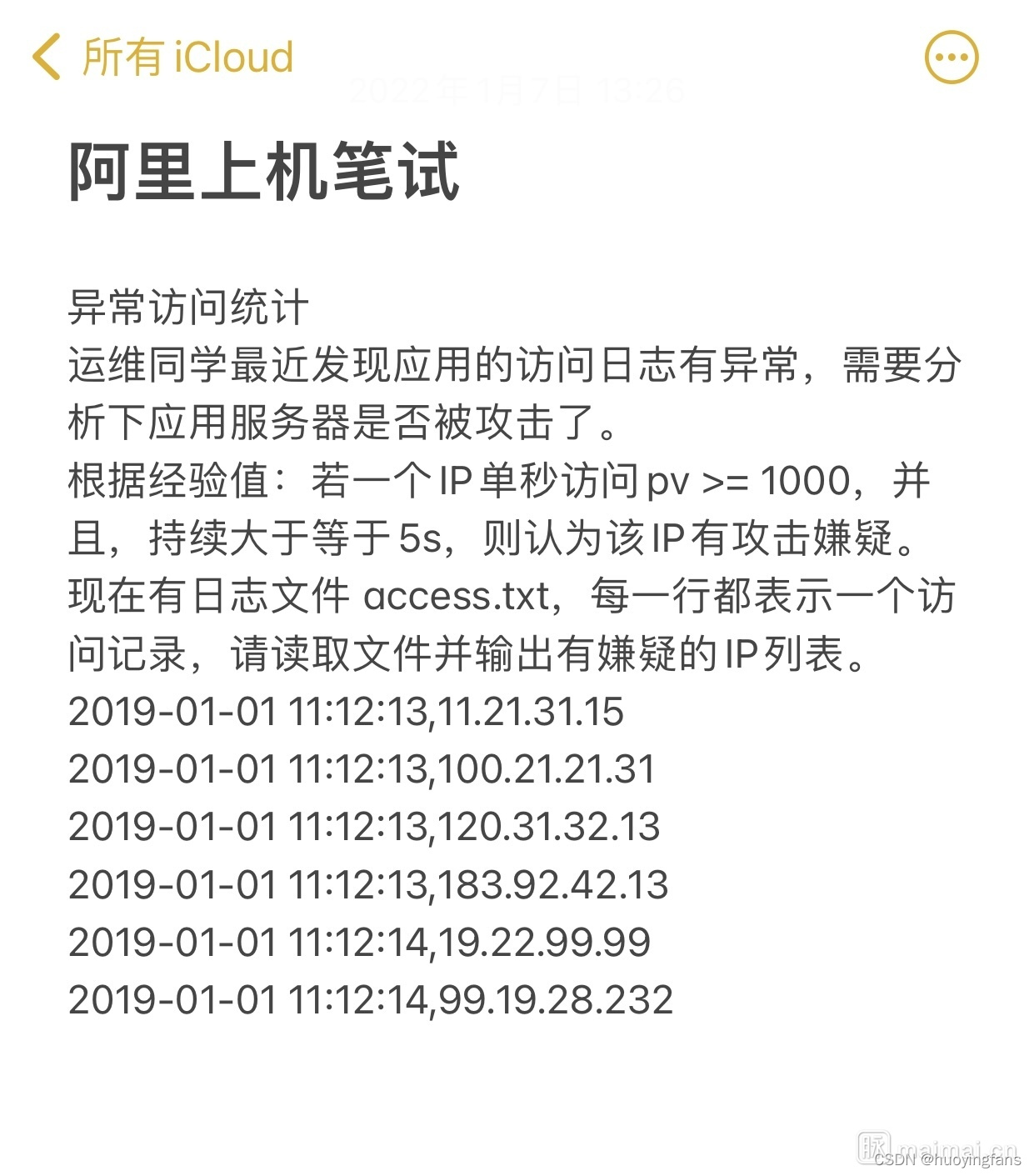
| 阿里上机笔试
异常访问统计
运维同学最近发现应用的访问日志有异常,需要分析下应用服务器是否被攻击了。
根据经验值:若一个IP单秒访问pv >= 1000,并且,持续大于等于5s,则认为该IP有攻击嫌疑。
现在有日志文件 access.txt,每一行都表示一个访问记录,请读取文件并输出有嫌疑的IP列表。
|
https://maimai.cn/web/feed_detail?fid=1699171070&efid=Re5wP9K4Ixu-Q0ABjKQ_UA&share_channel=2&webid=eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1IjoxNzg3MTM2MzYsImZpZCI6MTY5OTE3MTA3MH0.XSTNpELbKrIebgkf-Yf4gfooIzIsNwcSX7xKfrWDeD8&use_rn=1
| 滑动窗口 维护前后两个指针、两个hashmap 和一个储存结果的set就可以了 大文件要分割稍微麻烦一点 思想还是一样的
|
| 两个计数map,一个存结果set
一个map统计ip连续多少秒大于1000,另一个map统计当前这一秒的ip计数,假如这一秒有a b c三个ip计数大于1000,
就把a b c的连续计数+1,并把非a b c的连续计数清0,清0前判断连续计数是不是≥5,是就加到结果set
|
双map ,滑动窗口 ,count是负数时 ,-2表示连续2,-3表示连续3
没说文件规模一律认为耍流氓
你可以考虑文件大的情况,也可以考虑文件小和情况
用快慢指针
离线的用sparksql一把撸转成全量的rdd,再用分割flatmap 过滤算count大于阈值输出ip
这不就是字符串分割,统计单词出现次数?
得物App员工:是的,你说的没错,然后怎么做呢
如果是sql,用lag可以实现吧
map里套一个map,外层map的key用ip,里层的map的key用时间,value记录出现次数,然后判断次数是否大于一千以及时间是否有连续超过五次的
用Redis的hash数据结构不就好了。时间+IP作为field
玩awk啊,我敢说就一个分组统计就没几个会的
| 用Java
01-07
评论赞
奇虎360员工
运维的东西开发不会很正常吧
01-10
评论赞
永辉超市员工
回复奇虎360员工:这明显是道算法题
01-18
评论赞
刘梦
奇虎360服务端资深开发
回复永辉超市员工:
|
现在还有这么拉的运维用日志分析有没有被攻击吗?
求教高端运维用啥。
负载均衡按IP怎么做的,等分析日志再做负载黄花菜不都凉了么
map 多线程 极致压榨CPU
| c++我应该是顺序扫一遍文件就可以了,一个线程读文件一个线程序列化。
因为只需要5s的数据,只要内存里能装的下6s的数据问题就不大,析构也可以单独开一个线程。
剩下的就是用哈希map存数据count++然后简单判断而已。
|
| 一个笨点的方法,python解析文本,每一行分割,把ip当作key,访问时间做嵌套的key,value就是出现次数,出现一次就加1。然后解析这个大map,对出现次数和访问时间是否连续做判断
|
不会,p几的题
陈雨:P6-7
小文件的话直接构造arraylist,转成lambda表达式经过若干算子collect一下就可以了
awk sort grep 一把梭,一行命令的事…
小米员工:性能太挫。没这么简单
tail -n 100000 access.txt|awk -F"," '{print $1,$2}'|sort -n |uniq -c|sort -nr |head
陈雨:要出结果,还要连续5秒
| cat文件,通过awk把秒输出、再sort,uniq-c,awk把只有秒的一列去重输出到一个文件,在for循环取秒,grep原文件取到每秒的行,awk ip地址,uniq-c次数、awk大于5000输出
|
| from itertools import groupby
mylog = open('access.txt', 'r')
ips = []
for key, group in groupby(mylog):
ip = key[20:32]
if len(list(group)) >= 1000:
ips.append(ip)
the_ip = []
set_ip = set(ips)
for ip in set_ip:
if ips.count(ip) >= 5:
the_ip.append(ip)
print(the_ip)
如果文件比较大就分割成多个chunk然后多个线程处理
|
| 第一步读取文件,文件每行以,分隔生成数组,取出时间和IP,将时间格式化为Long型,生成Map>,用TreeMap主要是方便KEY可以排序,方便判断连续5s的访问记录
第二步判断过滤IP连续5s的PV>=1000的,符合条件的输出到另一个Map>,这里可以用线程池来提高并发计算速度,每个线程判断一个IP
第三步输出符合条件的IP以及IP在相应时间阶段内的PV描述
|
用flink cep





 本文介绍了一种基于滑动窗口和双哈希表的算法,用于从日志文件中检测异常访问行为。具体而言,该算法能够识别那些在连续5秒内每秒访问次数超过1000次的IP地址。
本文介绍了一种基于滑动窗口和双哈希表的算法,用于从日志文件中检测异常访问行为。具体而言,该算法能够识别那些在连续5秒内每秒访问次数超过1000次的IP地址。

















 716
716

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









