




 本文梳理了从ELMO到BERT、XLNet、ERNIE、BERT-wwm、RoBERTa、ERNIE2.0和BERT-wwm-ext的发展历程,重点讨论了ALBERT如何通过参数共享和因式分解减少参数,提升模型效率。
本文梳理了从ELMO到BERT、XLNet、ERNIE、BERT-wwm、RoBERTa、ERNIE2.0和BERT-wwm-ext的发展历程,重点讨论了ALBERT如何通过参数共享和因式分解减少参数,提升模型效率。

摘要:BERT中及XLNet和RoBERTa中,词嵌入大小 E 和隐藏层大小 H 相等的,H =E=768;而ALBERT认为,词嵌入学习单个词的信息,而隐藏层输出包含上下文信息,应该 H>>E。所以ALBERT的词向量的维度小于encoder输出值维度 ...
人工智能学习离不开实践的验证,推荐大家可以多在FlyAI-AI竞赛服务平台多参加训练和竞赛,以此来提升自己的能力。FlyAI是为AI开发者提供数据竞赛并支持GPU离线训练的一站式服务平台。每周免费提供项目开源算法样例,支持算法能力变现以及快速的迭代算法模型。
本文的主要目的是理清时间线,关注预训练的发展过程,进行模型间的联系和对比,具体原理和细节请参考原论文和代码,不再一一赘述。
『预训练模型的时间线』
ELMO 2018.03 华盛顿大学
GPT 2018.06 OpenAI
BERT 2018.10 Google
XLNet 2019.6 CMU+google
ERNIE 2019.4 百度
BERT-wwm 2019.6 哈工大+讯飞
RoBERTa 2019.7.26 Facebook
ERNIE2.0 2019.7.29 百度
BERT-wwm-ext 2019.7.30 哈工大 +讯飞
ALBERT 2019.10 Google
(文末附相关论文及模型代码)

『预训练语言模型分类 』
单向特征、自回归模型(单向模型):
ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0
双向特征、自编码模型(BERT系列模型):
BERT/ERNIE/SpanBERT/RoBERTa
双向特征、自回归模型“
XLNet
『各模型之间的联系 』
传统word2vec无法解决一词多义,语义信息不够丰富,诞生了ELMO
ELMO以lstm堆积,串行且提取特征能力不够,诞生了GPT
GPT 虽然用transformer堆积,但是是单向的,诞生了BERT
BERT虽然双向,但是mask不适用于自编码模型,诞生了XLNET
BERT中mask代替单个字符而非实体或短语,没有考虑词法结构/语法结构,诞生了ERNIE
为了mask掉中文的词而非字,让BERT更好的应用在中文任务,诞生了BERT-wwm
Bert训练用更多的数据、训练步数、更大的批次,mask机制变为动态的,诞生了RoBERTa
ERNIE的基础上,用大量数据和先验知识,进行多任务的持续学习,诞生了ERNIE2.0
BERT-wwm增加了训练数据集、训练步数,诞生了BERT-wwm-ext
BERT的其他改进模型基本考增加参数和训练数据,考虑轻量化之后,诞生了ALBERT
「 1.ELMO 」
“Embedding from Language Models"
NAACL18 Best Paper
特点:传统的词向量(如word2vec)是静态的/上下文无关的,而ELMO解决了一词多义;ELMO采用双层双向LSTM
缺点:lstm是串行,训练时间长;相比于transformer,特征提取能力不够(ELMO采用向量拼接)
使用分为两阶段:预训练+应用于下游任务,本质就是根据当前上下文对Word Embedding进行动态调整的过程:
1. 用语言模型进行预训练

左边的前向双层LSTM是正方向编码器,顺序输入待预测单词w的上文;右边则是反方向编码器,逆序输入w的下文
训练好之后,输入一个新句子s,每个单词都得到三个Embedding:①单词的Word Embedding ②第一层关于单词位置的Embedding ②第二层带有语义信息的Embedding(上述的三个Embedding 、LSTM网络结果均为训练结果)
2. 做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。 如QA任务:输入Q/A句子,对三个Embedding分配权重,整合生成新的Embedding
「 2.GPT 」
“Generative Pre-Training”
优点:Transformer捕捉更长范围的信息,优于RNN;并行,快速
缺点:需要对输入数据的结构调整;单向

GPT模型图
特点:
依然两段式:单向语言模型预训练(无监督)+fine tuning应用到下游任务(有监督)
自回归模型
transformer的decoder里面有三个子模块,GPT只用了第一个和第三个子模块,如下图:

与ELMO的不同:
GPT只用了transformer的decoder模块提取特征,而不是Bi-LSTM;堆叠12个
单向(根据上文预测单词,利用mask屏蔽下文)
GPT中的mask如下图所示,mask之后要进行softmax:
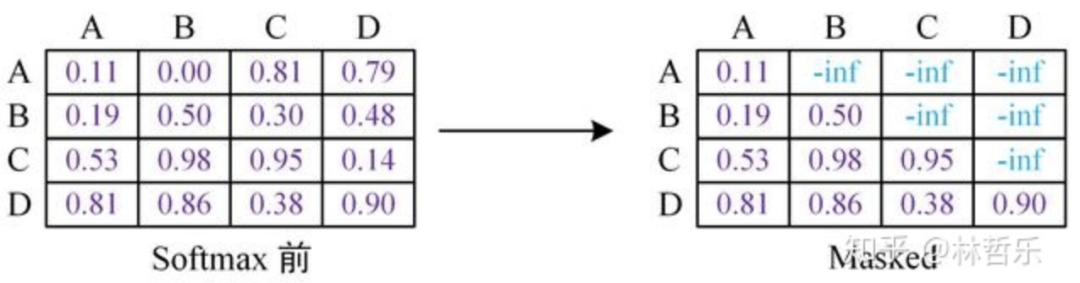
mask操作
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2057
2057

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









