







 SEED RL是一个高效的分布式强化学习框架,能够每秒处理数百万张图片。其基本架构包括CPU组成的Actor进行环境交互,GPU组成的Learner负责推理采样和学习训练。学习过程中,采用批处理机制,通过不同线程进行采样、预取数据和训练。与GA3C、IMPALA和R2D2相比,SEED RL在通信、延迟和效率方面有所优化,支持更大规模的扩展。
SEED RL是一个高效的分布式强化学习框架,能够每秒处理数百万张图片。其基本架构包括CPU组成的Actor进行环境交互,GPU组成的Learner负责推理采样和学习训练。学习过程中,采用批处理机制,通过不同线程进行采样、预取数据和训练。与GA3C、IMPALA和R2D2相比,SEED RL在通信、延迟和效率方面有所优化,支持更大规模的扩展。
SEED RL:Scalable, Efficient Deep-RL,每秒处理数百万张图片的分布式强化学习框架。
目录
基本架构
- Actor由大量CPUs组成,只进行环境交互,不再进行推理采样。
- Learner由GPU组成,高度的算力集中,完成推理采样、数据存储及学习训练。
- 基本结构和GA3C很相似。
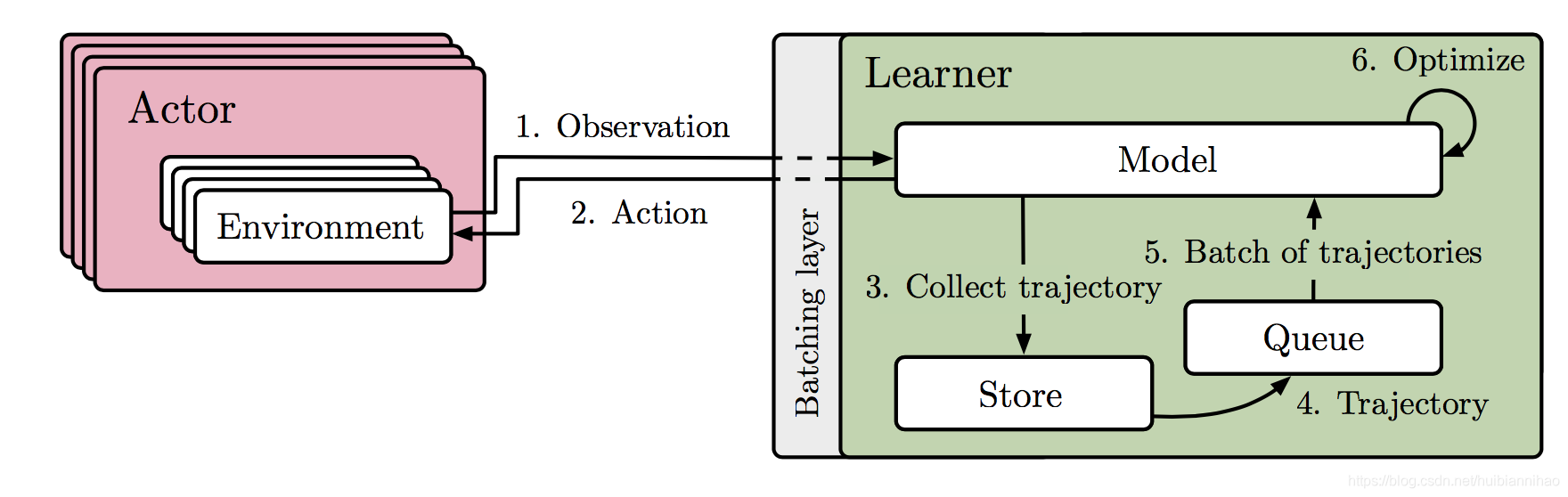
学习过程
- 整体采用批处理机制,批量采样、批量学习。
- Inference thread是While True Thread,负责生成π(a|s)并保存trajectories (s, a, r, s')。
- Data prefetching也是While True Thread,当trajectories完成时,通过quene存入replay buffer。
- Training thead也是While True Thread
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1197
1197

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









