




 本教程深入讲解SQL窗口函数,包括直接使用、添加Orderby和Partition by的效果,以及ROW_NUMBER、RANK的区别。内容涵盖窗口函数在聚合、运行平均值计算、百分位数分析等场景的应用,助你提升数据分析能力。
本教程深入讲解SQL窗口函数,包括直接使用、添加Orderby和Partition by的效果,以及ROW_NUMBER、RANK的区别。内容涵盖窗口函数在聚合、运行平均值计算、百分位数分析等场景的应用,助你提升数据分析能力。
06 /数据分析与SQL/ Lesson6 (选修) SQL 窗口函数
文章目录
2.视频:窗口函数 1
详细可以参考,介绍的很详细:/PostgreSQL’s 文档/
窗口函数有些像聚合函数,区别是窗口函数不会像聚合那样把每一类做一行输出,而依然是每行输出,这就能在一个表格中提供更多的数据,比如说下面这个官网的数据(注意OVER是窗口函数的标志):
直接使用窗口函数:
可以看到只是增加了一列,这列是所有salary的sum,对比salary和sum,可以看到每个员工的工资和总工资支出的对比。
SELECT salary, sum(salary) OVER () FROM empsalary;
salary | sum
--------+-------
5200 | 47100
5000 | 47100
3500 | 47100
4800 | 47100
3900 | 47100
4200 | 47100
4500 | 47100
4800 | 47100
6000 | 47100
5200 | 47100
(10 rows)
增加Orderby:
增加了orderby,就相当于把orderby内的salary排序,并且逐渐加和。这种方式在计算现金流的时候就很有用,可以看按照时间顺序,每笔损益给现金流带来的影响。
SELECT salary, sum(salary) OVER (ORDER BY salary) FROM empsalary;
salary | sum
--------+-------
3500 | 3500
3900 | 7400
4200 | 11600
4500 | 16100
4800 | 25700
4800 | 25700
5000 | 30700
5200 | 41100
5200 | 41100
6000 | 47100
(10 rows)
增加partition by
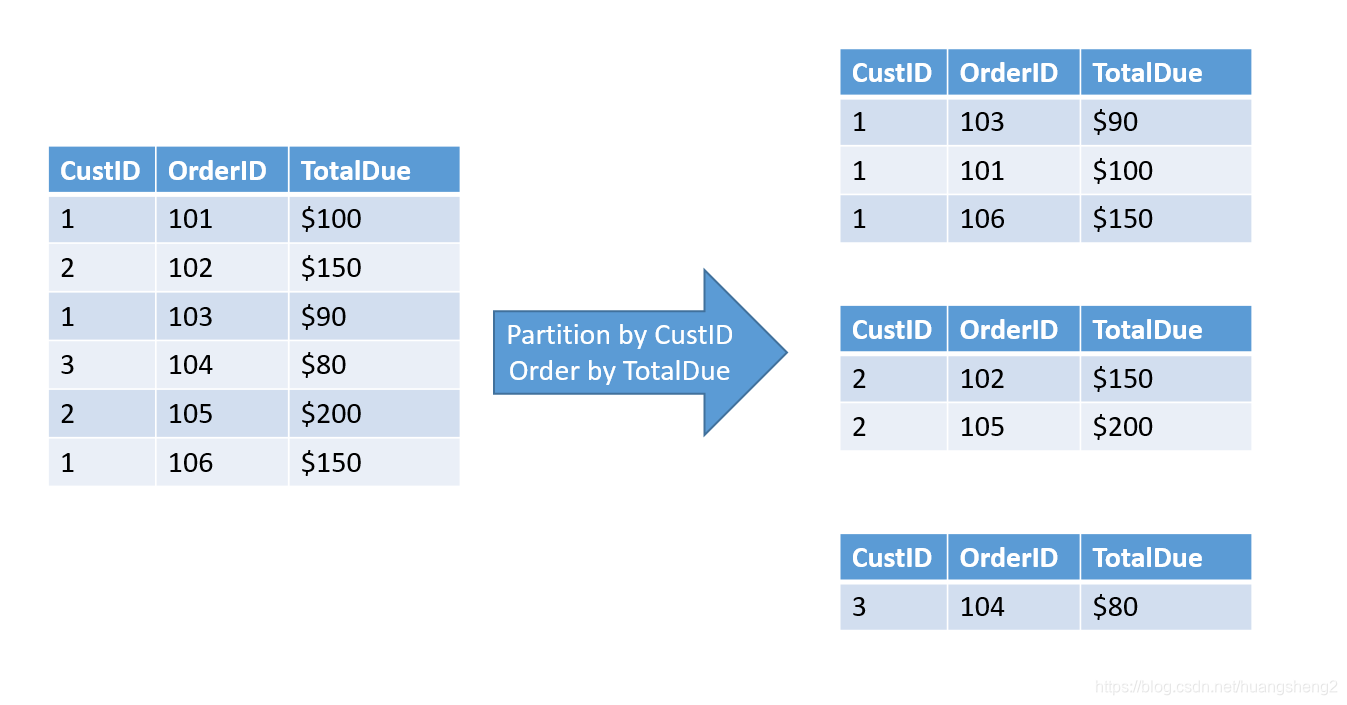
如果在over中增加partition by,则可以进一步拆分为小组,比如官网的这个例子,可以看出develop部门的ave工资是5020,personnel的平均工资是3700等等,这样在比较时就有了更详细的资料。
SELECT depname, empno, salary, avg(salary) OVER (PARTITION BY depname) FROM empsalary;
depname | empno | salary | avg
-----------+-------+--------+-----------------------
develop | 11 | 5200 | 5020.0000000000000000
develop | 7 | 4200 | 5020.0000000000000000
develop | 9 | 4500 | 5020.0000000000000000
develop | 8 | 6000 | 5020.0000000000000000
develop | 10 | 5200 | 5020.0000000000000000
personnel | 5 | 3500 | 3700.0000000000000000
personnel | 2 | 3900 | 3700.0000000000000000
sales | 3 | 4800 | 4866.6666666666666667
sales | 1 | 5000 | 4866.6666666666666667
sales | 4 | 4800 | 4866.6666666666666667
(10 rows)
小节
最后,我们通过课程链接额外链接/Pinal Dave 提供的此资源/ 中的两张图做下小结Partion和Orderby在Over中的用处:

6.解决方案:窗口函数2
这里提供链接的第二个答案十分欢乐的解释了什么时候会用到窗口函数:/Oracle “Partition By” Keyword/
- Boss says “get me number of items we have in stock grouped by brand”
You say: “no problem”
SELECT BRAND ,COUNT(ITEM_ID) FROM ITEMS GROUP BY BRAND;
Result:
+--------------+---------------+
| Brand | Count |
+--------------+---------------+
| H&M | 50 |
+--------------+---------------+
| Hugo Boss | 100 |
+--------------+---------------+
| No brand | 22 |
+--------------+---------------+
- The boss says “Now get me a list of all items, with their brand AND number of items that the respective brand has”
You may try:
SELECT ITEM_NR ,BRAND ,COUNT(ITEM_ID) FROM ITEMS GROUP BY BRAND;
But you get (因为SELECT和GROUP BY都指定了BRAND):
ORA-00979: not a GROUP BY expression
3)这里就要使用窗口函数解决了:
SELECT ITEM_NR ,BRAND ,COUNT(ITEM_ID) OVER (PARTITION BY BRAND) FROM ITEMS;
Whic means:
COUNT(ITEM_ID)- get the number of itemsOVER- Over the set of rows(PARTITION BY BRAND)- that have the same brand
And the result is:
+--------------+---------------+----------+
| Items | Brand | Count() |
+--------------+---------------+----------+
| Item 1 | Hugo Boss | 100 |
+--------------+---------------+----------+
| Item 2 | Hugo Boss | 100 |
+--------------+---------------+----------+
| Item 3 | No brand | 22 |
+--------------+---------------+----------+
| Item 4 | No brand | 22 |
+--------------+---------------+----------+
| Item 5 | H&M | 50 |
+--------------+---------------+----------+
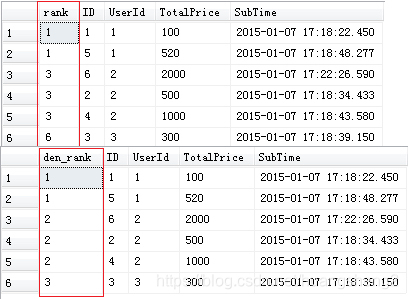
9.解决方案:ROW_NUMBER 与 RANK
SELECT id,
account_id,
total,
RANK() OVER (PARTITION BY account_id ORDER BY total DESC) AS total_rank
FROM orders
这里要注意两点:
- ROW_NUMBER() 和 RANK()是不用在小括弧中加参数的。(就是排序么)
- 区别是ROW_NUMBER是顺序增加的,而RAND是可以并列的(1,2,2,4……)
10.视频:窗口函数中的聚合
这里先扩展下新看到的 DENSE_RANK 和 RANK 的区别,前者在排名是连续的1、2、3,后者则会根据并列跳过相应的数字:
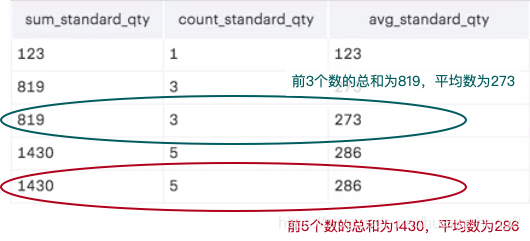
这里课程中的几个例子需要反复掌握,而且在解释的时候有个新小概念:**运行平均值。**指的就是按顺序处理数据的时候,每一步的总数除以这一步的个数,如下图:
12.解决方案:窗口函数中的聚合
上面小节,删除了 ORDER BY 后第二个框的输入是这样的:
SELECT id,
account_id,
standard_qty,
DATE_TRUNC('month', occurred_at) AS month,
DENSE_RANK() OVER (PARTITION BY account_id) AS dense_rank,
SUM(standard_qty) OVER (PARTITION BY account_id) AS sum_std_qty,
COUNT(standard_qty) OVER (PARTITION BY account_id) AS count_std_qty,
AVG(standard_qty) OVER (PARTITION BY account_id) AS avg_std_qty,
MIN(standard_qty) OVER (PARTITION BY account_id) AS min_std_qty,
MAX(standard_qty) OVER (PARTITION BY account_id) AS max_std_qty
FROM orders
输出对比如下:
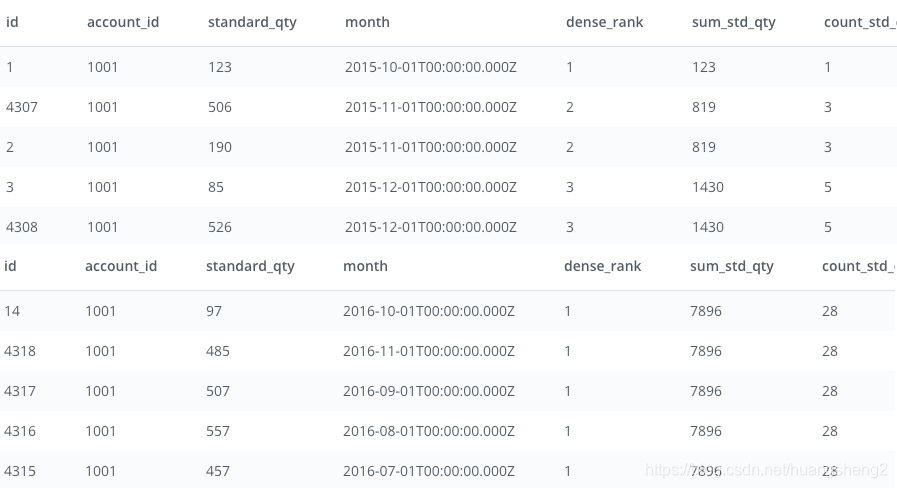
原因在这节解释的比较清楚:
ORDER BY是窗口函数不可或缺的两个子句之一。ORDER和PARTITION定义了所谓的“窗口” —— 用于进行计算的有序数据子集。 删除ORDER BY将剩下一个未经排序的分区。在我们的查询案例中,每一列的值只是其各自的account_id中所有standard_qty值的聚合(例如,求和 SUM,计数 COUNT,平均值 AVERAGE,最小值 MIN 或最大值 MAX)。
15.解决方案:为复杂的窗口函数指定别名
千呼万唤始出来啊,我们可以为 WINDOW 也起个别名复用,注意位置在代码的最后部分添加。
SELECT id,
account_id,
DATE_TRUNC('year',occurred_at) AS year,
DENSE_RANK() OVER account_year_window AS dense_rank,
total_amt_usd,
SUM(total_amt_usd) OVER account_year_window AS sum_total_amt_usd,
COUNT(total_amt_usd) OVER account_year_window AS count_total_amt_usd,
AVG(total_amt_usd) OVER account_year_window AS avg_total_amt_usd,
MIN(total_amt_usd) OVER account_year_window AS min_total_amt_usd,
MAX(total_amt_usd) OVER account_year_window AS max_total_amt_usd
FROM orders
WINDOW account_year_window AS (PARTITION BY account_id ORDER BY DATE_TRUNC('year',occurred_at))
17.练习:比较当前列于上一列
这里的新函数 LAG() 和 LEAD() 和他们的差课程中讲的比较清楚。再做练习的时候,后面的 FROM() sub 的作用是把 total_amt_usd 做了一个 SUM 的转换。
19.视频:百分位数简介
这里我们学习了这部分的最后一个函数: NTILE(n) 就是将数据分成n份,并标识这行数据属于那个分类中。比如第一个练习的这句:
NTILE(4) OVER (PARTITION BY account_id ORDER BY standard_qty)
就是说按照账户购买的量来划分4个等级。就可以针对重点客户进行一些促销动作了。另外,对于销售的考核也可以用这个方法,自动评级,发放对应奖金。

















 2166
2166

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









