









如何让企业内部大量的文档方便地被管理者或者员工使用,是数字化过程中的一项重要内容。文档聊天机器人可以基于大模型并以聊天的交互方式为用户提供文档服务,这是目前一个比较流行的提高文档使用效率的方案。
团队可以通过聊天机器人简单地询问与文档有关的问题,即可获得即时、准确的回答,节省了大量的查找文档的时间,从而帮助他们提高工作效率。

以下是一些文档聊天机器人的应用案例:
(1)医疗保健:
-
即时访问患者记录和病史。
-
有效管理合规文件和报告。
-
快速检索存档数据,用于研究和治疗计划。
(2)法务:
-
访问和搜索大量的案件档案和合同。
-
管理合规性和法规文件。
-
通过快速检索判例和法律的论据来提高研究的准确性。
(3)会计:
-
分析财务记录以发现异常。
-
为审计和调查收集归档文件。
-
自动分析复杂的财务数据以检测欺诈。
在技术实现上一般基于大模型以及RAG或者Agent应用架构,并且结合嵌入模型对文档内容向量化,存储到向量数据库,以实现文档内容的检索和问答机制。
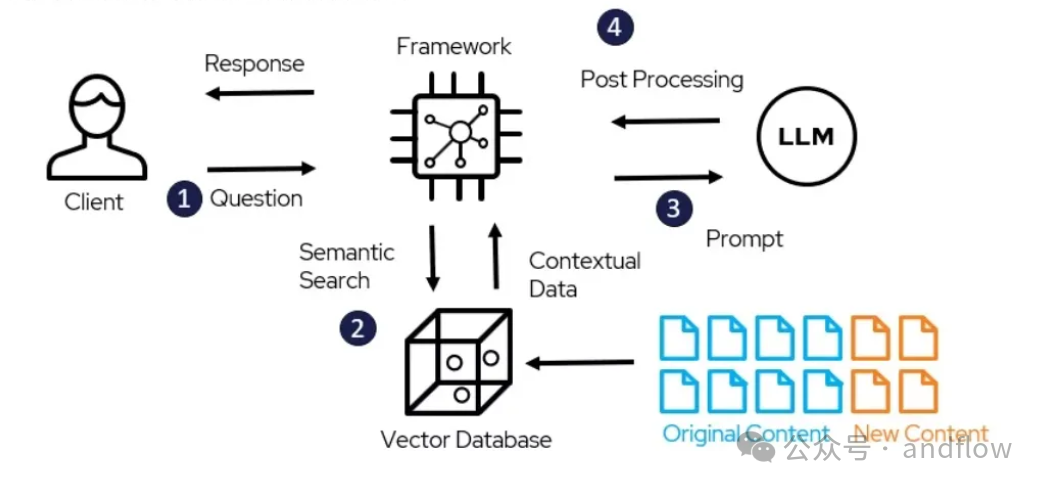
由于文档对于组织来说是重要的数据资产,包含许多机密信息,因此,在建设一个基于大模型的文档聊天机器人时,私有化方案是比较靠谱的选择。与SaaS相比,其优势包括:
-
敏感数据得以保留在组织内部,保证数据安全
-
一次安装,长期使用,而非按月收费
-
可以围绕组织的需求构建系统
-
可以在没有互联网接入的情况下工作
以下是一些比较优秀的开源文档AI聊天助手解决方案。可以根据需求,选择合适的开源项目代码进行改造,以实现适配国内大模型服务或者本地大模型的方案。
01 DocsGPT
https://github.com/arc53/DocsGPT

DocsGPT是一个尖端的开源解决方案,它简化了在项目文档中查找信息的过程。通过集成强大的GPT模型,开发人员可以轻松地提出有关项目的问题并获得准确的答案。DocsGPT提供AI知识共享,并可将知识集成到AI工作流程中,实现端到端的方案。

DocsGPT还针对文档应用提供了开源模型:

02 AiChat
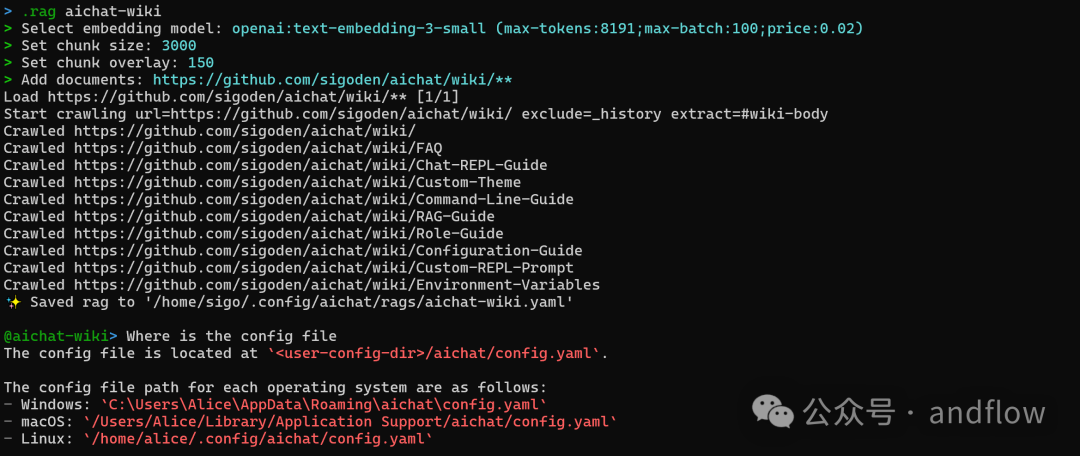
https://github.com/sigoden/aichat
AiChat是一个一体化的LLM CLI工具,具有Shell Assistant、Chat-REPL、RAG、AI Tools Agents等功能。该应用程序使用Rust语言编写,具有多平台支持、shell助手、chat-REPL和多表单输入支持。提供了一个友好的用户界面,并且可以完全离线运行。(1)Shell Assistant

(2)Chat-REPL
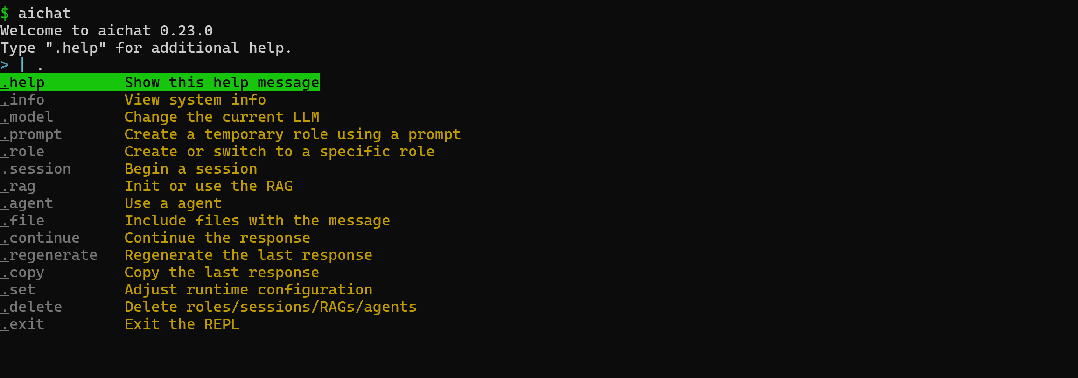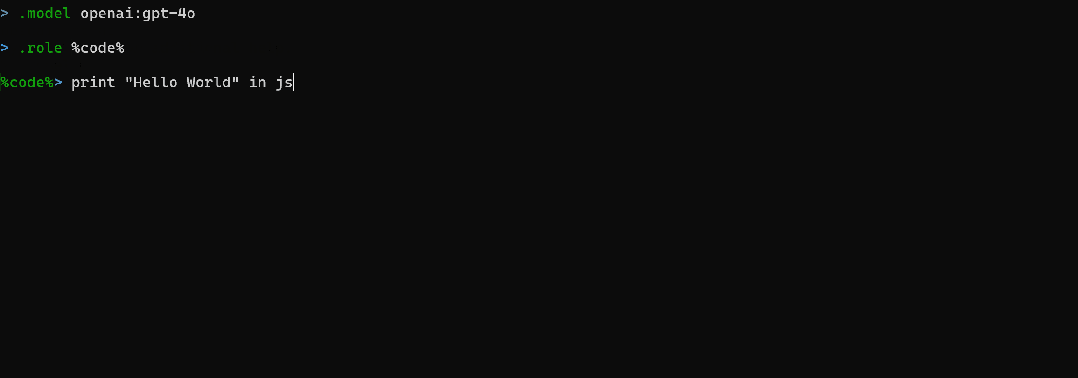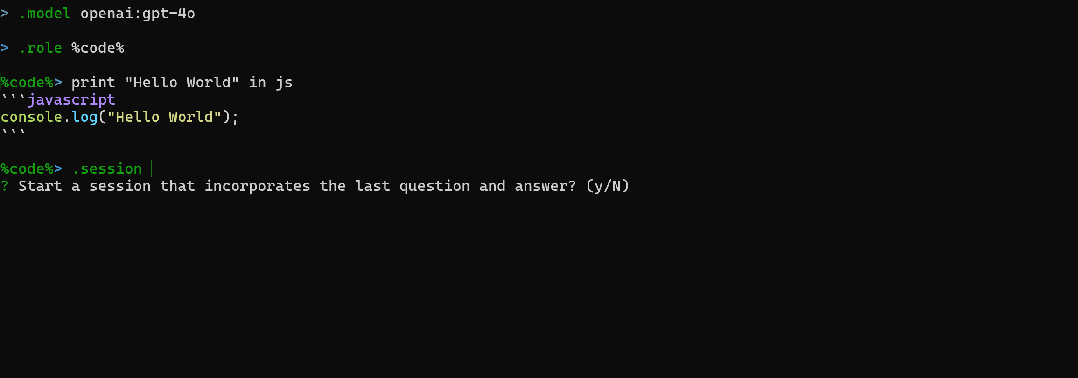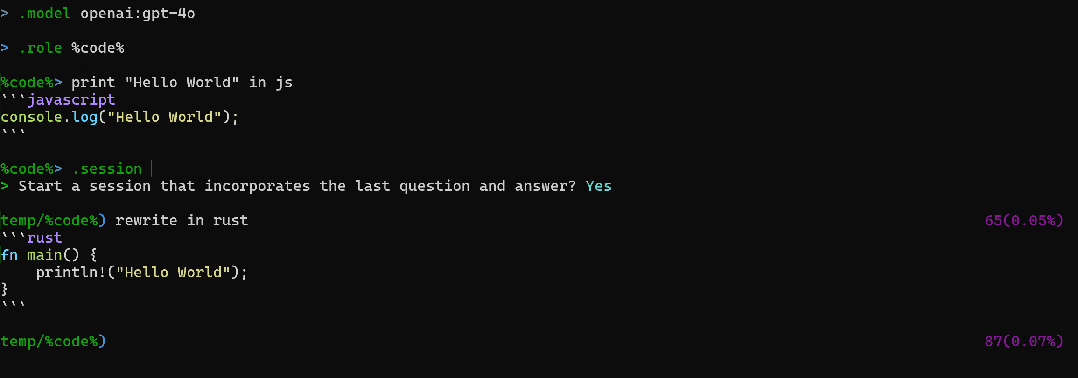
(3)RAG(Chat with your documents)
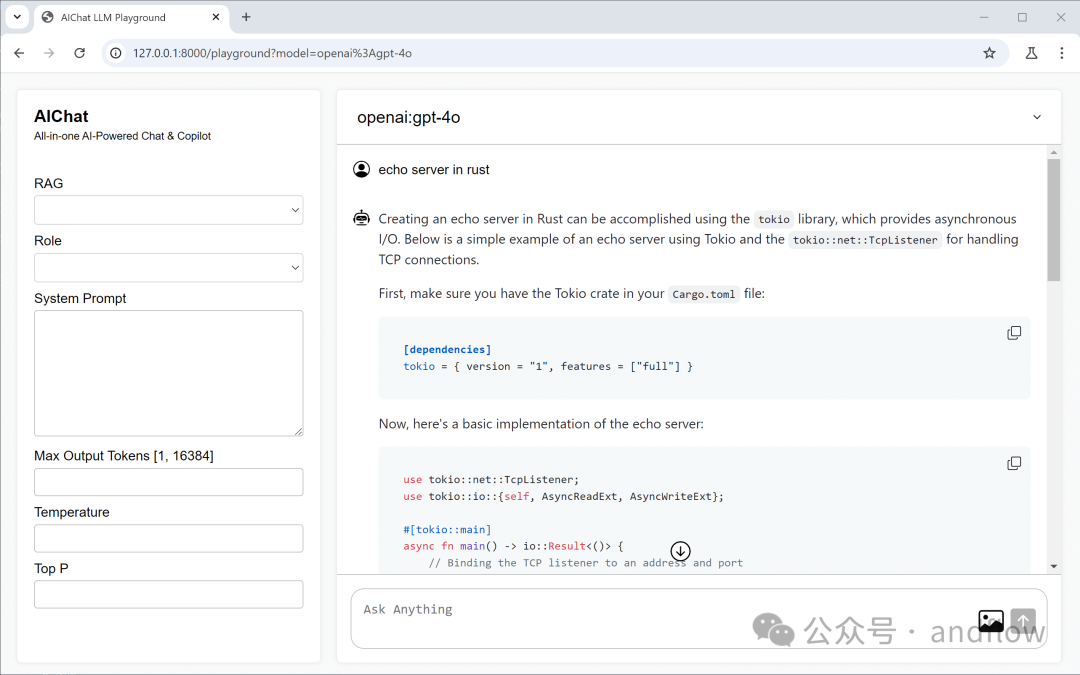
(4)LLM Playground
LLM Playground是一个Web应用程序,支持直接在浏览器中任何LLM进行交互。
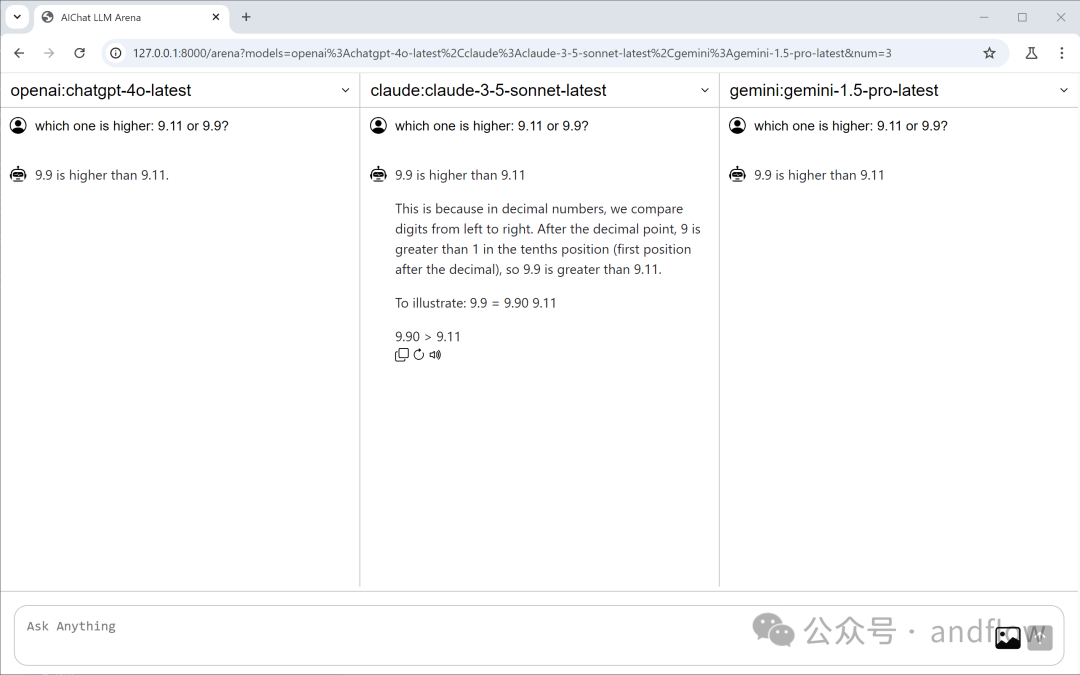
03 private-gpt
https://github.com/zylon-ai/private-gpt
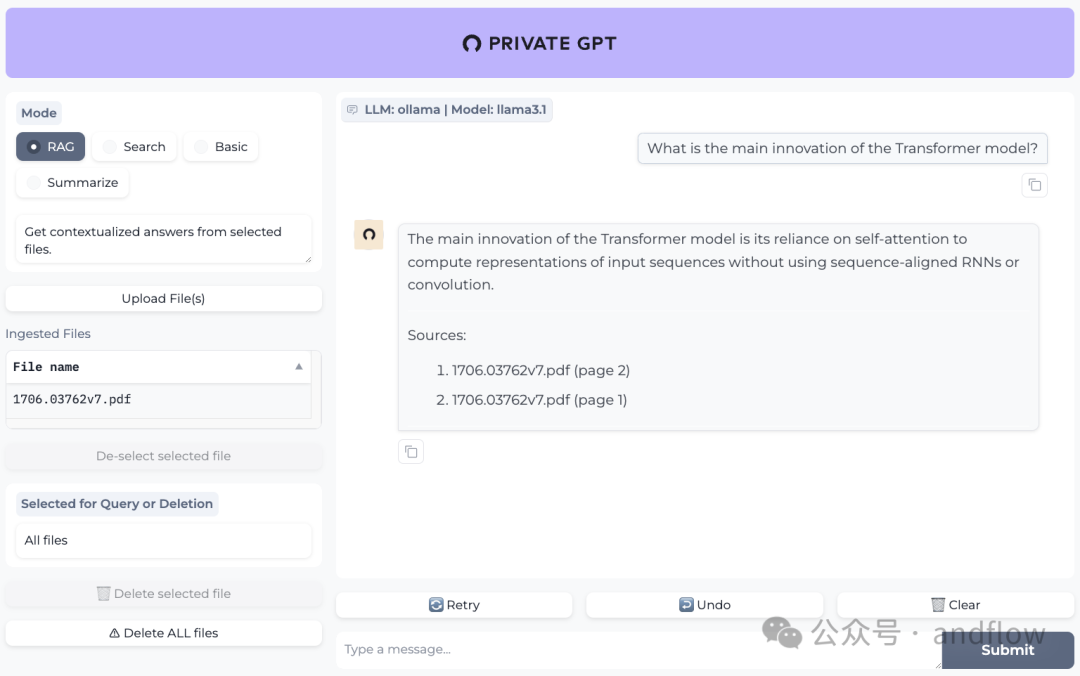
PrivateGPT是一个可以直接用于生产环境的AI项目,可以使用大型语言模型的功能来实现文档的询问,由于项目可以100%私有化部署,任何时候都不会有数据离开运行环境,即使在没有互联网连接的情况下也能够运行。
该项目提供了一个API,提供了构建私有的、上下文感知的AI应用程序所需的所有功能。遵循OpenAI API标准,并支持通用Http和流式响应服务。
API分为两个逻辑块:
(1)高级API,包装了RAG(检索增强生成)复杂性的实现:
-
文档的摄取:内部管理文档解析、拆分、元数据提取、嵌入生成和存储。
-
使用来自文档的上下文完成聊天:提取上下文的检索、提示工程和响应生成。
(2)低级API,允许高级用户实现自己的复杂管道:
-
嵌入生成:基于一段文本。
-
上下文块检索:给定一个查询,从的文档中返回最相关的文本块。
除此之外,还提供了一个Gradio UI客户端来调试API,包含一组非常有用的功能,如:批量模型下载脚本、提取脚本、文档文件夹监视等。
04 LocalGPT
https://github.com/PromtEngineer/localGPT
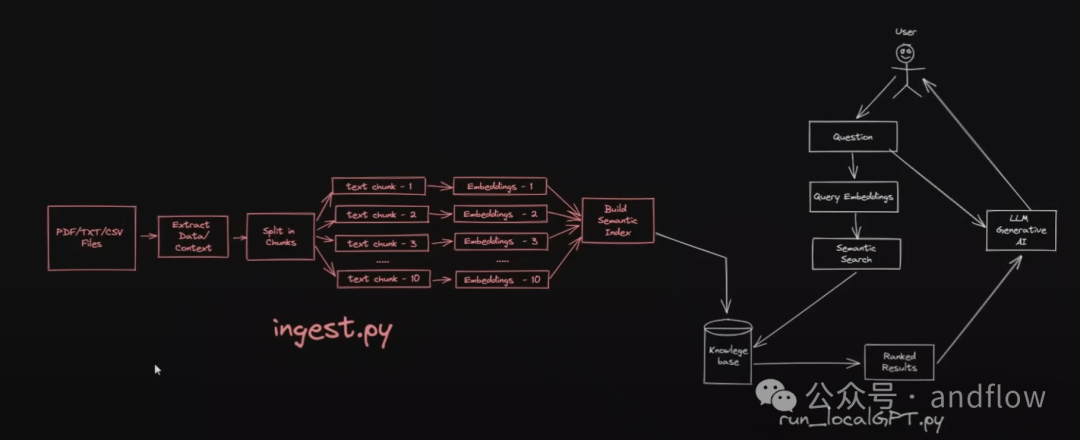
LocalGPT是一个支持使用GPT模型在本地设备上与文档聊天的开源应用程序,允许您在不影响隐私的情况下与文档进行对话。一切都在本地运行,没有数据会离开您的计算机环境。
这个项目参考了private-gpt的实现。
https://github.com/zylon-ai/private-gpt
LocalGPT基于LangChain、HuggingFace LLM、ChromaDB和Streamlit开发。
特征:
-
注重隐私:您的数据保留在您的计算机上,确保100%的安全性。
-
多模型支持:无缝集成各种开源模型,包括HF、GPTQ、GGML和GGUF。
-
多样化的嵌入:可以从一系列开源嵌入中选择嵌入模型。
-
可重用的LLM:一旦下载,LLM可重用,无需重复下载。
-
支持聊天记忆:记住您以前的对话(在会话中)。
-
提供API:LocalGPT有一个API,可以用来构建RAG应用程序。
-
图形界面:LocalGPT带有两个GUI,一个使用API,另一个是独立的(基于streamlit)。
-
支持GPU、CPU、HPU MPS:支持多个平台开箱即用,使用CUDA、CPU、HPU (Intel® Gaudi®)或MPS等。
05 Kotaemon
https://github.com/Cinnamon/kotaemon
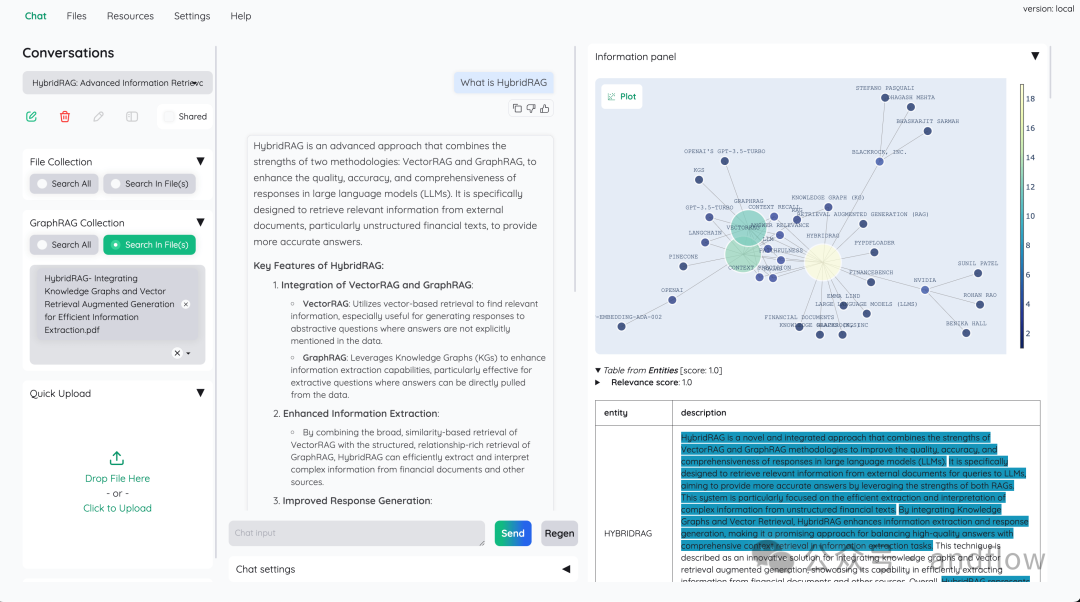
kotaemon是一个开源的、干净的、可定制的RAG UI,用于与文档聊天。为最终用户和开发人员而建。
特征:
-
托管自己的文档QA(RAG)web-UI:支持多用户登录,可在私人/公共收藏中组织文件,与他人协作并分享聊天内容。
-
管理LLM嵌入模型:支持对接本地LLM、或者流行的API提供商(OpenAI,Azure,Ollama,Groq)。
-
Hybrid RAG pipeline:具有混合(全文矢量)检索器和重新排序的Sane默认RAG pipeline,以确保最佳检索质量。
-
支持多模式QA:通过图形和表格支持对多个文档执行问题回答。支持多模态文档解析(UI上的可选选项)。
-
带有高级引用的文档预览:默认情况下,系统将提供详细的引用,以确保LLM答案的正确性。当检索返回相关性较低的文章时,提供查看引文警告(包括相关分数),并直接在浏览器内PDF查看器中进行高亮显示。
-
支持复杂推理方法:使用问题分解来回答复杂问题。支持基于Agent的推理,包括ReAct、ReWOO和其他Agent。
-
可配置的UI:可以在UI上调整检索生成过程的最重要过程(包括提示)。
-
高可扩展性:在Gradio上构建,因此可以自由地自定义或添加任何UI元素。此外,支持多种策略的文件索引检索,提供GraphRAG索引示例。
原文链接:

















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









