





C++提供了一种灵活的标准,它确保了最小长度(从C语言借鉴而来),如下所示:
short 至少16位;
int 至少与short一样长;
long 至少32位,且至少与int一样长;
long long 至少64位,且至少与long一样长。如果要以十六进制或八进制方式显示值,则可以使用cout的一些特殊特性。前面指出过,头文件iostream提供了控制符endl,用于指示cout重起一行。同样,它还提供了控制符dec、hex和oct,分别用于指示cout以十进制、十六进制和八进制格式显示整数。
#include <iostream>
using namespace std;
int main() {
int chest = 42;
int waist = 42;
int inseam = 42;
cout << "Monsieur cuts a striking figure!" << endl;
cout << "chest = " << chest << " (decimal for 42)" << endl;
cout << hex;
cout << "waist = " << waist << " (hexadecimal for 42)" << endl;
cout << oct;
cout << "inseam = " << inseam << " (octal for 42)" << endl;
// cin.get();
return 0;
}Monsieur cuts a striking figure!
chest = 42 (decimal for 42)
waist = 2a (hexadecimal for 42)
inseam = 52 (octal for 42)控制符hex实际上是一条消息,告诉cout采取何种行为。另外,由于标识符hex位于名称空间std中,而程序使用了该名称空间,因此不能将hex用作变量名。然而,如果省略编译指令using,而使用std::cout、std::endl、std::hex和std::oct,则可以将hex用作变量名。

可以这样使用,代码更清晰:
// modify basefield
#include <iostream> // std::cout, std::dec, std::hex, std::oct
int main () {
int n = 70;
std::cout << std::dec << n << '\n';
std::cout << std::hex << n << '\n';
std::cout << std::oct << n << '\n';
return 0;
}C++如何确定常量的类型:
程序的声明将特定的整型变量的类型告诉了C++编译器,但编译器是如何知道常量的类型呢?假设在程序中使用常量表示一个数字:
cout << "Year = " << 1492 << "\n";程序将把1492存储为int、long还是其他整型呢?答案是,除非有理由存储为其他类型(如使用了特殊的后缀来表示特定的类型,或者值太大,不能存储为int),否则C++将整型常量存储为int类型。
首先来看看后缀。后缀是放在数字常量后面的字母,用于表示类型。整数后面的l或L后缀表示该整数为long常量,u或U后缀表示unsigned int常量,ul(可以采用任何一种顺序,大写小写均可)表示unsigned long常量(由于小写l看上去像1,因此应使用大写L作后缀)。例如,在int为16位、long为32位的系统上,数字22022被存储为int,占16位,数字22022L被存储为long,占32位。同样,22022LU和22022UL都被存储为unsigned long。C++11提供了用于表示类型long long的后缀ll和LL,还提供了用于表示类型unsigned long long的后缀ull、Ull、uLL和ULL。
接下来考察长度。在C++中,对十进制整数采用的规则,与十六进制和八进制稍微有些不同。对于不带后缀的十进制整数,将使用下面几种类型中能够存储该数的最小类型来表示:int、long或long long。在int为16位、long为32位的计算机系统上,20000被表示为int类型,40000被表示为long类型,3000000000被表示为long long类型。对于不带后缀的十六进制或八进制整数,将使用下面几种类型中能够存储该数的最小类型来表示:int、unsigned int long、unsigned long、long long或unsigned long long。在将40000表示为long的计算机系统中,十六进制数0x9C40(40000)将被表示为unsigned int。这是因为十六进制常用来表示内存地址,而内存地址是没有符号的,因此,usigned int比long更适合用来表示16位的地址。
char类型:字符和小整数
char类型是另一种整型。它足够长,能够表示目标计算机系统中的所有基本符号—所有的字母、数字、标点符号等。实际上,很多系统支持的字符都不超过128个,因此用一个字节就可以表示所有的符号。因此,虽然char最常被用来处理字符,但也可以将它用做比short更小的整型。
在美国,最常用的符号集是ASCII字符集。字符集中的字符用数值编码(ASCII码)表示。例如,字符A的编码为65,字母M的编码为77。为方便起见,本书在示例中使用的是ASCII码。然而,C++实现使用的是其主机系统的编码—例如,IBM大型机使用EBCDIC编码。ASCII和EBCDIC都不能很好地满足国际需要,C++支持的宽字符类型可以存储更多的值,如国际Unicode字符集使用的值。这就要使用wchat_t类型(稍后介绍)。
#include <iostream>
int main() {
using namespace std;
char ch = 'M';
int i = ch;
cout << "The ASCII code for " << ch << " is " << i << endl;
cout << "Add one to the character code:" << endl;
ch = ch + 1;
i = ch;
cout << "The ASCII code for " << ch << " is " << i << endl;
cout << "Displaying char ch using cout.put(ch): ";
cout.put(ch);
cout.put('!');
cout << endl << "Done" << endl;
return 0;
}The ASCII code for M is 77
Add one to the character code:
The ASCII code for N is 78
Displaying char ch using cout.put(ch): N!
Done函数cout.put()是一个重要的C++ OOP概念—成员函数—的第一个例子。类定义了如何表示和控制数据。成员函数归类所有,描述了操纵类数据的方法。例如类ostream有一个put()成员函数,用来输出字符。只能通过类的特定对象(例如这里的cout对象)来使用成员函数。要通过对象(如cout)使用成员函数,必须用句点将对象名和函数名称(put())连接起来。句点被称为成员运算符。cout.put( )的意思是,通过类对象cout来使用函数put( )。


—— —— —— — ——— —— —— —— —— ——— ——— ——— —— —— — ——


—— —— —— — ——— —— —— —— —— ——— ——— ——— —— —— — ——
在Release 2.0之前,cout << '$';打印的是$的ASCII码,Release 2.0之后,cout << '$'; 与 cout.put('$'); 打印结果一致。
通用字符名:
通用字符名的用法类似于转义序列。通用字符名可以以\u或\U打头。\u后面是8个十六进制位,\U后面则是16个十六进制位。这些位表示的是字符的ISO 10646码点(ISO 10646是一种正在制定的国际标准,为大量的字符提供了数值编码,请参见本章后面的“Unicode和ISO 10646”)。
如果所用的实现支持扩展字符,则可以在标识符(如字符常量)和字符串中使用通用字符名。例如,请看下面的代码:
int k\u00F6rper
cout << "Let them eat g\u00E2teau.\n";ö的ISO 10646码点为00F6,而â的码点为00E2。因此,上述C++代码将变量名设置为körper,并显示下面的输出:
Let them eat gâteau.如果系统不支持ISO 10646,它将显示其他字符或gu00E2teau,而不是â。
所有字符Unicode编码都可以在 52 Unicode 查询到。如:

 点击底部链接可以跳转到详细页,如:
点击底部链接可以跳转到详细页,如:
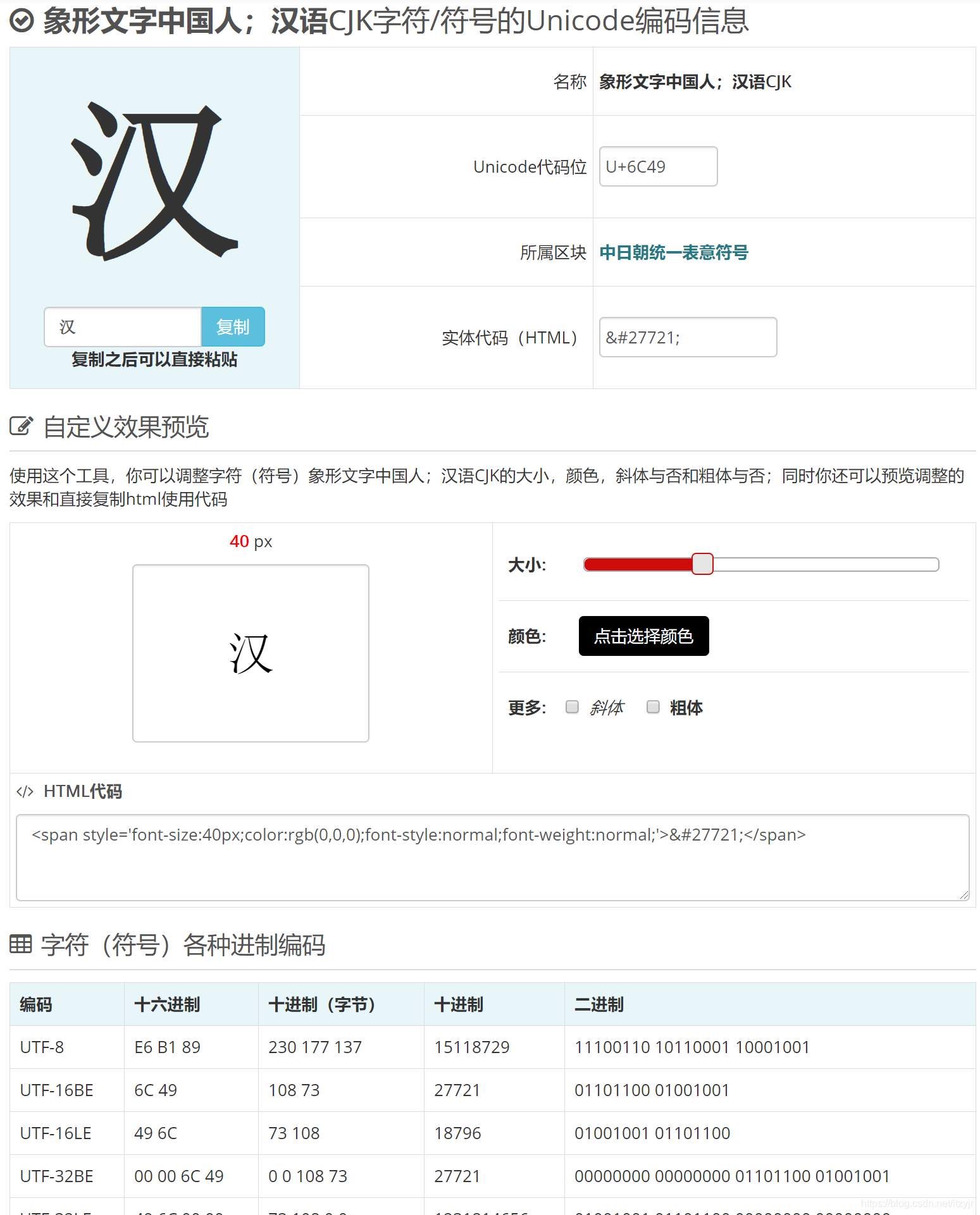
请注意,C++使用术语“通用编码名”,而不是“通用编码”,这是因为应将\u00F6解释为“Unicode码点为U-00F6的字符”。支持Unicode的编译器知道,这表示字符ö,但无需使用内部编码00F6。无论计算机使用是ASCII还是其他编码系统,都可在内部表示字符T;同样,在不同的系统中,将使用不同的编码来表示字符ö。在源代码中,可使用适用于所有系统的通用编码名,而编译器将根据当前系统使用合适的内部编码来表示它。
Unicode和ISO 10646:
Unicode提供了一种表示各种字符集的解决方案—为大量字符和符号提供标准数值编码,并根据类型将它们分组。例如,ASCII码为Unicode的子集,因此在这两种系统中,美国的拉丁字符(如A和Z)的表示相同。然而,Unicode还包含其他拉丁字符,如欧洲语言使用的拉丁字符、来自其他语言(如希腊语、西里尔语、希伯来语、切罗基语、阿拉伯语、泰语和孟加拉语)中的字符以及象形文字(如中国和日本的文字)。到目前为止,Unicode可以表示109000多种符号和90多个手写符号(script),它还在不断发展中。
Unicode给每个字符指定一个编号—码点。Unicode码点通常类似于下面这样:U-222B。其中U表示这是一个Unicode字符,而222B是该字符(积分正弦符号)的十六进制编号。
国际标准化组织(ISO)建立了一个工作组,专门开发ISO 10646—这也是一个对多种语言文本进行编码的标准。ISO 10646小组和Unicode小组从从1991年开始合作,以确保他们的标准同步。
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。目前的Unicode字符分为17组编排,0x0000 至 0x10FFFF,每组称为平面(Plane),而每平面拥有65536个码位,共1114112个。然而目前只用了少数平面。UTF-8、UTF-16、UTF-32都是将数字转换到程序数据的编码方案。
通用字符集(Universal Character Set, UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的标准字符集。UCS 包含了表示几乎所有已知的语言所必需的字符。UCS-2用两个字节编码,UCS-4用4个字节编码。
以"I am Chinese"为例:
-用ANSI储存:12 Bytes
-用Unicode/UCS2储存:24 Bytes + 2 Bytes(header)
-用UCS4储存:48 Bytes + 4 Bytes(header)
以"我是中国人"为例:
-用ANSI储存:10 Bytes
-用Unicode/UCS2储存:10 Bytes + 2 Bytes(header)
-用UCS4储存:20 Bytes + 4 Bytes(header)
wcha_t类型:
一种实现可以同时支持一个小型基本字符集和一个较大的扩展字符集。8位char可以表示基本字符集,另一种类型wchar_t(宽字符类型)可以表示扩展字符集。wchar_t类型是一种整数类型,它有足够的空间,可以表示系统使用的最大扩展字符集。这种类型与另一种整型(底层(underlying)类型)的长度和符号属性相同。对底层类型的选择取决于实现,因此在一个系统中,它可能是unsigned short,而在另一个系统中,则可能是int。
cin和cout将输入和输出看作是char流,因此不适于用来处理wchar_t类型。iostream头文件的最新版本提供了作用相似的工具—wcin和wcout,可用于处理wchar_t流。另外,可以通过加上前缀L来指示宽字符常量和宽字符串。
wcha_t bob = L'P';
wcout << L"tall" << endl;以上代码将字母P的wcha_t版本存储到变量bob中,并显示单词tall的wcha_t版本。
在支持两字节wchar_t的系统中,上述代码将把每个字符存储在一个两个字节的内存单元中。本书不使用宽字符类型,但读者应知道有这种类型,尤其是在进行国际编程或使用Unicode或ISO 10646时。
C++11新增类型:chat16_t和chat32_t
在Unicode中:汉字“字”对应的数字是23383(十进制),十六进制表示为5B57。在Unicode中,我们有很多方式将数字23383表示成程序中的数据,包括:UTF-8、UTF-16、UTF-32。UTF是“Unicode Transformation Format”的缩写,可以翻译成Unicode字符集转换格式,即怎样将Unicode定义的数字转换成程序数据。
例如,“汉字”对应的数字是0x6c49和0x5b57,而编码的程序数据是:(1位十六进制=4位二进制数)
char data_utf8[]={0xE6,0xB1,0x89,0xE5,0xAD,0x97};//UTF-8编码
char16_t data_utf16[]={0x6C49,0x5B57}; //UTF-16编码
char32_t data_utf32[]={0x00006C49,0x00005B57};//UTF-32编码进行字符串编码时,如果有特定长度和符号特征的类型,将很有帮助,而类型wchar_t的长度和符号特征随实现而已。因此,C++11新增了类型char16_t和char32_t,其中前者是无符号的,长16位,而后者也是无符号的,但长32位。C++11使用前缀u表示char16_t字符常量和字符串常量,如u‘C’和u“be good”;并使用前缀U表示char32_t常量,如U‘R’和U“dirty rat”。类型char16_t与/u00F6形式的通用字符名匹配,而类型char32_t与/U0000222B形式的通用字符名匹配。前缀u和U分别指出字符字面值的类型为char16_t和char32_t:
chat16_t ch1 = u'q';
char32_t ch2 = U'\U000022B';与wchar_t一样,char16_t和char32_t也都有底层类型—一种内置的整型,但底层类型可能随系统而已。
bool类型:
bool is_ready = true;字面值true和false都可以通过提升转换为int类型,true被转换为1,而false被转换为0:
int ans = true; // ans == 1;
int promise = false; // promise == 0另外,任何数字值或指针值都可以被隐式转换(即不用显式强制转换)为bool值。任何非零值都被转换为true,而零被转换为false:
bool start = -100; // start == true
bool stop = 0; // stop == false如果以前使用过C语言,您可能觉得前面讨论的#define语句已经足够完成这样的工作了。但const比#define好。首先,它能够明确指定类型。其次,可以使用C++的作用域规则将定义限制在特定的函数或文件中(作用域规则描述了名称在各种模块中的可知程度)。第三,可以将const用于更复杂的类型,如数组和结构。
如果读者在学习C++之前学习过C语言,并打算使用#define来定义符号常量,请不要这样做,而应使用const。
浮点类型:
有两种书写浮点数的方式:
1.常用的标准小数点表示法:12.34、939001.32、0.00023、8.0
2.E表示法:3.45E6=3.45*10^6、-18.23e13=-18.23*10^13、8.33E-4=8.33*10^-4
C++有3种浮点类型:float、double、long double。float至少32位、double至少48位且不少于float、long double至少和double一样多。
#include <iostream>
int main() {
using namespace std;
cout.setf(ios_base::fixed, ios_base::floatfield); ←fixed-point,即覆盖默认的删除尾部0行为
float tub = 10.0 / 3.0; // good to about 6 places
double mint = 10.0 / 3.0; // good to about 15 places
const float million = 1.0e6;
cout << "tub = " << tub;
cout << ", a million tubs = " << million * tub;
cout << ",\nand ten million tubs = ";
cout << 10 * million * tub << endl;
cout << "mint = " << mint << " and a million mints = ";
cout << million * mint << endl;
return 0;
}tub = 3.333333, a million tubs = 3333333.250000,
and ten million tubs = 33333332.000000
mint = 3.333333 and a million mints = 3333333.333333通常cout会删除结尾的零。例如,将3333333.250000显示为3333333.25。调用cout.setf( )将覆盖这种行为,至少在新的实现中是这样的。
这里要注意的是,为何float的精度比double低。tub和mint都被初始化为10.0/3.0—3.333333333333333333……由于cout打印6位小数,因此tub和mint都是精确的。但当程序将每个数乘以一百万后,tub在第7个3之后就与正确的值有了误差。tub在7位有效位上还是精确的(该系统确保float至少有6位有效位,但这是最糟糕的情况)。然而,double类型的变量显示了13个3,因此它至少有13位是精确的。由于系统确保15位有效位,因此这就没有什么好奇怪的了。另外,将tub乘以一百万,再乘以10后,得到的结果不正确,这再一次指出了float的精度限制。
在程序中书写浮点常量的时候,程序将把它存储为哪种浮点类型呢?在默认情况下,像8.24和2.4E8这样的浮点常量都属于double类型。如果希望常量为float类型,请使用f或F后缀。对于long double类型,可使用l或L后缀。如:1.234F(float)、2.345321E28(double)、2.2L(long double)。
#include <iostream>
int main() {
using namespace std;
float a = 2.34E+22f;
float b = a + 1.0f;
cout << "a = " << a << endl;
cout << "b - a = " << b - a << endl;
return 0;
}
a = 2.34E+022
b - a = 02.34E+22是一个小数点左边有23位的数字。加上1,就是在第23位加1。但float类型只能表示数字中的前6位或前7位,因此修改第23位对这个值不会有任何影响。
因为数据类型float只能保留7位有效位
a=2.34E+22f表示a=2340 0000 0000 0000 0000 000有23位有效位,
b=a+1.0f表示 b=23400000000000000000001有23位有效位,
保留7位有效位后,a=b=2340000×10^16=2.34E+22
把22改成6就正确了,改成7就马上错了。如果把float a改为long double = 2.34E+22L,float b也改为long double则运行也正确。
注:9/5 = 1,9.0/5 = 1.800000。整型常量默认为int型,浮点常量默认为double型。
 整数默认是int,浮点数默认double!
整数默认是int,浮点数默认double!
C++除了C的强制转换类型外,还引入了4个强制类型转换运算符,其中一个static_cast<>可用于将值从一种数值类型转换为另一种数值类型:static_cast<type> (value)(将value转换为type类型)
如:static_case<long>(thorn);将thron强制转换为long类型。
C语言式的强制类型转换由于有过多的可能性而极其危险,运算符static_cast<>比传统强制类型转换更严格。
#include <iostream>
using namespace std;
int main() {
int auks, bats, coots;
auks = 19.99 + 11.99; // double相加,转换为int
bats = (int) 19.99 + (int) 11.99; // old C syntax
coots = int (19.99) + int (11.99); // new C++ syntax
cout << "auks = " << auks << ", bats = " << bats;
cout << ", coots = " << coots << endl;
char ch = 'Z';
cout << "The code for " << ch << " is ";
cout << int(ch) << endl;
cout << "Yes, the code is ";
cout << static_cast<int>(ch) << endl;
return 0;
}auks = 31, bats = 30, coots = 30
The code for Z is 90
Yes, the code is 90C++11中的auto声明:
C++11新增了一个工具,让编译器能够根据初始值的类型推断变量的类型。为此,它重新定义了auto的含义。auto是一个C语言关键字,但很少使用。在初始化声明中,如果使用关键字auto,而不指定变量的类型,编译器将把变量的类型设置成与初始值相同:
auto n = 100; // n是int
auto x = 1.5; // x是double
auto y = 1.3e12L; // y是long double处理复杂类型,如标准模块库(STL)中的类型时,自动类型推断才能显现出功效。如:
std::vector<double> scores;
std::vector<double>::iterator pv = scores.begin();
在C++11允许你将其重写为:
std::vector<double> scores;
auto pv = scores.begin();

















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











