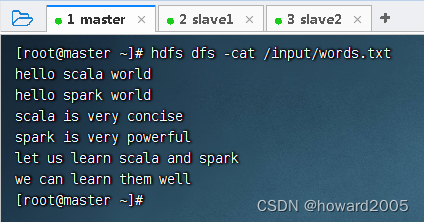
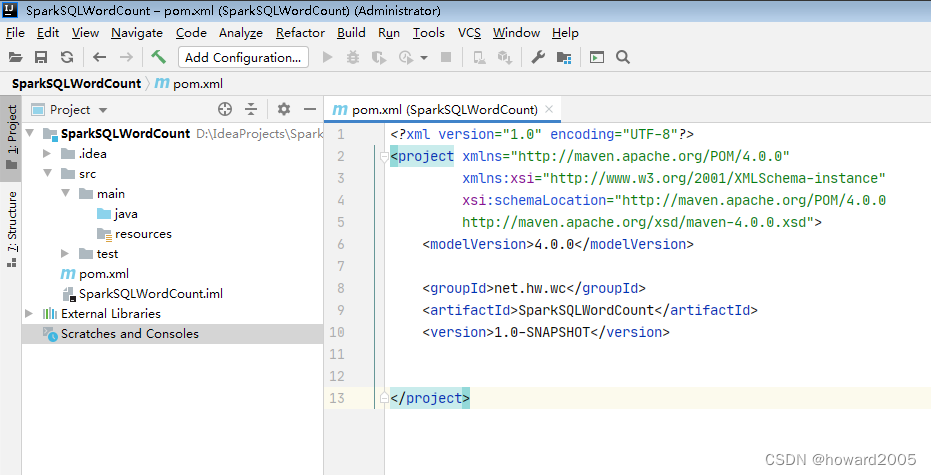
文章目录 零、本讲学习目标 一、使用Spark SQL实现词频统计 (一)数据源 - words.txt (二)创建Maven项目 (三)添加依赖和构建插件 (四)修改源目录名称 (五)创建日志属性文件 (六)创建词频统计单例对象 (七)启动程序,查看结果 (八)词频统计数据转化流程图 零、本讲学习目标 使用Spark SQL实现词频统计 掌握Spark SQL与Hive整合 掌握Spark SQL读写MySQL 完成Spark热点搜索词统计 Spark SQL智慧交通数据分析 一、使用Spark SQL实现词频统计 (一)数据源 - words.txt (二)创建Maven项目 创建Maven项目 - SparkSQLWordCount (三)添加依赖和构建插件 在pom.xml文件里添加依赖和构建插件








 超级会员免费看
超级会员免费看
 本讲介绍了如何使用Spark SQL进行词频统计,包括从words.txt数据源开始,创建Maven项目,配置依赖和构建插件,调整源目录,创建日志属性文件,建立词频统计单例对象,并最终运行程序查看词频统计结果。此外,还涉及了Spark SQL在智慧交通数据分析中的应用。
本讲介绍了如何使用Spark SQL进行词频统计,包括从words.txt数据源开始,创建Maven项目,配置依赖和构建插件,调整源目录,创建日志属性文件,建立词频统计单例对象,并最终运行程序查看词频统计结果。此外,还涉及了Spark SQL在智慧交通数据分析中的应用。

 订阅专栏 解锁全文
订阅专栏 解锁全文




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








