




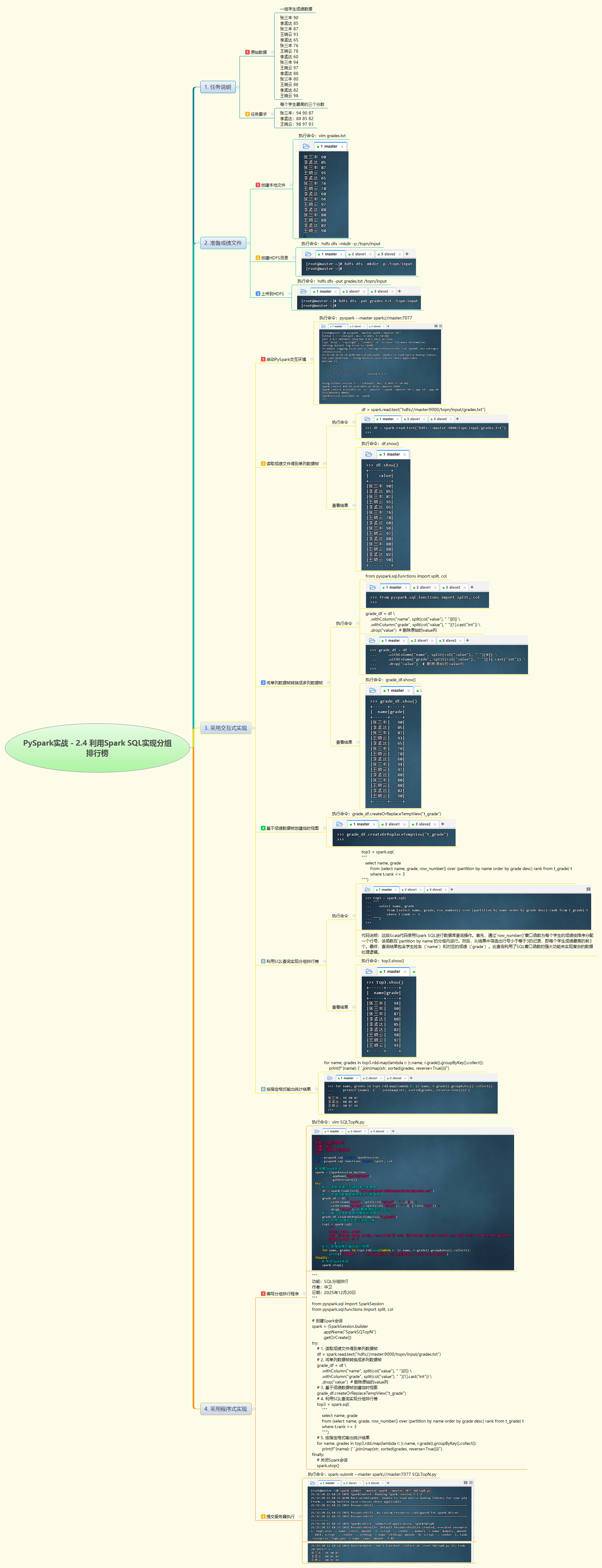
1. 实战概述
- 本次实战基于 Spark SQL 对学生成绩数据进行分组 Top3 排行统计。通过读取 HDFS 上的成绩文件,解析姓名与分数,利用窗口函数
ROW_NUMBER()按学生分组并降序排序,筛选出每人最高三次成绩,最终按指定格式输出结果,展示了 Spark SQL 在分组排名场景中的高效处理能力。
2. 实战步骤
3. 实战总结
- 本次实战完成了“每个学生最高三个分数”的典型 TopN 分析任务。首先将原始文本数据解析为结构化 DataFrame,创建临时视图后,借助
ROW_NUMBER() OVER (PARTITION BY name ORDER BY grade DESC)窗口函数为每名学生的成绩排序并编号,再筛选排名 ≤3 的记录。最后通过 RDD 的groupByKey()在 Driver 端聚合并格式化输出,简洁实现了如“张三丰: 94 90 87”的展示效果。整个流程融合了 Spark SQL 的声明式查询优势与 Python 的灵活后处理能力,既保证了分布式计算效率,又满足了业务展示需求。该方法可轻松扩展至 Top5、Top10 等场景,是用户行为分析、成绩统计等业务中常用的数据处理范式。


















 1651
1651

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











