







Query Translation
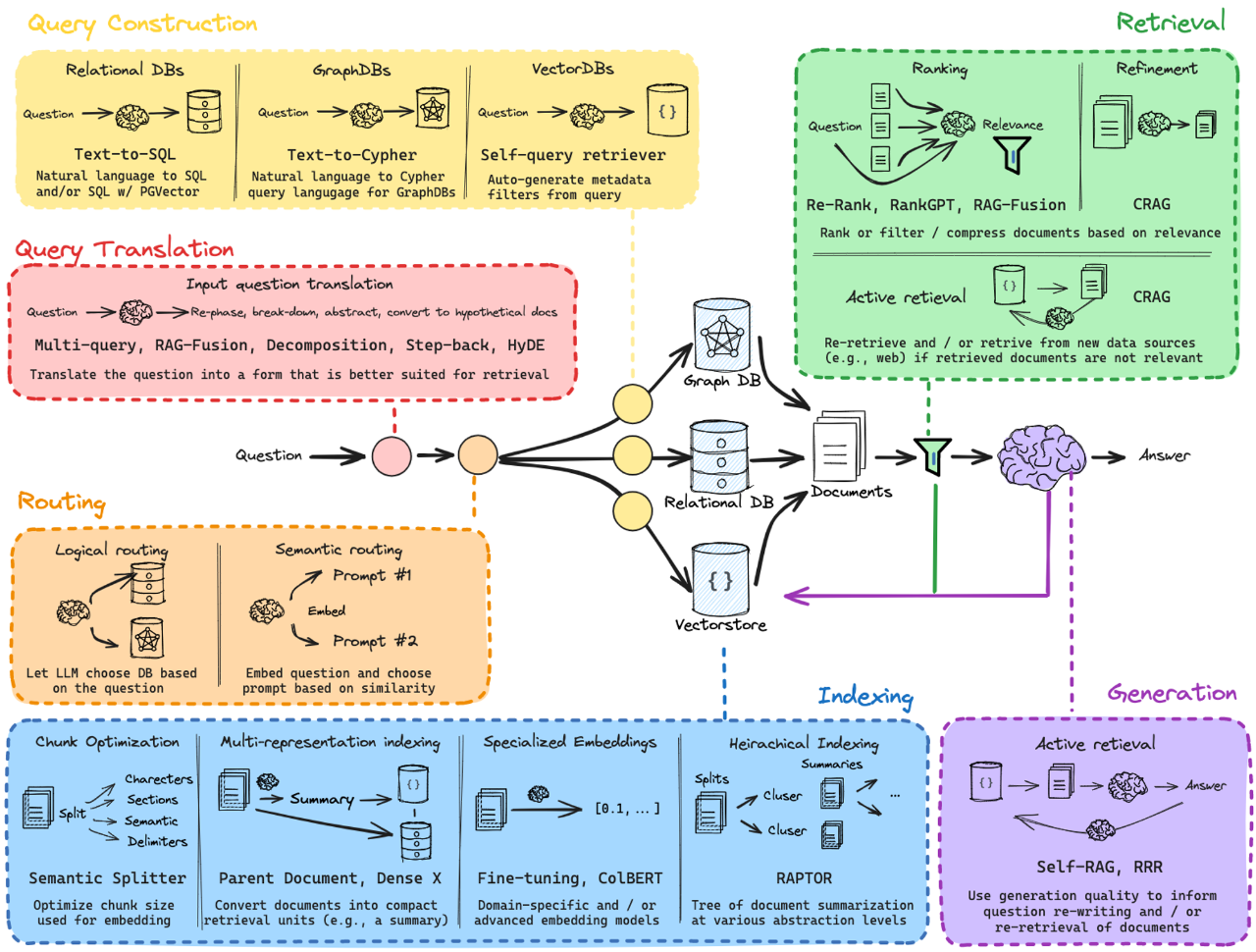
Query Translation 将用户的自然语言查询转换为更适合检索和生成的形式。在这个过程中,系统将原始查询转化成一种或多种可以提升信息检索效果的形式,确保系统能够更有效地从不同的数据源中提取相关信息。
对于具有挑战性的检索任务,用户问题的措辞可能不太恰当。Query Translation 是指将用户的原始问题重新表达,使其更适合检索过程,提高检索的相关性和准确性。
在 RAG 系统中,直接使用用户的原始问题进行检索可能会遇到以下问题:
-
查询过于模糊或复杂,数据库难以直接匹配相关内容。
-
信息缺失,例如用户只输入“DeepSeek-R1 的优势?”而没有明确上下文。
-
不同数据库的适配性,原始查询可能需要调整才能适应不同的数据源(如结构化数据、文档、向量数据库等)。
Query Translation 包括以下几个技术或方法:
Multi-query:通过生成多个查询,系统可以扩大检索范围并提高准确性。例如,针对同一个问题生成几个不同的查询,增加从多个角度检索到相关信息的可能性,提高召回率。
-
原始查询:“如何提高 DeepSeek-R1 的推理能力?”
-
生成的多个查询:
-
-
“DeepSeek-R1 的推理能力受哪些因素影响?”
-
“如何优化提示(prompt)来增强 DeepSeek-R1 的推理能力?”
-
“有哪些方法可以提升 DeepSeek-R1 在数学推理任务上的表现?”
-
RAG-Fusion:指将多个查询的结果进行融合,选择最相关的信息。通过将多个查询结果合并,可以得到更加丰富和精确的答案。
Multi-query 主要是生成多个查询,而 RAG-Fusion 侧重于如何融合这些查询的检索结果(例如 Reciprocal Rank Fusion)。
Decomposition:将复杂问题拆解成多个简单问题,然后分别检索每个子问题的答案。这样可以避免处理复杂问题时可能遇到的信息检索困难。
-
原始查询:“比较 Transformer 和 RNN 在文本摘要任务上的优缺点。”
-
分解后的查询:
-
-
“Transformer 在文本摘要任务上的优点是什么?”
-
“RNN 在文本摘要任务上的优点是什么?”
-
“Transformer 和 RNN 在文本摘要任务上的对比研究有哪些?”
-
Step-back:如果当前查询无法获得足够相关的文档,系统可以先查询更高层次的信息,再细化检索。适用于探索性查询和不确定性较高的问题。
-
用户问题:“李白的诗风如何?”
-
可能的 Step-back 查询:
-
-
“李白的代表作品有哪些?”
-
“李白的诗风如何在《将进酒》中体现?”
-
“李白的诗风受哪些文学流派影响?”
-
HyDE:Hypothetical Document Embeddings,这是一种更为复杂的技术,根据用户查询生成假设性的文档形式,将其嵌入,并在检索中使用它们,从而提高检索效果。通过这种转换,系统可以更好地理解用户意图并找到最相关的信息。
简而言之,Query Translation 通过一系列技术方法将原始问题转化成更易于检索的查询形式,优化检索过程并提升最终的答案质量。
Query Translation 的优势
✅ 提高召回率:通过 Multi-query、RAG-Fusion 等方法确保检索更全面。
✅ 提升查询精度:Step-back 和 HyDE 方法优化查询表达,提高相关性。
✅ 增强复杂查询的可操作性:查询分解可以让复杂问题更容易匹配数据库内容。
QA:Multi-query 和 RAG-Fusion 都首先根据用户的原始查询生成多个相关的查询,那它们有什么区别呢?
Multi-query 和 RAG-Fusion 都是处理和扩展用户查询的技术,尽管它们看起来有些相似,但在具体实现和目标上有所不同。
Multi-query
Multi-query 的核心思想是根据用户的一个查询生成多个不同的查询。这些查询可以从不同角度、不同维度或者用不同的表达方式来探讨同一个问题。这样做的目的是扩展检索范围,增加找到相关信息的机会。
-
目标:扩大检索的覆盖面,确保系统在多个可能的查询方式下都能获取到相关信息。
-
实现:系统会生成多个查询并分别发送到检索模块,获取每个查询的结果。
-
举例:假设用户询问“如何提高机器学习模型的准确性?”系统可能生成以下几个查询:
-
“提高机器学习模型准确性的技巧”
-
“机器学习精度优化方法”
-
“如何训练更精确的机器学习模型”
-
RAG-Fusion
RAG-Fusion 是一种将多个查询的结果融合在一起的技术。它不仅是生成多个查询,还涉及如何处理这些查询的结果,并将它们合并
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8362
8362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











