is_training, out_dim,
use_bias=False, use_bn=True, name='l_0')
hiddens_list.append(hiddens)
elif FLAGS.proj_head_mode == 'nonlinear':
for j in range(FLAGS.num_proj_layers):
if j != FLAGS.num_proj_layers - 1:
# for the middle layers, use bias and relu for the output.
dim, bias_relu = mid_dim, True
else:
# for the final layer, neither bias nor relu is used.
dim, bias_relu = FLAGS.proj_out_dim, False
hiddens = linear_layer(
hiddens, is_training, dim,
use_bias=bias_relu, use_bn=True, name='nl_%d'%j)
hiddens = tf.nn.relu(hiddens) if bias_relu else hiddens
hiddens_list.append(hiddens)
else:
raise ValueError('Unknown head projection mode {}'.format(
FLAGS.proj_head_mode))
if FLAGS.train_mode == 'pretrain':
# take the projection head output during pre-training.
hiddens = hiddens_list[-1]
else:
# for checkpoint compatibility, whole projection head is built here.
# but you can select part of projection head during fine-tuning.
hiddens = hiddens_list[FLAGS.ft_proj_selector]
return hiddensclass Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.1):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return xSimCLR的nolinear 的MLP projection head 的 pytorch实现_non-linear projection head-优快云博客
import torch
import torch.nn as nn
class ProjectionHead(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(ProjectionHead, self).__init__()
self.layers = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, output_dim)
)
def forward(self, x):
return self.layers(x)# 假设我们有一个 Nx2048 的特征张量,其中N是批量大小
features = torch.randn(64, 2048)
# 创建投影头实例
projection_head = ProjectionHead(input_dim=2048, hidden_dim=2048, output_dim=2048)
# 将特征传递给投影头
projected_features = projection_head(features)


















 902
902

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











