







论文链接:DragNUWA: Fine-grained Control in Video Generation by Integrating Text, Image, and Trajectory
代码:https://github.com/ProjectNUWA/DragNUWA

一、简介
中国科学技术大学+微软亚洲研究院 在 NUWA多模态模型、 Stable Video Diffusion 、UniMatch基础上提出的可控视频合成方法

提出了同时(simultaneously )引入文本、图像和轨迹信息,从语义(semantic)、空间(spatial)和时间角度(temporal perspectives) 对视频内容进行·细粒度控制(fine-grained control)。。
为了解决当前研究中开放域轨迹控制(open-domain trajectory control )限制的问题,我们提出了三个方面的轨迹建模
一个轨迹采样器(TS,a Trajectory Sampler):保证任意轨迹(arbitrary trajectories,)的开放域控制
一个多尺度融合(MF,a Multiscale Fusion):不同细粒度(granularities)的控制轨迹
自适应训练策略(AT, Adaptive Training): 生成一致的(consistent)的视频。

二、主要方法
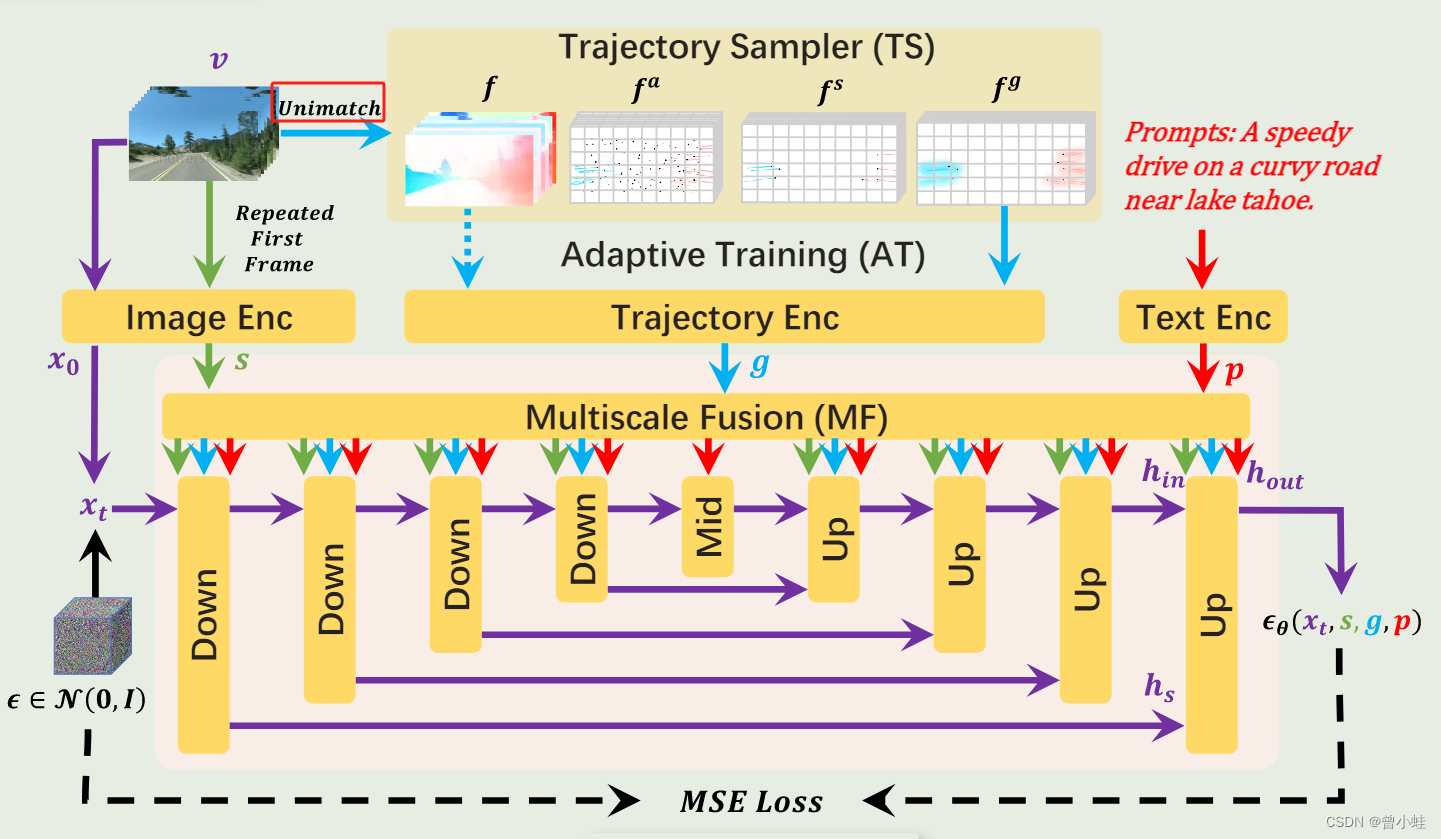
DragNUWA训练流程概述。DragNUWA支持三种可选输入:文本p、图像s和轨迹g,并专注于从三个方面设计轨迹。首先,轨迹采样器(TS)从开放域视频流中动态采样轨迹。其次,多尺度融合(MF)将轨迹与UNet架构的每个块中的文本和图像深度集成。最后,自适应训练(AT)将模型从光流条件调整为用户友好的轨迹。最终,DragNUWA能够处理具有多个对象及其复杂轨迹的开放域视频。
三、相关工作(需要的知识储备)
其中 Stable Video Diffusion (开源)未在论文中出现,但是最近模型是根据其优化的
- 21.11.
NUWA: 微软提出神经视觉世界创造的视觉合成预训练模型 Visual Synthesis Pre-training for Neural visUal World
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1346
1346

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











