







 超级会员免费看
超级会员免费看
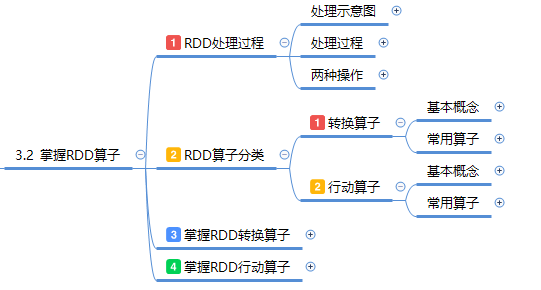
在Spark中,RDD(弹性分布式数据集)是处理大规模数据集的基本抽象。映射算子map()是RDD转换算子之一,它允许对RDD中的每个元素应用一个函数,并返回一个新的RDD,其中包含应用函数后的结果。这种操作不会改变原始RDD的分区结构,而是生成一个新的RDD来存储转换后的数据。
在实际应用中,map()算子可以用于数据预处理、特征提取等场景。例如,可以将数据集中的数值特征进行标准化处理,或者将文本数据转换为词频向量。此外,map()还可以与其他算子(如filter()、reduceByKey()等)结合使用,实现更复杂的数据处理流程。
掌握map()算子的使用,对于进行高效的数据处理和分析至关重要。通过合理设计映射函数,可以显著提高数据处理的效率和准确性。在处理大规模数据集时,合理利用Spark的RDD和map()算子,可以有效地分布式并行处理数据,从而提高计算性能和资源利用率。



















 192
192

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











