







随着大语言模型LLM在各个场景的落地应用,RAG(Retrieval-Augmented Generation,检索增强生成)成为提升模型实用性和准确性的关键技术。企业利用 RAG 开发智能客服,提升响应效率;科研机构整合文献资源,加速知识挖掘;开发者则打造个性化助手,满足多样化需求。如何高效准确构建各自领域的知识库成为影响检索效果的关键,本文介绍基于DeepSeek + RAGFlow的知识库搭建实践,包括以下方面:
1. RAG基本概念
2. RAGFlow框架介绍
3. RAGFlow安装
4. DeepSeek+RAGFlow使用
5. 应用场景
【PS.下期整理Ubuntu环境下搭建知识库教程】
一、RAG基本概念
1. RAG核心原理
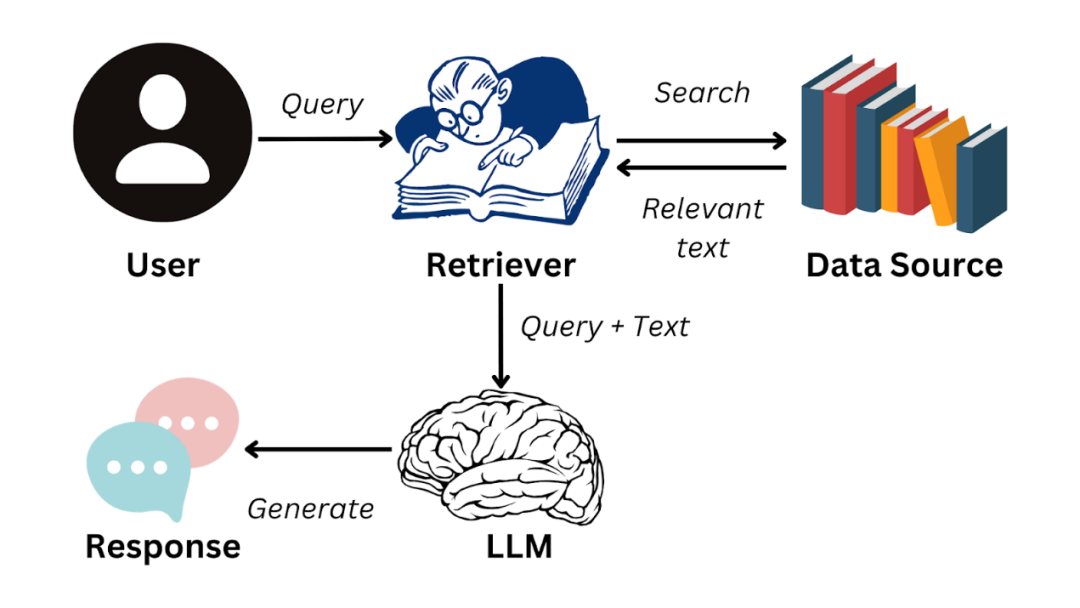
检索增强生成(Retrieval-Augmented Generation,RAG)是当前最受关注的大模型应用范式之一,其核心思想通过「知识检索+模型生成」的组合架构,有效解决传统大模型的幻觉问题和知识更新滞后等痛点。RAG系统工作流程包含:
-
文档预处理:文本分块、向量化存储
-
实时检索:根据输入query匹配相关文档片段
-
增强生成:将检索结果与prompt结合生成最终回答
2. RAG技术优势
相比传统问答系统,RAG具备:
(1)知识可追溯:每个回答都可关联原始文档依据
(2)动态知识更新:通过修改知识库即可更新模型知识
(3)成本效益:无需微调即可获得领域专精能力
(4)安全可控:通过检索模块实现内容过滤
二、RAGFlow框架介绍
RAGFlow 是一款基于深度文档理解构建的开源 RAG(Retrieval-Augmented Generation)引擎。RAGFlow 可以为各种规模的企业及个人提供一套精简的 RAG 工作流程,结合大语言模型(LLM)针对用户各类不同的复杂格式数据提供可靠的问答以及有理有据的引用。
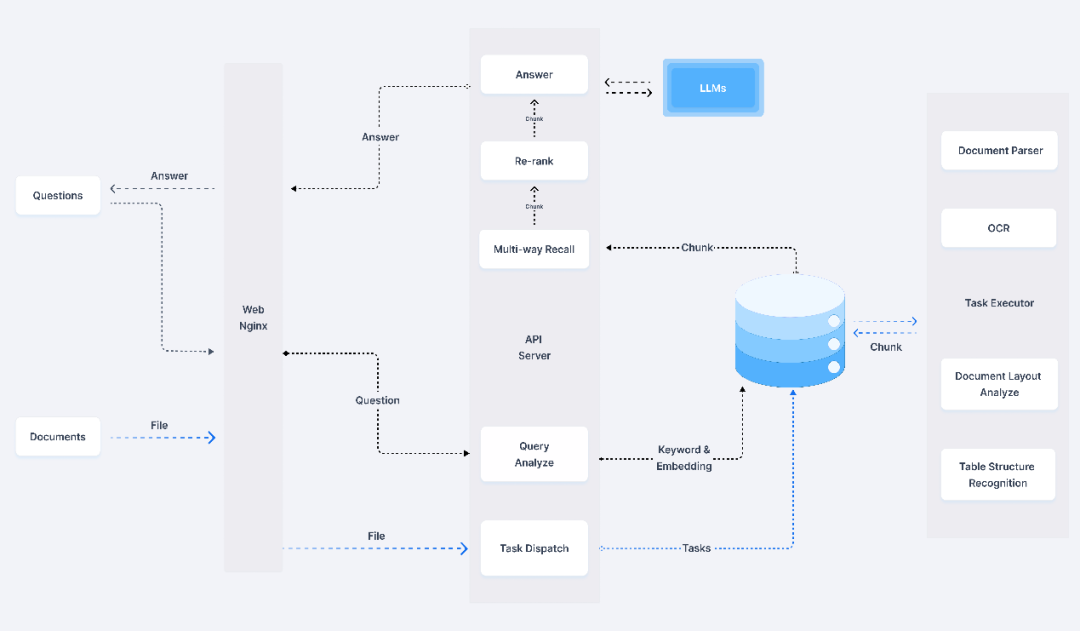
功能优势
(1)"Quality in, quality out"
-
基于深度文档理解,能够从各类复杂格式的非结构化数据中提取真知灼见。
-
真正在无限上下文(token)的场景下快速完成大海捞针测试。
(2)基于模板的文本切片
-
不仅仅是智能,更重要的是可控可解释。
-
多种文本模板可供选择。
(3)有理有据、最大程度降低幻觉(hallucination)
-
文本切片过程可视化,支持手动调整。
-
有理有据:答案提供关键引用的快照并支持追根溯源。
(4)兼容各类异构数据源
-
支持丰富的文件类型,包括 Wo
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2648
2648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











