




文章目录
1. 实战概述
- 本次实战部署了基于 KRaft 模式的 Kafka 4.1.0 三节点高可用集群,使用 JDK 17 环境,通过自定义配置实现 broker 与 controller 融合部署,完成集群初始化、启动、主题创建与验证,确保元数据一致性和服务稳定性。
2. 实战步骤
2.1 下载Kafka安装包
- 下载网址:https://kafka.apache.org/downloads
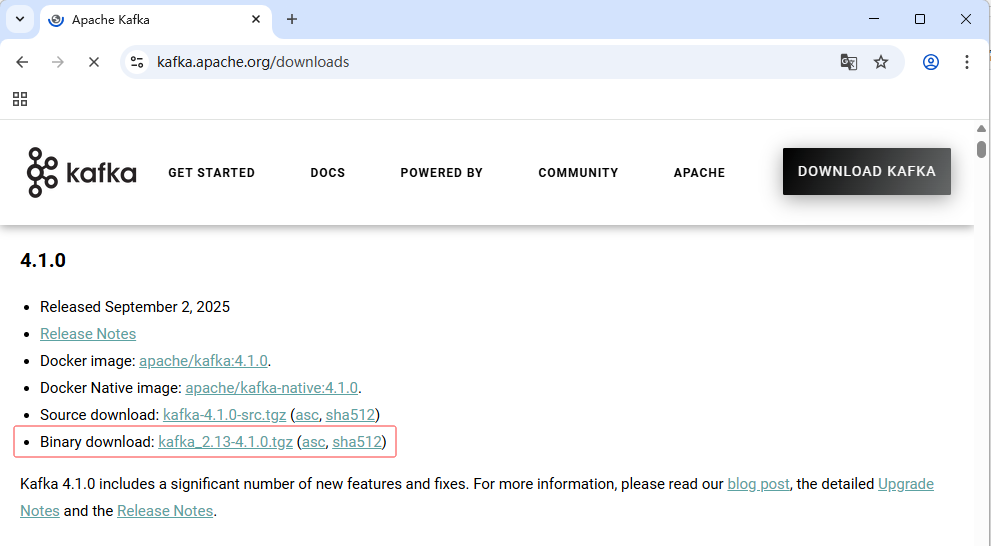
- 下载
kafka_2.13-4.1.0.tgz安装包到本地
2.2 安装与分发JDK17
2.2.1 为何要用JDK17
- Kafka 社区已在 4.0+ 默认要求 JDK 17,JDK 8 和 11 虽在部分测试中可用,但 4.1.0 实际仅稳定支持 JDK 17+。
- 大数据其它组件有些依然要求JDK8,所以系统默认使用JDK8,JDK17专门针对Kafka4.1.0来使用。
2.2.2 上传JDK17安装包
- 将JDK17安装包上传到master主节点
/opt目录
- 执行命令:
ll jdk-17.0.16_linux-x64_bin.tar.gz

2.2.3 将JDK17安装包解压到指定目录
- 执行命令:
tar -zxvf jdk-17.0.16_linux-x64_bin.tar.gz -C /usr/local

- 执行命令:
/usr/local/jdk-17.0.16/bin/java -version
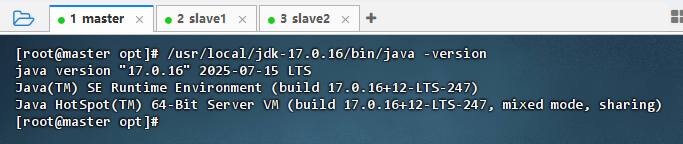
- 执行命令:
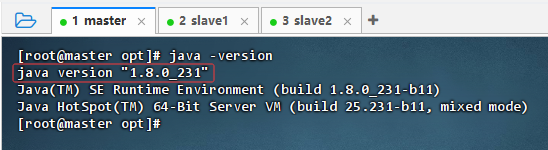
java -version,系统默认使用的依然是JDK1.8,因为有些大数据组件需要使用JDK1.8
2.2.4 将解压后的JDK17分发到两个从节点
- 执行命令:
scp -r /usr/local/jdk-17.0.16 root@slave1:/usr/local/jdk-17.0.16

- 执行命令:
scp -r /usr/local/jdk-17.0.16 root@slave2:/usr/local/jdk-17.0.16

2.3 主节点上安装配置Kafka
2.3.1 上传Kafka安装包
- 将Kafka安装包上传到master主节点
/opt目录
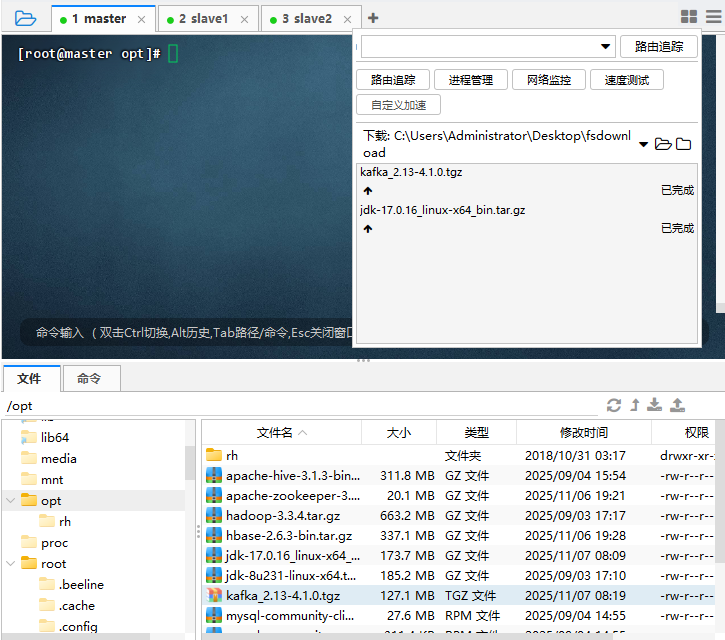
- 执行命令:
ll kafka_2.13-4.1.0.tgz

2.3.2 将Kafka安装包解压缩到指定目录
- 执行命令:
tar -zxvf kafka_2.13-4.1.0.tgz -C /usr/local

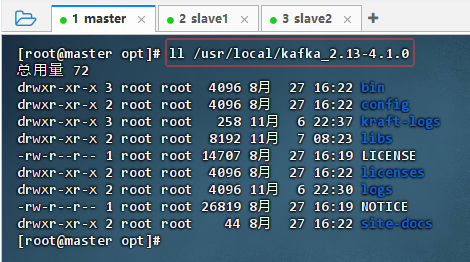
- 执行命令:
ll /usr/local/kafka_2.13-4.1.0
2.3.3 给Kafka配置环境变量
-
执行命令:
vim /etc/profile
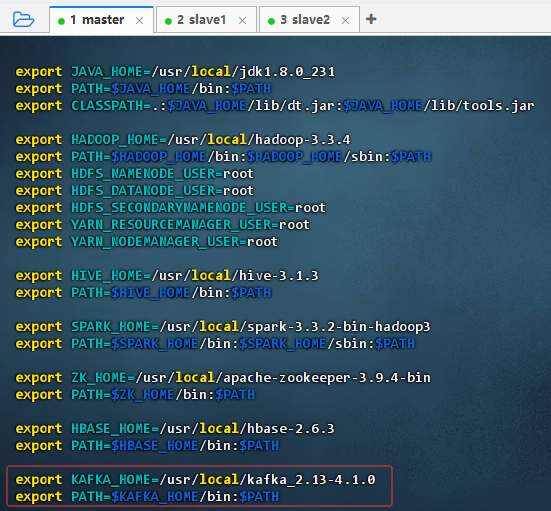
export KAFKA_HOME=/usr/local/kafka_2.13-4.1.0 export PATH=$KAFKA_HOME/bin:$PATH -
执行命令:
source /etc/profile,让配置生效
2.3.4 编辑Kafka服务器属性文件
-
执行命令:
cd $KAFKA_HOME/config,进入Kafka配置目录
-
执行命令:
mv server.properties server.properties.bak

-
执行命令:
vim server.properties
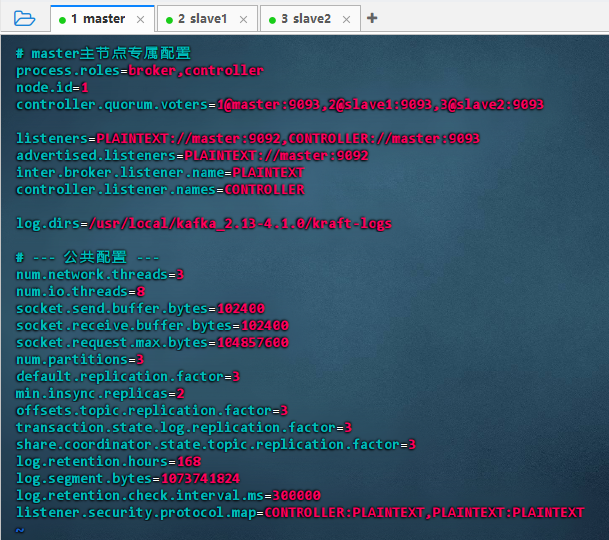
# master主节点专属配置 process.roles=broker,controller node.id=1 controller.quorum.voters=1@master:9093,2@slave1:9093,3@slave2:9093 listeners=PLAINTEXT://master:9092,CONTROLLER://master:9093 advertised.listeners=PLAINTEXT://master:9092 inter.broker.listener.name=PLAINTEXT controller.listener.names=CONTROLLER log.dirs=/usr/local/kafka_2.13-4.1.0/kraft-logs # --- 公共配置 --- num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 num.partitions=3 default.replication.factor=3 min.insync.replicas=2 offsets.topic.replication.factor=3 transaction.state.log.replication.factor=3 share.coordinator.state.topic.replication.factor=3 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT -
配置说明:该配置为 Kafka KRaft 模式下 master 节点的专属设置:同时担任 broker 和 controller(node.id=1),通过 9092 提供服务、9093 参与元数据共识,quorum 包含三节点。公共参数优化网络、IO 及副本策略,确保高可用与数据持久性。
2.3.5 编辑Kafka环境配置文件
-
执行命令:
vim kafka-env.sh
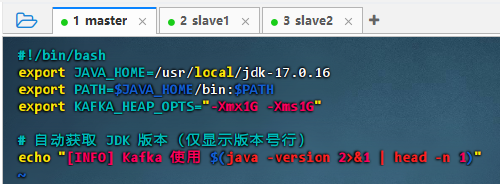
#!/bin/bash export JAVA_HOME=/usr/local/jdk-17.0.16 export PATH=$JAVA_HOME/bin:$PATH export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" # 自动获取 JDK 版本(仅显示版本号行) echo "[INFO] Kafka 使用 $(java -version 2>&1 | head -n 1)" -
配置说明:该脚本配置 Kafka 运行环境:指定 JDK 17 路径,设置堆内存为 1GB,并自动获取并输出实际使用的 Java 版本信息,确保运行时环境清晰可见,便于调试与维护。
2.3.6 编辑Kafka运行类脚本文件
-
执行命令:
cd ../bin
-
执行命令:
vim kafka-run-class.sh,添加红框内的语句
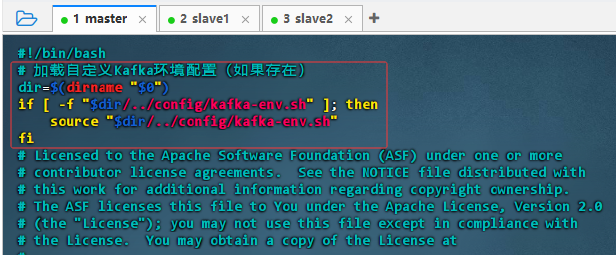
#!/bin/bash # 加载自定义Kafka环境配置(如果存在) dir=$(dirname "$0") if [ -f "$dir/../config/kafka-env.sh" ]; then source "$dir/../config/kafka-env.sh" fi -
配置说明:该脚本在启动 Kafka 前自动检测并加载同级
config目录下的kafka-env.sh自定义环境配置文件(如 JDK 路径、堆内存等),提升部署灵活性与可维护性,避免硬编码参数。
2.3.7 创建日志目录
-
执行命令:
cd ..,返回Kafka主目录
-
执行命令:
mkdir kraft-logs
2.3.8 生成集群ID
- 执行命令:
CLUSTER_ID=$(bin/kafka-storage.sh random-uuid)

- 执行命令:
echo $CLUSTER_ID,查看集群ID:2g0iVAaKR2WwmtK5_L321g

2.3.9 基于集群ID格式化存储目录
- 执行命令:
bin/kafka-storage.sh format -t 2g0iVAaKR2WwmtK5_L321g -c config/server.properties

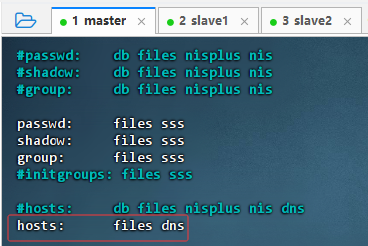
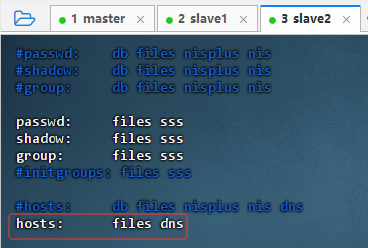
2.3.10 编辑nsswitch.conf文件
- 执行命令:
vim /etc/nsswitch.conf,删除hosts属性值的myhostname

2.4 在slave1从节点上配置Kafka
2.4.1 从master主节点将Kafka分发到slave1从节点
- 执行命令:
scp -r $KAFKA_HOME root@slave1:$KAFKA_HOME

2.4.2 从master主节点将环境配置文件分发到slave1从节点
- 执行命令:
scp /etc/profile root@slave1:/etc/profile

- 在slave1从节点上执行命令:
source /etc/profile,让配置生效
2.4.3 编辑Kafka服务器属性文件
-
执行命令:
cd $KAFKA_HOME/config,进入Kafka配置目录
-
执行命令:
vim server.properties
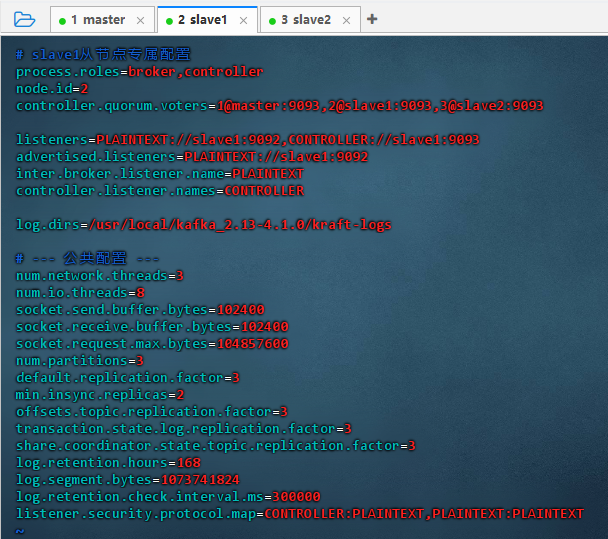
# slave1从节点专属配置 process.roles=broker,controller node.id=2 controller.quorum.voters=1@master:9093,2@slave1:9093,3@slave2:9093 listeners=PLAINTEXT://slave1:9092,CONTROLLER://slave1:9093 advertised.listeners=PLAINTEXT://slave1:9092 inter.broker.listener.name=PLAINTEXT controller.listener.names=CONTROLLER log.dirs=/usr/local/kafka_2.13-4.1.0/kraft-logs # --- 公共配置 --- num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 num.partitions=3 default.replication.factor=3 min.insync.replicas=2 offsets.topic.replication.factor=3 transaction.state.log.replication.factor=3 share.coordinator.state.topic.replication.factor=3 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT -
配置说明:该配置为 Kafka KRaft 模式下 slave1 节点的专属设置:同时担任 broker 和 controller(node.id=2),通过 9092 提供服务、9093 参与控制器共识,quorum 与 master/slave2 组成三节点集群,公共参数确保高可用、数据冗余与性能。
2.4.4 基于集群ID格式化存储目录
-
执行命令:
cd ..,返回Kafka主目录
-
执行命令:
bin/kafka-storage.sh format -t 2g0iVAaKR2WwmtK5_L321g -c config/server.properties

2.4.5 编辑nsswitch.conf文件
- 执行命令:
vim /etc/nsswitch.conf,删除hosts属性值的myhostname
2.5 在slave2从节点上配置Kafka
2.5.1 从master主节点将Kafka分发到slave2从节点
- 执行命令:
scp -r $KAFKA_HOME root@slave2:$KAFKA_HOME

2.5.2 从master主节点将环境配置文件分发到slave2从节点
-
执行命令:
scp /etc/profile root@slave2:/etc/profile

-
在slave2从节点上执行命令:
source /etc/profile,让配置生效
2.5.3 编辑Kafka服务器属性文件
-
执行命令:
cd $KAFKA_HOME/config,进入Kafka配置目录
-
执行命令:
vim server.properties
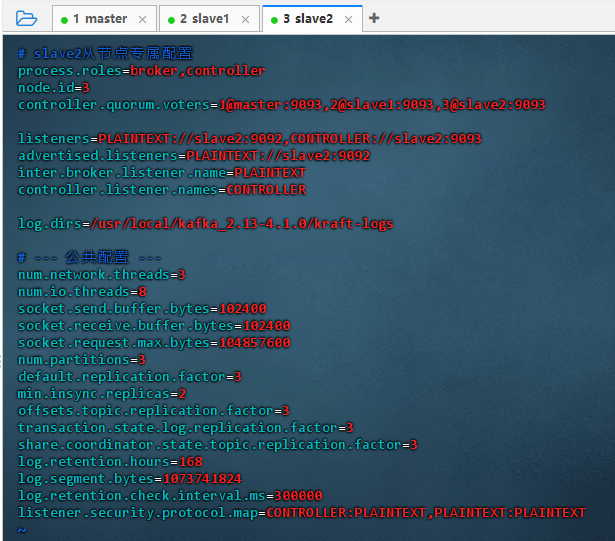
# slave2从节点专属配置 process.roles=broker,controller node.id=3 controller.quorum.voters=1@master:9093,2@slave1:9093,3@slave2:9093 listeners=PLAINTEXT://slave2:9092,CONTROLLER://slave2:9093 advertised.listeners=PLAINTEXT://slave2:9092 inter.broker.listener.name=PLAINTEXT controller.listener.names=CONTROLLER log.dirs=/usr/local/kafka_2.13-4.1.0/kraft-logs # --- 公共配置 --- num.network.threads=3 num.io.threads=8 socket.send.buffer.bytes=102400 socket.receive.buffer.bytes=102400 socket.request.max.bytes=104857600 num.partitions=3 default.replication.factor=3 min.insync.replicas=2 offsets.topic.replication.factor=3 transaction.state.log.replication.factor=3 share.coordinator.state.topic.replication.factor=3 log.retention.hours=168 log.segment.bytes=1073741824 log.retention.check.interval.ms=300000 listener.security.protocol.map=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT -
配置说明:该配置为 Kafka KRaft 模式下 slave2 节点的专属设置:同时担任 broker 和 controller(node.id=3),通过 9092 提供服务、9093 参与控制器共识,quorum 与 master/slave1 组成三节点高可用集群,公共参数确保数据冗余、一致性与性能。
2.5.4 基于集群ID格式化存储目录
-
执行命令:
cd ..,返回Kafka主目录
-
执行命令:
bin/kafka-storage.sh format -t 2g0iVAaKR2WwmtK5_L321g -c config/server.properties

2.5.5 编辑nsswitch.conf文件
- 执行命令:
vim /etc/nsswitch.conf,删除hosts属性值的myhostname
2.6 启动Kafka集群
2.6.1 master主节点启动Kafka服务
- 执行命令:
bin/kafka-server-start.sh -daemon config/server.properties

2.6.2 slave1从节点启动Kafka服务
- 执行命令:
bin/kafka-server-start.sh -daemon config/server.properties

2.6.3 slave2节点启动Kafka服务
- 执行命令:
bin/kafka-server-start.sh -daemon config/server.properties

2.6.4 验证Kafka集群是否启动成功
- 查看Kafka进程
-
master主节点上执行命令:
jps | grep Kafka
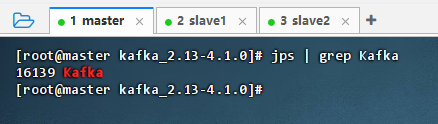
-
slave1从节点上执行命令:
jps | grep Kafka
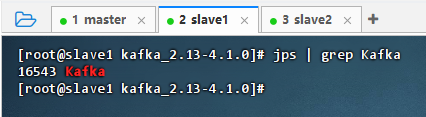
-
slave2从节点上执行命令:
jps | grep Kafka
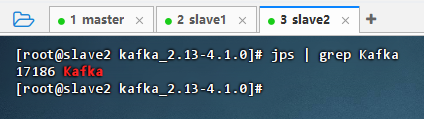
-
- 查看日志
-
master主节点上执行命令:
cat $KAFKA_HOME/logs/server.log | grep started
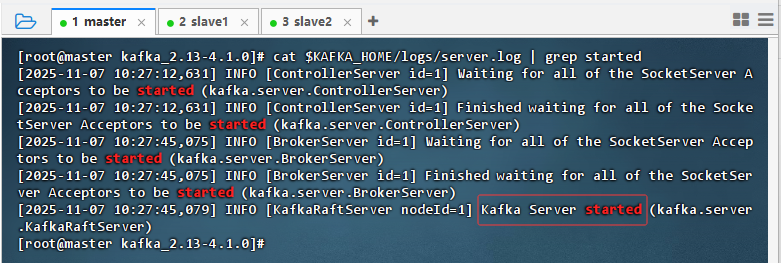
-
slave1从节点上执行命令:
cat $KAFKA_HOME/logs/server.log | grep started
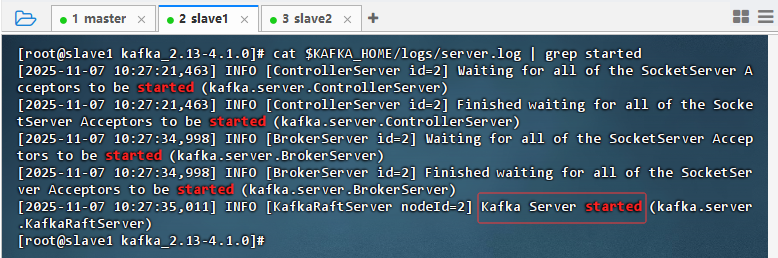
-
slave2从节点上执行命令:
cat $KAFKA_HOME/logs/server.log | grep started
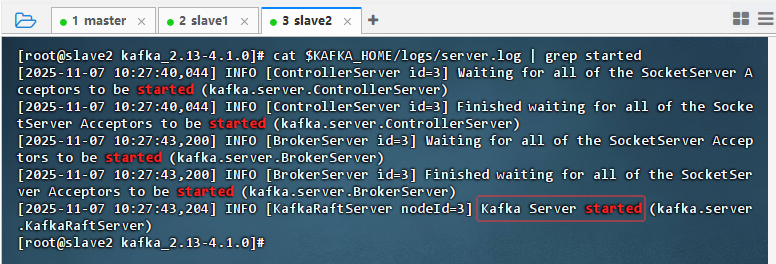
-
2.6 测试Kafka集群
2.6.1 创建主题
- 在master主节点上执行命令:
bin/kafka-topics.sh --create --topic hello-kafka-world --partitions 3 --replication-factor 3 --bootstrap-server master:9092
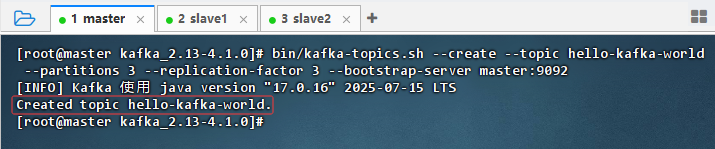
- 结果说明:成功创建名为
hello-kafka-world的主题,分区数为 3,副本因子为 3,表明 Kafka 集群已正常运行,各节点通信无误,KRaft 模式下元数据管理与 Topic 创建功能均正常。
2.6.2 列出主题
- 在slave1从节点上执行命令:
bin/kafka-topics.sh --list --bootstrap-server master:9092

- 结果说明:在 slave1 节点上成功查询到主题
hello-kafka-world,表明 Kafka 集群元数据同步正常,各节点间通信无阻,KRaft 模式下控制器与 broker 协同工作稳定,主题信息已全局一致。
2.6 关闭Kafka集群
- 在三个节点上执行命令:
kafka-server-stop.sh
3. 实战总结
- 本次实战成功搭建了基于 KRaft 模式的 Kafka 4.1.0 三节点高可用集群。通过在 master、slave1 和 slave2 节点上统一部署 JDK 17 环境,合理配置
server.properties实现各节点同时承担 broker 与 controller 角色,并利用共享集群 ID 完成存储目录格式化。关键步骤包括修正/etc/nsswitch.conf以确保主机名正确解析、自定义kafka-env.sh指定 JDK 路径,以及通过advertised.listeners明确对外通信地址。最终成功创建并验证主题,确认集群元数据同步正常、节点间通信稳定,为后续 Kafka 应用开发与生产部署奠定了坚实基础。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











