







 本文探讨了机器学习中一个反常现象:模型平方损失高但准确率良好的原因。平方损失函数(RMSE)易受离群点影响,而高准确率可能源于数据集中离群点的存在。解决方案包括数据预处理去除离群点、建立复杂模型和改用MAPE作为评估指标。
本文探讨了机器学习中一个反常现象:模型平方损失高但准确率良好的原因。平方损失函数(RMSE)易受离群点影响,而高准确率可能源于数据集中离群点的存在。解决方案包括数据预处理去除离群点、建立复杂模型和改用MAPE作为评估指标。
本文重点
在机器学习模型学习的过程中,可能会出现一个特别奇怪的现象,平方损失非常高,但是准确率却很高,那么这个模型的效果还是不错的。前面我们介绍过平方损失也是评价指标之一,那么这样的话,平方损失RMSE就失效了。
平方损失函数(RMSE)
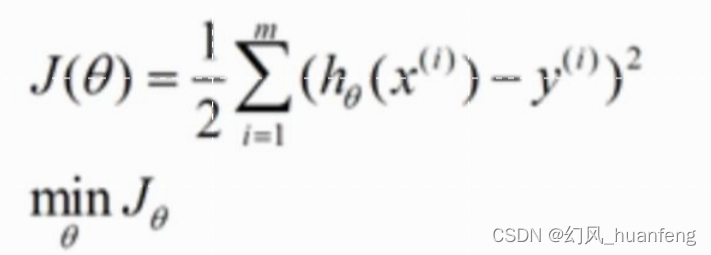
平方损失函数的图像如上所示,x(i)表示第i个样本,hθ(x(i))表示第i个样本的预测值,y(i)表示第i个样本的真实值。也就是说RMSE是很容易反映回归模型预测值与真实值的偏离程度。
出现问题的原因
出现平方误差大,但是准确率高的原因可能是存在噪音点,如果出现个别偏离程度非常大的离群点时,就有可能使得平方损失非常大。
解决方法
1、在数据预处理的时候,直接将这些离群点给过滤掉
2、建立更加复杂的模型,将离群点产生的原因考虑进来
3、使用平均绝对百分比误差(MAPE)代替RMSE
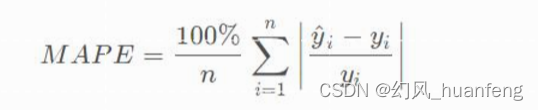
MAPE 为0%表示完美模型,MAPE 大于 100 %则表示劣质模型。相比于RMSE,MAPE相当于把每个点的误差进行了归一化,降低了个别离群点带来的影响。


















 347
347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











