




 本文深入讲解C++编程的基础知识,包括数组、字符串、结构、共用体、枚举、指针、动态内存管理、vector和array类的使用,以及字符串处理技巧。探讨了C++中的数据类型、内存管理策略和安全编程实践。
本文深入讲解C++编程的基础知识,包括数组、字符串、结构、共用体、枚举、指针、动态内存管理、vector和array类的使用,以及字符串处理技巧。探讨了C++中的数据类型、内存管理策略和安全编程实践。


本章内容包括:
• 创建和使用数组。
• 创建和使用C-风格字符串。
• 创建和使用string类字符串。
• 使用方法getline()和get()读取字符串。
• 混合输入字符串和数字。
• 创建和使用结构。
• 创建和使用共用体。
• 创建和使用枚举。
• 创建和使用指针。
• 使用new和delete管理动态内存。
• 创建动态数组。
• 创建动态结构。
• 自动存储、静态存储和动态存储。
• vector和array类简介。
数组的初始化规则:
只有在定义数组时才能使用初始化,此后就不能使用了,也不能将一个数组赋给另一个数组:
int cards[4] = {3, 6, 8, 10}; // OK
int counts[10]= {}; // OK,all elements set to 0
int hand[4]; // OK
hand[4] = {5, 6, 7, 8}; // 不允许
hand = cards; // 不允许如果只对数组的一部分进行初始化,则编译器将其他元素设置为0。
如果初始化数组时方括号内([])为空,C++编译器将计算元素个数。例如,对于如下声明:
short things[] = {1, 5, 3, 8};
int num_elements = sizeof things / sizeof(short);列表初始化禁止缩窄转换:
long plifs[] = {25, 92, 3.0}; // 不允许(3.0是double型)
char slifs[4] = {'h', 'i', 1122011, '\0'}; // 不允许(1122011超出char范围)
char tlifs[4] = {'h', 'i', 112, '\0'}; // 允许字符串:
C-风格字符串具有一种特殊的性质:以空字符(null character)结尾,空字符被写作\0,其ASCII码为0,用来标记字符串的结尾。
char dog[8] = {'b', 'e', 'a', 'u', 'x', ' ', 'I', 'I'}; // 不是一个字符串
char cat[8] = {'f', 'a', 't', 'e', 's', 's', 'a', '\0'}; // 一个字符串
cout << dog;
cout << cat;
输出:
beaux II烫烫vY.
fatessa当然可以这样初始化字符串,默认结尾加了'\0':
char bird[11] = "Mr. Cheeps"; // the \0 is understood
char fish[] = "Bubbles"; // let the compiler count#include <iostream>
#include <cstring> // for the strlen() function
int main() {
using namespace std;
const int Size = 15;
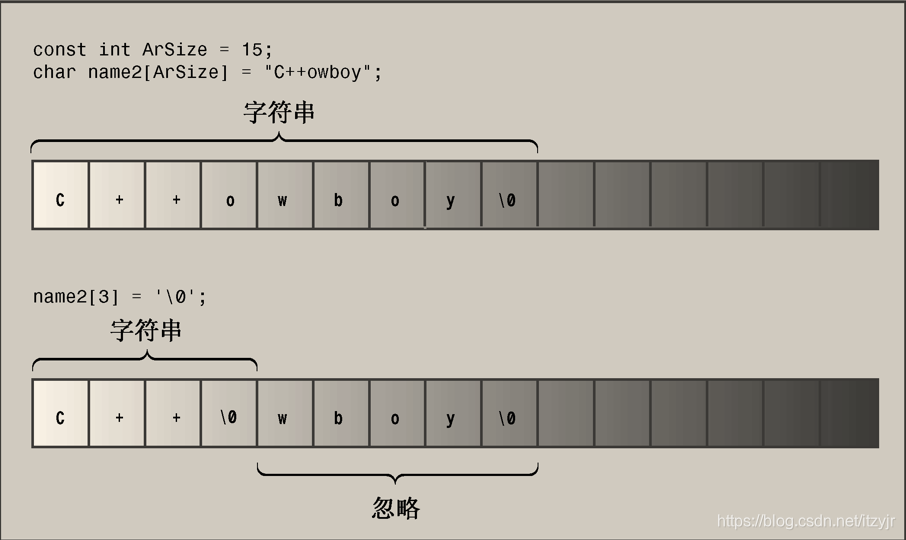
char name1[Size]; // empty array
char name2[Size] = "C++owboy"; // initialized array
// NOTE: some implementations may require the static keyword
// to initialize the array name2
cout << "Howdy! I'm " << name2;
cout << "! What's your name?\n";
cin >> name1;
cout << "Well, " << name1 << ", your name has ";
cout << strlen(name1) << " letters and is stored\n";
cout << "in an array of " << sizeof(name1) << " bytes.\n";
cout << "Your initial is " << name1[0] << ".\n";
name2[3] = '\0'; // set to null character
cout << "Here are the first 3 characters of my name: ";
cout << name2 << endl;
// cin.get();
// cin.get();
return 0;
}Howdy! I'm C++owboy! What's your name?
|Basicman
Well, Basicman, your name has 8 letters and is stored
in an array of 15 bytes.
Your initial is B.
Here are the first 3 characters of my name: C++使用\0截短了字符串:
一个字符串输入的易错点:
#include <iostream>
int main() {
using namespace std;
const int ArSize = 20;
char name[ArSize];
char dessert[ArSize];
cout << "Enter your name:\n";
cin >> name;
cout << "Enter your favorite dessert:\n";
cin >> dessert;
cout << "I have some delicious " << dessert;
cout << " for you, " << name << ".\n";
return 0;
}
Enter your name:
|AlistairDreeb
Enter your favorite dessert:
|cookie
I have some delicious cookie for you, AlistairDreeb.Enter your name:
|Alistair Dreeb
Enter your favorite dessert:
I have some delicious Dreeb for you, Alistair.输入“Alistair Dreeb”后回车,还没有对“输入甜点的提示”作出反应,程序便把它显示出来了,然后立即显示最后一行。
这是由于cin使用空白(空格、制表符和换行符)来确定字符串的结束位置(这点和scanf一样),这意味着cin在获取字符数组输入时只读取一个单词。读取该单词后,cin将该字符串放到数组中,并自动在结尾添加空字符。
这个例子的实际结果是,cin把Alistair作为第一个字符串,并将它放到name数组中。cin和scanf一样用空格分隔读取的字符,这就把Dreeb留在输入队列中。当cin在输入队列中搜索用户喜欢的甜点时,它发现了Dreeb,因此cin读取Dreeb,并将它放到dessert数组中。(这里其实涉及到输入缓冲区,可参考C的:关于getchar()缓冲机制解析)

每次读取一行字符串输入:
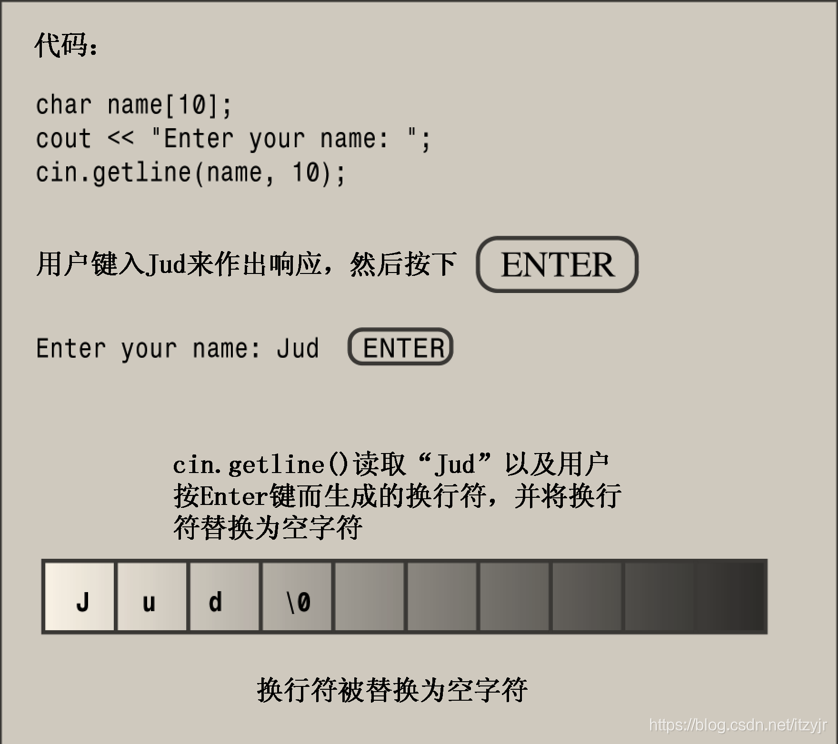
istream中的类(如cin)提供了一些面向行的类成员函数:getline( )和get( )。这两个函数都读取一行输入,直到到达换行符。然而,随后getline()将丢弃换行符,而get()将换行符保留在输入序列中。这与读取换行符不同,它是保留在输入序列中。
我们看下C中的几个函数:(不存在将换行符保留在输入序列中)
| gets() | 丢弃末尾回车换行符 | fgets() | 获取所有键盘输入字符(包括回车换行符) |
| puts() | 添加末尾回车换行符 | fputs() | 所有字符原样输出 |
| cin>>、get() | 获取除换行符的字符,并将换行符保留在输入序列中 注:cin>>和scanf()一样空格是分隔符 |
| getline() | 获取除换行符的字符,遇到换行符则置为空字符 |
再来看下cin.get()方法:
cin.get(name, ArSize);
cin.get(dessert, ArSize); // a problem由于第一次调用后,换行符将留在输入队列中,因此第二次调用时看到的第一个字符便是换行符。因此get( )认为已到达行尾,而没有发现任何可读取的内容。如果不借助于帮助,get( )将不能跨过该换行符。
幸运的是,get()有另一种变体。使用不带任何参数的cin.get( )调用可读取下一个字符(即使是换行符),因此可以用它来处理换行符,为读取下一行输入做好准备。也就是说,可以采用下面的调用序列:
cin.get(name, ArSize); // read first line
cin.get(); // read newline
cin.get(dessert, ArSize); // read second line另一种使用get( )的方式是将两个类成员函数拼接起来(合并),如下所示:
cin.get(name, ArSize).get(); // concatenate member functions之所以可以这样做,是由于cin.get(name,ArSize)返回一个cin对象,该对象随后将被用来调用get( )函数。同样,下面的语句将把输入中连续的两行分别读入到数组name1和name2 中,其效果与两次调用cin.getline( )相同:
cin.getline(name1, ArSize).getline(name2, ArSize);#include <iostream>
int main() {
using namespace std;
const int ArSize = 20;
char name[ArSize];
char dessert[ArSize];
cout << "Enter your name:\n";
cin.get(name, ArSize).get(); // read string, newline
cout << "Enter your favorite dessert:\n";
cin.get(dessert, ArSize).get();
cout << "I have some delicious " << dessert;
cout << " for you, " << name << ".\n";
return 0;
}Enter your name:
|Mai Parfait
Enter your favorite dessert:
|Chocolate Mousse
I have some delicious Chocolate Mousse for you, Mai Parfait.为什么要使用get( ),而不是getline( )呢?首先,老式实现没有getline( )。其次,get( )使输入更仔细。例如,假设用get( )将一行读入数组中。如何知道停止读取的原因是由于已经读取了整行,而不是由于数组已填满呢?查看下一个输入字符,如果是换行符,说明已读取了整行;否则,说明该行中还有其他输入。总之,getline( )使用起来简单一些,但get( )使得检查错误更简单些。可以用其中的任何一个来读取一行输入;只是应该知道,它们的行为稍有不同。
空行和其他问题:
当getline( )或get( )读取空行时,将发生什么情况?最初的做法是,下一条输入语句将在前一条getline( )或get( )结束读取的位置开始读取;但当前的做法是,当get( )读取空行后将设置失效位(failbit)。这意味着接下来的输入将被阻断,但可以用下面的命令来恢复输入:
cin.clear();另一个潜在的问题是,输入字符串可能比分配的空间长。如果输入行包含的字符数比指定的多,则getline( )和get( )将把余下的字符留在输入队列中,而getline( )还会设置失效位,并关闭后面的输入。
#include <iostream>
int main() {
using namespace std;
cout << "What year was your house built?\n";
int year;
cin >> year;
// cin.get();
cout << "What is its street address?\n";
char address[80];
cin.getline(address, 80);←获取到换行符,置为空字符
cout << "Year built: " << year << endl;
cout << "Address: " << address << endl;
cout << "Done!\n";
return 0;
}
What year was your house built?
|1966
What is its street address?
Year built: 1966
Address:
Done!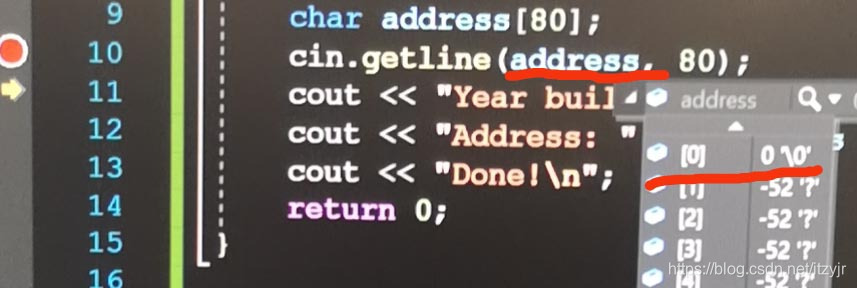 解注释第7行后:
解注释第7行后:![]()
调试发现,getline(address, Size)读取到address中的是空'\0',而非'\n',因为getline()会将换行符置为空字符。而cin.get()读取到的是'\n'——ASCII码的十进制数10。
用户根本没有输入地址的机会。问题在于,当cin读取年份,将回车键生成的换行符留在了输入队列中。后面的cin.getline( )看到换行符后,将认为是一个空行(而不是回车带来的'\n'),并将一个空字符串赋给address数组。像之前那样,解注释cin.get();这行后,正常输出。
也可以利用表达式cin >> year返回cin对象,将调用拼接起来:(cin >> year).get();
string类简介:
#include <iostream>
#include <string> // make string class available
int main() {
using namespace std;
char charr1[20]; // create an empty array
char charr2[20] = "jaguar"; // create an initialized array
string str1; // create an empty string object
string str2 = "panther"; // create an initialized string
cout << "Enter a kind of feline: ";
cin >> charr1;
cout << "Enter another kind of feline: ";
cin >> str1; // use cin for input
cout << "Here are some felines:\n";
cout << charr1 << " " << charr2 << " "
<< str1 << " " << str2 // use cout for output
<< endl;
cout << "The third letter in " << charr2 << " is "
<< charr2[2] << endl;
cout << "The third letter in " << str2 << " is "
<< str2[2] << endl; // use array notation
return 0;
}
Enter a kind of feline: |ocelot
Enter another kind of feline: |tiger
Here are some felines:
ocelot jaguar tiger panther
The third letter in jaguar is g
The third letter in panther is nstring对象和字符数组之间的主要区别是,可以将string对象声明为简单变量,而不是数组。
类设计让程序能够自动处理string的大小。例如,str1的声明创建一个长度为0的string对象,但程序将输入读取到str1中时,将自动调整str1的长度。
这使得与使用数组相比,使用string对象更方便,也更安全。从理论上说,可以将char数组视为一组用于存储一个字符串的char存储单元,而string类变量是一个表示字符串的实体。
使用string类时,某些操作比使用数组时更简单。例如,不能将一个数组赋给另一个数组,但可以将一个string对象赋给另一个string对象。
string类简化了字符串合并操作。可以使用运算符+将两个string对象合并起来,还可以使用运算符+=将字符串附加到string对象的末尾。
string str3;
str3 = str1 + str2;
str1 += str2;使用C-风格的字符串,提供头文件string.h可使用strcpy()和strcat()完成字符串复制到字符数组和将字符附加到字符数组末尾。
如下代码:
char site[10] = "house";
strcat(site, " of pancakes"); // memory problem函数strcat( )试图将全部12个字符复制到数组site中,这将覆盖相邻的内存。这可能导致程序终止,或者程序继续运行,但数据被损坏。string类具有自动调整大小的功能,从而能够避免这种问题发生。C函数库确实提供了与strcat( )和strcpy( )类似的函数—strncat( )和strncpy( ),它们接受指出目标数组最大允许长度的第三个参数,因此更为安全,但使用它们进一步增加了编写程序的复杂度。
下面是两种确定字符串中字符数的方法:
int len1 = str1.size(); // C++ style
int len2 = strlen(charr1);// C style总之,C函数使用参数来指出要使用哪个字符串,而C++ string类对象使用对象名和句点运算符来指出要使用哪个字符串。
string类I/O:
#include <iostream>
#include <string> // make string class available
#include <cstring> // C-style string library
int main() {
using namespace std;
char charr[20];
string str;
cout << "Length of string in charr before input: "
<< strlen(charr) << endl;
cout << "Length of string in str before input: "
<< str.size() << endl;
cout << "Enter a line of text:\n";
cin.getline(charr, 20); // indicate maximum length
cout << "You entered: " << charr << endl;
cout << "Enter another line of text:\n";
getline(cin, str); // cin now an argument; no length specifier
cout << "You entered: " << str << endl;
cout << "Length of string in charr after input: "
<< strlen(charr) << endl;
cout << "Length of string in str after input: "
<< str.size() << endl;
return 0;
}
Length of string in charr before input: 31
Length of string in str before input: 0
Enter a line of text:
|peanut butter
You entered: peanut butter
Enter another line of text:
|blueberry jam
You entered: blueberry jam
Length of string in charr after input: 13
Length of string in str after input: 13在用户输入之前,该程序指出数组charr中的字符串长度为31,这比该数组的长度要大。这里要两点需要说明。首先,为初始化的数组的内容是未定义的;其次,函数strlen( )从数组的第一个元素开始计算字节数,直到遇到空字符。在这个例子中,在数组末尾的几个字节后才遇到空字符。对于未被初始化的数据,第一个空字符的出现位置是随机的,因此您在运行该程序时,得到的数组长度很可能与此不同。
另外,用户输入之前,str中的字符串长度为0。这是因为未被初始化的string对象的长度被自动设置为0。
注意:代码中getline(cin, str);没有使用句点,这表明这个getline()不是类方法。它将cin作为参数,指出到哪里去查找输入。另外,也没有指出字符串长度的参数,因为string对象将根据字符串的长度自动调整自已的大小。
那么,为何一个getline( )是istream的类方法,而另一个不是呢?在引入string类之前很久,C++就有istream类。因此istream的设计考虑到了诸如double和int等基本C++数据类型,但没有考虑string类型,所以istream类中,有处理double、int和其他基本类型的类方法,但没有处理string对象的类方法。
由于istream类中没有处理string对象的类方法,因此您可能会问,下述代码为何可行呢?
cin >> str; // read a word into the str string object这里处理string对象的代码使用string类的一个友元函数。有关友元函数及这种技术为何可行,将在第11章介绍。
其他形式的字符串字面量:
wchar_t title[] = L"Chief Astrogator"; // w_char string,前缀L
/* C++11 */
char16_t name[] = u"Felonia Ripova"; // chat_16 string,前缀u
chat32_t car[] = U"Humber Super Snipe"; // char_32 string,前缀U
C++11还支持Unicode字符编码方案UTF-8。在这种方案中,根据编码的数字值,字符可能存储1~4个八位组。
C++使用前缀u8来表示这种类型的字符串字面量。C++11新增的另一种类型是原始(raw)字符串。在原始字符串中,字符表示的就是自己,例如,序列\n不表示换行符,而表示两个常规字符—斜杠和n,因此在屏幕上显示时,将显示这两个字符。另一个例子是,可在字符串中使用",而无需像程序清单4.8中那样使用繁琐的\"。当然,既然可在字符串字面量包含",就不能再使用它来表示字符串的开头和末尾。因此,原始字符串将"(和)"用作定界符,并使用前缀R来标识原始字符串:
cout << R"(Jim "King" Tutt uses "\n" instead of endl.)" << '\n';
将显示:Jim "King" Tutt uses "\n" instead of endl.
如果使用标准字符串字面量,将需要这样编写代码:
cout << "Jim \"King\" Tutt uses \"\\n\" instead of endl." << '\n';如果是原始(raw)字符串,它遇到第一个“)”时会认为字符串结束,这时要使用R"+*(...)+*"标识原始字符串的结尾。如:
cout << R"+*("(Who wouldn't?)", she whispered.)+*" << endl;
将显示:"(Who would't?)", she whispered.也可将前缀R与其他字符串前缀结合使用,以标识wchar_t等类型的原始字符串。可以这样:Ru或UR等。
结构与共用体与C基本一致,不用介绍了。
枚举:
enum spectrum {red, orange, yellow, green, blue, violet, indigo, ultraviolet};默认初始化为整数值0~7。也可以覆盖默认值,后面的量在覆盖值基础上依次+1。
spectrum band; // 声明一个枚举spectrum类型
band = blue; // 有效
band = 2000; // 无效,因为2000不是一个枚举量
band = orange;
++band; ← 无效,虽然red<++band<ultraviolet,但防止出现++band==ultraviolet,【怕超出范围】的现象出现,故不允许
band = orange + red; ← 无效,因为没有为枚举定义运算符+,也是【怕超出范围】
band = 3; ← 不允许提升为int,也是【怕超出范围】
int color = blue; // 有效,spectrum类型转换为int型
color = 3 + red;// 有效,red转换为int型
band = spectrum(3); ← 这是强制类型转换,因red<3<ultraviolet有效,它与green值一样了。(注:band只是声明的一个变量,原枚举列表值不变)
band = spectrum(40003); // 这个结果是不确定的,因为值是一个不适当的值,不要这么做最初,对于枚举来说,只有声明中指出的那些值是有效的。然而,C++现在通过强制类型转换,增加了可赋给枚举变量的合法值。每个枚举都有取值范围(range),通过强制类型转换,可以将取值范围中的任何整数值赋给枚举变量,即使这个值不是枚举值。
enum bits { one = 1, two = 2, four = 4, eight = 8 };
bits myflag;
myflag = bits(6); // 有效,因为1<6<2^4-1,在bits的取值范围内枚举的取值范围:
首先,要找出上限,需要知道枚举量的最大值。找到大于这个最大值的最小的2的幂,将它减去1,得到的便是取值范围的上限。例如,前面定义的bigstep的最大值枚举值是101。在2的幂中,比这个数大的最小值为128,因此取值范围的上限为127。要计算下限,需要知道枚举量的最小值。如果它不小于0,则取值范围的下限为0;否则,采用与寻找上限方式相同的方式,但加上负号。例如,如果最小的枚举量为−6,而比它小的、最大的2的幂是−8(加上负号),因此下限为−7。
选择用多少空间来存储枚举由编译器决定。对于取值范围较小的枚举,使用一个字节或更少的空间;而对于包含long类型值的枚举,则使用4个字节。
C++11扩展了枚举,增加了作用域内枚举(scoped enumeration)。
指针和自由存储空间:
#include <iostream>
int main() {
using namespace std;
int updates = 6; // declare a variable
int* p_updates; // declare pointer to an int
p_updates = &updates; // assign address of int to pointer
cout << "Values: updates = " << updates;
cout << ", *p_updates = " << *p_updates << endl;
cout << "Addresses: &updates = " << &updates;
cout << ", p_updates = " << p_updates << endl;
*p_updates = *p_updates + 1;
cout << "Now updates = " << updates << endl;
return 0;
}
Values: updates = 6, *p_updates = 6
Addresses: &updates = 001EF858, p_updates = 001EF858
Now updates = 7
危险更易发生在那些使用指针不仔细的人身上。极其重要的一点是:在C++中创建指针时,计算机将分配用来存储地址的内存,但不会分配用来存储指针所指向的数据的内存。为数据提供空间是一个独立的步骤,忽略这一步无疑是自找麻烦,如下所示:
long* fellow; // 未初始化的指针(野指针)
*fellow = 223323;fellow确实是一个指针,但它指向哪里呢?上述代码没有将地址赋给fellow。那么223323将被放在哪里呢?我们不知道。由于fellow没有被初始化,它可能有任何值。不管值是什么,程序都将它解释为存储223323的地址。如果fellow的值碰巧为1200,计算机将把数据放在地址1200上,即使这恰巧是程序代码的地址。fellow指向的地方很可能并不是所要存储223323的地方。这种错误可能会导致一些最隐匿、最难以跟踪的bug。
使用new来分配内存:
int * pn = new int;#include <iostream>
int main() {
using namespace std;
int nights = 1001;
int* pt = new int;
*pt = 1001;
cout << "nights value = ";
cout << nights << ": location " << &nights << endl;
cout << "int ";
cout << "value = " << *pt << ": location = " << pt << endl;
double* pd = new double;
*pd = 10000001.0;
cout << "double ";
cout << "value = " << *pd << ": location = " << pd << endl;
cout << "location of pointer pd: " << &pd << endl;
cout << "size of pt = " << sizeof(pt);
cout << ": size of *pt = " << sizeof(*pt) << endl;
cout << "size of pd = " << sizeof pd;
cout << ": size of *pd = " << sizeof(*pd) << endl;
delete pt; // 释放内存
delete pd; // 释放内存
return 0;
}nights value = 1001: location 003AF980
int value = 1001: location = 006EF000
double value = 1e+07: location = 006F2D40
location of pointer pd: 003AF968
size of pt = 4: size of *pt = 4
size of pd = 4: size of *pd = 8从最后打印出的两行可以知道,这里指针只是一个int型的变量,指向int的指针的长度与指向double的指针是相同的,它们都是地址。但由于程序中声明了指针的类型,因此程序知道*pd是8个字节的double值,*pt是4个字节的int值。
注:用delete删除指向的内存,但不会删除指针本身。所以可以用指针重新指向另一个新分配的内存。还有就是:不要尝试释放已经释放的内存块,C++标准指出,这样做的结果将是不确定的,这意味着什么情况都可能发生(可以想像一下,你刚释放,另一段代码把数据存储在了这块内存,你再释放一次,不就影响了代码的原本逻辑了吗)。另外,不能使用delete来释放声明变量所获得的内存。只能用delete来释放使用new分配的内存。然后,对空指针使用delete是安全的。
使用new来创建的动态数组:
假设要编写一个程序,它是否需要数组取决于运行时用户提供的信息。如果通过声明来创建数组,则在程序被编译时将为它分配内存空间。不管程序最终是否使用数组,数组都在那里,它占用了内存。在编译时给数组分配内存被称为静态联编(static binding),意味着数组是在编译时加入到程序中的。但使用new时,如果在运行阶段需要数组,则创建它;如果不需要,则不创建。还可以在程序运行时选择数组的长度。这被称为动态联编(dynamic binding),意味着数组是在程序运行时创建的。这种数组叫作动态数组(dynamic array)。使用静态联编时,必须在编写程序时指定数组的长度;使用动态联编时,程序将在运行时确定数组的长度。
int * psome = new int[10];
delete [] psome; // 释放它们#include <iostream>
int main() {
using namespace std;
double wages[3] = { 10000.0, 20000.0, 30000.0 };
short stacks[3] = { 3, 2, 1 };
double* pw = wages;
short* ps = &stacks[0];
cout << "pw = " << pw << ", *pw = " << *pw << endl;
pw = pw + 1;
cout << "add 1 to the pw pointer:\n";
cout << "pw = " << pw << ", *pw = " << *pw << "\n\n";
cout << "ps = " << ps << ", *ps = " << *ps << endl;
ps = ps + 1;
cout << "add 1 to the ps pointer:\n";
cout << "ps = " << ps << ", *ps = " << *ps << "\n\n";
cout << "access two elements with array notation\n";
cout << "stacks[0] = " << stacks[0]
<< ", stacks[1] = " << stacks[1] << endl;
cout << "access two elements with pointer notation\n";
cout << "*stacks = " << *stacks
<< ", *(stacks + 1) = " << *(stacks + 1) << endl;
cout << sizeof(wages) << " = size of wages array\n";
cout << sizeof(pw) << " = size of pw pointer\n";
return 0;
}pw = 0037FBF4, *pw = 10000
add 1 to the pw pointer:
pw = 0037FBFC, *pw = 20000
ps = 0037FBE4, *ps = 3
add 1 to the ps pointer:
ps = 0037FBE6, *ps = 2
access two elements with array notation
stacks[0] = 3, stacks[1] = 2
access two elements with pointer notation
*stacks = 3, *(stacks + 1) = 2
24 = size of wages array
4 = size of pw pointer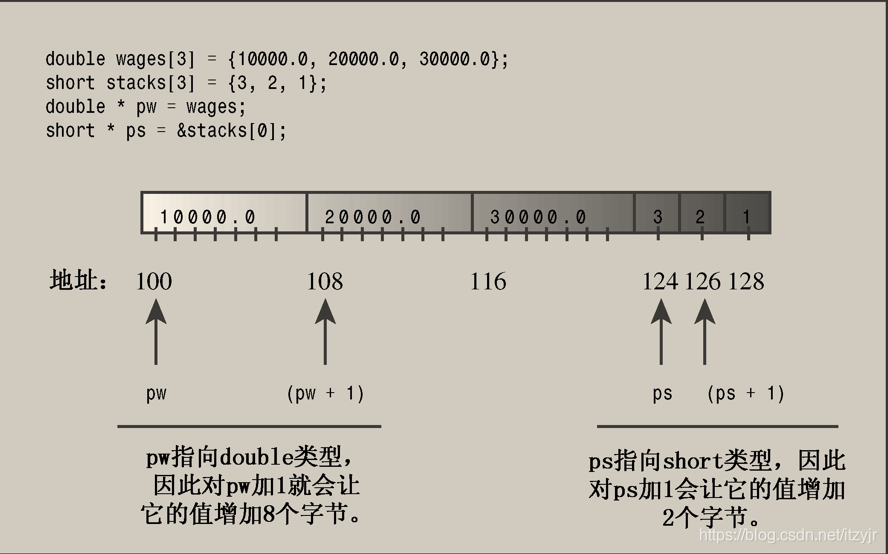
通常,使用数组表示法时,C++都执行下面的转换:
arrayname[i] => *(arrayname + i)如果使用的是指针,而不是数组名,则C++也将执行同样的转换:
pointername[i] => *(pointername + i)因此,在很多情况下,可以相同的方式使用指针名和数组名。对于它们,可以使用数组方括号表示法,也可以使用解除引用运算符(*)。在多数表达式中,它们都表示地址。但有两个区别:
1.可以修改指针的值,而数组名是常量(可参考C的:关于二维数组与指针):
pointername = pointername + 1; // 有效
arrayname = arrayname + 1; // 不允许2.对数组应用sizeof运算符得到的是数组的长度,而对指针应用sizeof得到的是指针的长度,即使指针指向的是一个数组。
根据上面程序最后打印的两行就可知道这一点,sizeof(wages)==24,而sizeof(pw) == 4。
使用new创建动态结构:
#include <iostream>
struct inflatable {
char name[20];
float volume;
double price;
};
int main() {
using namespace std;
inflatable* ps = new inflatable;
cout << "Enter name of inflatable item: ";
cin.get(ps->name, 20); // method 1 for member access
cout << "Enter volume in cubic feet: ";
cin >> (*ps).volume; // method 2 for member access
cout << "Enter price: $";
cin >> ps->price;
cout << "Name: " << (*ps).name << endl;
cout << "Volume: " << ps->volume << " cubic feet\n";
cout << "Price: $" << ps->price << endl;
delete ps;
return 0;
}Enter name of inflatable item: |Fabulous Frodo
Enter volume in cubic feet: |1.4
Enter price: $|27.99
Name: Fabulous Frodo
Volume: 1.4 cubic feet
Price: $27.99用结构直接访问成员时,用点号,用指针访问成员时用符号->。
#define _CRT_SECURE_NO_WARNINGS
#include <iostream>
#include <cstring> // 或string.h
using namespace std;
char* getname(void); // 函数原型
int main() {
char* name;
name = getname();
cout << name << " at " << (int*)name << "\n";
delete[] name; // 释放内存
name = getname(); // 重复使用自由空间
cout << name << " at " << (int*)name << "\n";
delete[] name; // 再次释放内存
return 0;
}
char* getname() {
char temp[80]; // 临时存储
cout << "Enter last name: ";
cin >> temp;
char* pn = new char[strlen(temp) + 1];// 要动态内存分配,因为是在函数体局部区域
// 函数原型:char* strcpy(char* destination, const char* source);
strcpy(pn, temp); // 将字符串拷贝到一个更小的内存空间
return pn; // 函数结束时temp也自动释放了
}Enter last name: |Fredeldumpkin
Fredeldumpkin at 00760228
Enter last name: |Pook
Pook at 00762D78注:直接cout << name;输出的是指针指向地址里面的元素。比如输出:Freduldumpkin at Freduldumpkin。 这也是printf("%s",name);与printf("%p",name);的区别——一个打印值一个打印地址。
自动存储、静态存储和动态存储:
根据用于分配内存的方法,C++有3种管理数据内存的方式:自动存储、静态存储和动态存储(有时也叫作自由存储空间或堆)。在存在时间的长短方面,以这3种方式分配的数据对象各不相同。下面简要地介绍每种类型(C++11新增了第四种类型—线程存储,这将在第9章简要地讨论)。
1.自动存储
在函数内部定义的常规变量使用自动存储空间,被称为自动变量(automatic variable),这意味着它们在所属的函数被调用时自动产生,在该函数结束时消亡。例如,上面程序清单中的temp数组仅当getname( )函数活动时存在。当程序控制权回到main( )时,temp使用的内存将自动被释放。如果getname( )返回temp的地址,则main( )中的name指针指向的内存将很快得到重新使用。这就是在getname( )中使用new的原因之一。
实际上,自动变量是一个局部变量,其作用域为包含它的代码块。代码块是被包含在花括号中的一段代码。到目前为止,我们使用的所有代码块都是整个函数。然而,函数内也可以有代码块。如果在其中的某个代码块定义了一个变量,则该变量仅在程序执行该代码块中的代码时存在。
自动变量通常存储在栈中。这意味着执行代码块时,其中的变量将依次加入到栈中,而在离开代码块时,将按相反的顺序释放这些变量,这被称为后进先出(LIFO)。因此,在程序执行过程中,栈将不断地增大和缩小。
2.静态存储
静态存储是整个程序执行期间都存在的存储方式。使变量成为静态的方式有两种:➊在函数外面定义它;➋在声明变量时使用关键字static:
static double fee = 56.50;在K&R C中,只能初始化静态数组和静态结构,而C++ Release 2.0(及后续版本)和ANSI C中,也可以初始化自动数组和自动结构。
自动存储和静态存储的关键在于:这些方法严格地限制了变量的寿命。变量可能存在于程序的整个生命周期(静态变量),也可能只是在特定函数被执行时存在(自动变量)。
3.动态存储
new和delete运算符提供了一种比自动变量和静态变量更灵活的方法。它们管理了一个内存池,这在C++中被称为自由存储空间(free store)或堆(heap)。该内存池同用于静态变量和自动变量的内存是分开的。上面程序清单表明,new和delete让您能够在一个函数中分配内存,而在另一个函数中释放它。因此,数据的生命周期不完全受程序或函数的生存时间控制。与使用常规变量相比,使用new和delete让程序员对程序如何使用内存有更大的控制权。然而,内存管理也更复杂了。在栈中,自动添加和删除机制使得占用的内存总是连续的,但new和delete的相互影响可能导致占用的自由存储区不连续,这使得跟踪新分配内存的位置更困难。
栈、堆和内存泄漏:
如果使用new运算符在自由存储空间(或堆)上创建变量后,没有调用delete,将发生什么情况呢?如果没有调用delete,则即使包含指针的内存由于作用域规则和对象生命周期的原因而被释放,在自由存储空间上动态分配的变量或结构也将继续存在。实际上,将会无法访问自由存储空间中的结构,因为指向这些内存的指针无效(没有可以访问这块内存的方式了)。这将导致内存泄漏。被泄漏的内存将在程序的整个生命周期内都不可使用;这些内存被分配出去,但无法收回。极端情况(不过不常见)是,内存泄漏可能会非常严重,以致于应用程序可用的内存被耗尽,出现内存耗尽错误,导致程序崩溃。另外,这种泄漏还会给一些操作系统或在相同的内存空间中运行的应用程序带来负面影响,导致它们崩溃。即使是最好的程序员和软件公司,也可能导致内存泄漏。要避免内存泄漏,最好是养成这样一种习惯,即同时使用new和delete运算符,在自由存储空间上动态分配内存,随后便释放它。C++智能指针有助于自动完成这种任务,这将在第16章介绍。
创建指针数组:
struct antarctica {
int year;
...
}
antarctica s01, s02, s03;
const antarctica * arp[3] = {&s01, &s02, &s03};*优先及低于[],所以arp是一个指针数组。如:int * arr[3]就是arr数组里面存放的是int类型,则antarctica * apr[3]就是apr数组里面存放的是antarctica *类型。 咋一看,这有点复杂。如何使用该数组来访问数据呢?既然arp是一个指针数组,arp[1]就是一个指针,可将间接成员运算符应用于它,以访问成员:
std::cout << arp[1] -> year << std::endl;可以创建指向上述数组的指针:(由于arp本身就是一个指向元素首地址的指针,而元素也是指针变量,所以必须是指针的指针才能赋值)
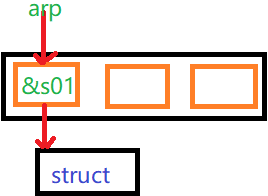
const antarctica ** ppa = arp;
⇒ (*ppa)也是个指针==&s01==arp[0],*(*ppa)==s01=*arp[0]注意:** ppa只是ppa这个变量是指针的指针而已,用ppa这个变量时,与前面的**没有关系,前面的**只是在声明时说明ppa是个指针的指针变量而已,所以ppa+1==&s02。 而arp是数组名,不能arp+1操作!
下面示例演示了C++11版本的auto提供的方便:
auto ppb = arp; // C++11自动类型推论可以这样访问结构成员:
std::cout << (*ppa)->year << std::endl;
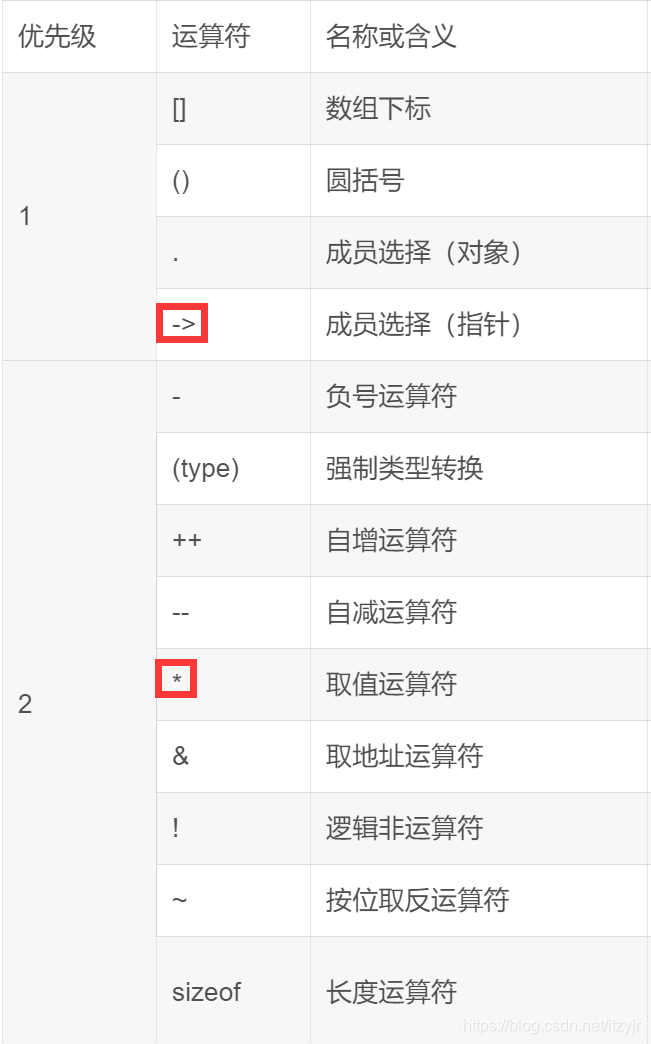
std::cout << (*(ppb+1))->year << std:endl; // *(ppb+1)⇔*(arp+1)由于ppa指向arp的第一个元素,因此*ppa为第一个元素,即&s01。所以,(*ppa)->year为s01的year成员。在第二条语句中,ppb+1指向下一个元素arp[1],即&s02。其中的括号必不可少,这样才能正确地结合。因为*的优先级比->低,所以*ppa->year就是试图将运算符*应用于ppa->year,这将导致错误。
#include <iostream>
struct antarctica {
int year;
/* some really interesting data, etc. */
};
int main() {
antarctica s01, s02, s03;
s01.year = 1998;
antarctica* pa = &s02;
pa->year = 1999;
antarctica trio[3];
trio[0].year = 2003;
std::cout << trio->year << std::endl;
const antarctica* arp[3] = { &s01, &s02, &s03 };
std::cout << arp[1]->year << std::endl;
const antarctica** ppa = arp;
auto ppb = arp; // C++0x automatic type deduction
// or else use const antarctica ** ppb = arp;
std::cout << (*ppa)->year << std::endl;
std::cout << (*(ppb + 1))->year << std::endl;
return 0;
}2003
1999
1998
1999从运行结果:arp[1]->year == (*(ppb+1))->year,可知: arr[1]==*(ppb+1) 。
可以这样用吗?(*(arp++))->year,不能!因为arp是一个const修饰的指针常量,所以自增操作是不允许的。
数组的替代品:
模板类vector和array是数组的替代品。
1.模板类vector:
模板类vector类似于string类,也是一种动态数组。你可以在运行阶段设置vector对象的长度,可在末尾附加新数据,还可在中间插入新数据。基本上,它是使用new创建动态数组的替代品。实际上,vector类确实使用new和delete来管理内存,但这种工作是自动完成的。
#include<vector>
...
using namespace std;
vector<int> vi; // 创建一个元素为0的int数组
int n;
cin >> n;
vector<double> vd(n); // 创建一个有n个元素的double数组
vd.push_back(1);
vd.push_back(2); //把1和2压入vector,这样vd[0]就是1,vd[1]就是2其中,vi是一个vector<int>对象,vd是一个vector<double>对象。由于vector对象在你插入或添加值时自动调整长度,因此可以将vi的初始长度设置为零。但要调整长度,需要使用vector包中的各种方法。
vector<typeName> vt(n_elem);
其中参数n_elem可以是整型常量,也可以是整型变量。2.模板类array(C++11)
vector类的功能比数组强大,但付出的代价是效率稍低。如果你需要的是长度固定的数组,使用数组是更佳的选择,但代价是不那么方便和安全。有鉴于此,C++11新增了模板类array,它也位于名称空间std中。与数组一样,array对象的长度也是固定的,也使用栈(静态内存分配),而不是自由存储区,因此其效率与数组相同,但更方便,更安全。
#include<array>
...
using namespace std;
array<int, 5> ai; // 创建一个包含5个int元素的数组
array<double, 4> ad = {1.2, 2.1, 3.43, 4.3};array<typeName, n_elem> arr;
与创建vector对象不同的是,→→→ n_elem不能是变量! ←←←#include <iostream>
#include <vector> // STL C++98
#include <array> // C++0x
int main() {
using namespace std;
double a1[4] = { 1.2, 2.4, 3.6, 4.8 };
// C++98 STL
vector<double> a2(4); // create vector with 4 elements
// no simple way to initialize in C98
a2[0] = 1.0 / 3.0;
a2[1] = 1.0 / 5.0;
a2[2] = 1.0 / 7.0;
a2[3] = 1.0 / 9.0;
// C++0x -- create and initialize array object
array<double, 4> a3 = { 3.14, 2.72, 1.62, 1.41 };
array<double, 4> a4;
a4 = a3; // valid for array objects of same size
cout << "a1[2]: " << a1[2] << " at " << &a1[2] << endl;
cout << "a2[2]: " << a2[2] << " at " << &a2[2] << endl;
cout << "a3[2]: " << a3[2] << " at " << &a3[2] << endl;
cout << "a4[2]: " << a4[2] << " at " << &a4[2] << endl;
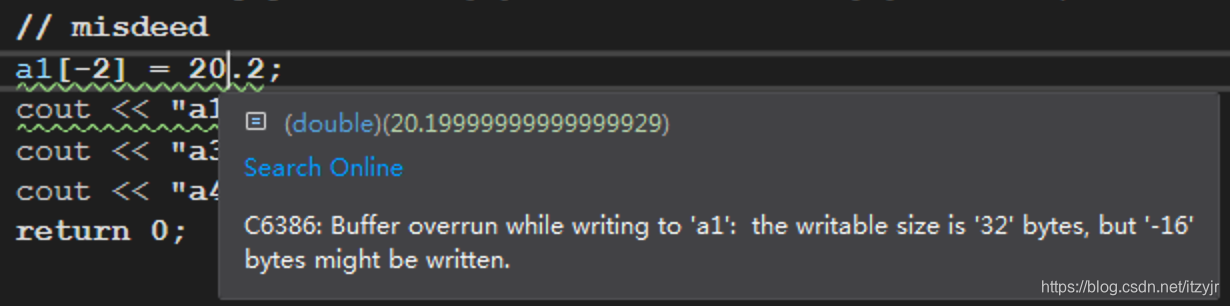
// misdeed(不良行为)
a1[-2] = 20.2;
cout << "a1[-2]: " << a1[-2] << " at " << &a1[-2] << endl;
cout << "a3[2]: " << a3[2] << " at " << &a3[2] << endl;
cout << "a4[2]: " << a4[2] << " at " << &a4[2] << endl;
return 0;
}在VS2019环境下,会有警告:
运行后,出现错误弹窗:
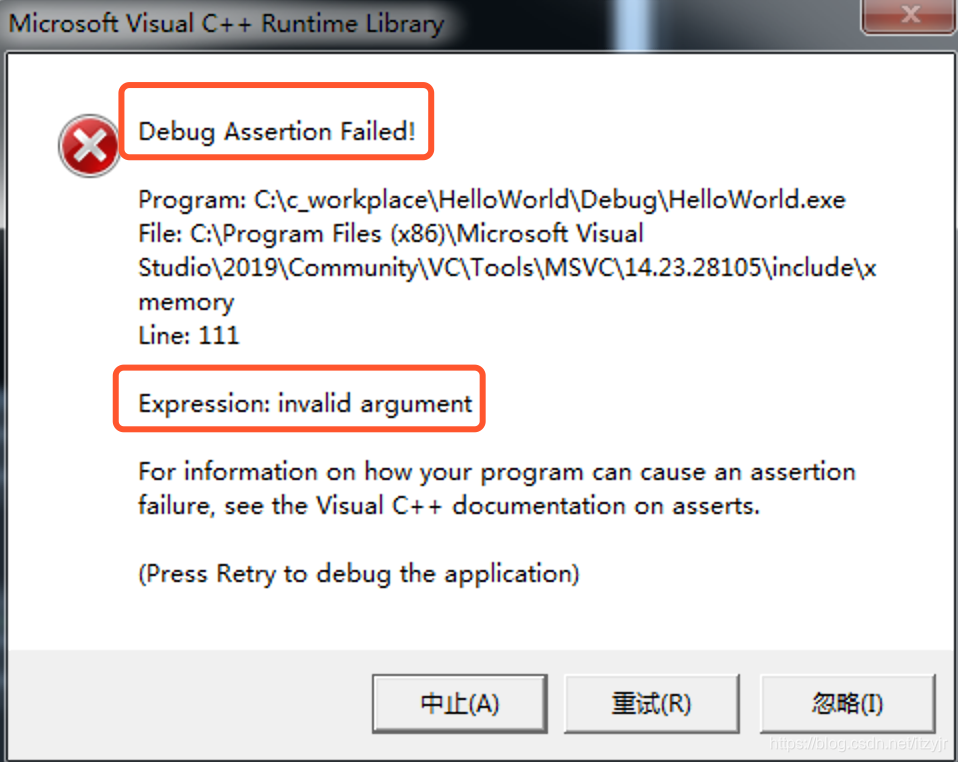
点击“中止”或“忽略”按钮,输出如下:
a1[2]: 3.6 at 0030F950
a2[2]: 0.142857 at 00771908
a3[2]: 1.62 at 0030F910
a4[2]: 1.62 at 0030F8E8
a1[-2]: 20.2 at 0030F930
a3[2]: 1.62 at 0030F910
a4[2]: 1.62 at 0030F8E8首先,注意到无论是数组、vector对象还是array对象,都可使用标准数组表示法来访问各个元素。其次,从地址可知,array对象和数组存储在相同的内存区域(即栈)中,而vector对象存储在另一个区域(自由存储区或堆)中。第三,注意到可以将一个array对象赋给另一个array对象;而对于数组,必须逐元素复制数据。
对于a1[-2]=20.2;索引-2本章前面已经说过,这将转换为:*(a1-2)=20.2,即找到a1指向的地方,向前移两个double元素,并将20.2存储到目的地。也就是说,将信息存储到数组的外面。与C语言一样,C++也不检查这种超界错误。在这个示例中,这个位置位于array对象a3中。其他编译器可能将20.2放在a4中,甚至做出更糟糕的选择。这表明数组的行为是不安全的。
vector和array对象能够禁止这种行为吗?如果您让它们禁止,它们就能禁止。也就是说,你仍可编写不安全的代码,如下所示:
a2[-2] = .5;
a3[200] = 1.4;然而,你还有其他选择。一种选择是使用成员函数at()。就像可以使用cin对象的成员函数getline()一样,你也可以使用vector和array对象的成员函数at():
a2.at(1) = 2.3; // 将2.3赋值给a2[1]中括号表示法和成员函数at()的差别在于,使用at()时,将在运行期间捕获非法索引,而程序默认将中断。这种额外检查的代价是运行时间更长,这就是C++让允许你使用任何一种表示法的原因所在。另外,这些类还让你能够降低意外超界错误的概率。


















 1681
1681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











