




一、什么是模型训练?为什么需要训练?预训练是什么?
模型训练:从"无知"到"有识"的进化过程
模型训练是指通过大量数据自动调整模型参数,使模型能够从输入数据中学习规律和模式,从而具备解决特定任务能力的过程。
生动比喻:教婴儿学语言
- 初始模型:像刚出生的婴儿
-
- 大脑有基本结构(模型架构)
- 但没有任何语言知识(随机参数)
- 训练过程:像父母教孩子说话
-
- 不断给孩子看图片、听对话(输入数据)
- 纠正孩子的错误(损失函数)
- 孩子逐渐学会语言规律(参数优化)
- 训练好的模型:像语言流利的成年人
-
- 能够理解和生成语言
- 具备语言推理能力
为什么需要训练?
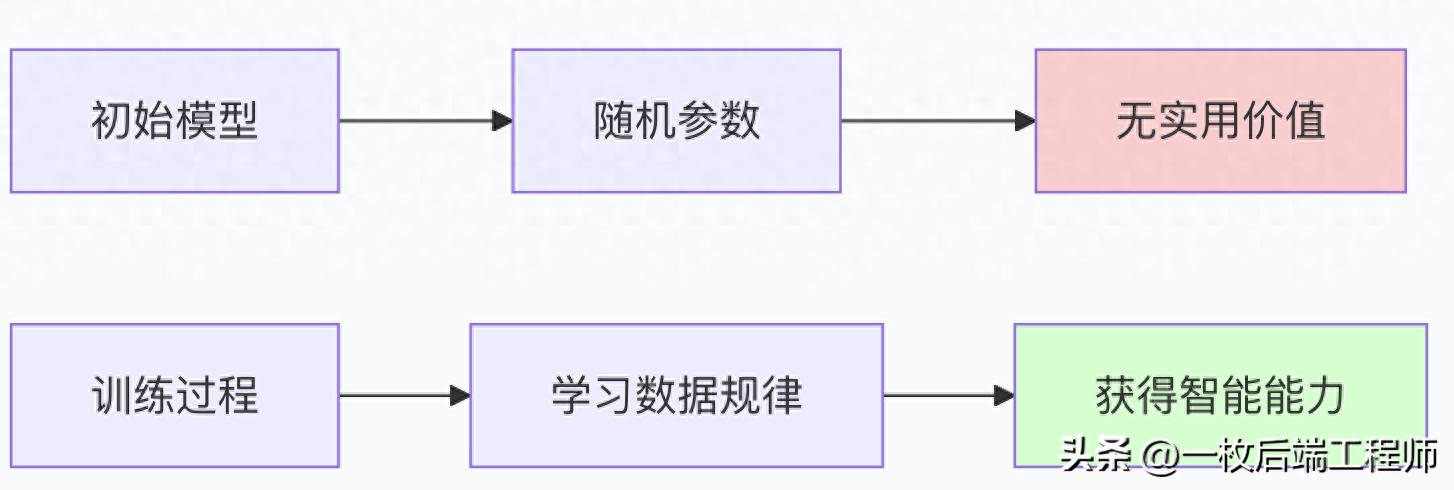
没有训练的模型就像:
- 有大脑结构但没有知识的植物人
- 有硬件但没有软件的计算机
- 有乐器但不会演奏的音乐家
预训练:通用的"基础教育"
预训练是在大规模通用数据上进行的初步训练,目的是让模型学习通用的知识和能力。
比喻理解:
- 预训练 = 大学通识教育
-
- 学习语言、数学、逻辑等基础能力
- 不针对特定职业,但为所有专业打基础
- 花费时间长,投入资源大
- 微调 = 职业培训
-
- 在通识教育基础上学习特定技能
- 时间短,针对性强
- 建立在良好基础之上
二、模型怎么进行训练?GPT怎么进行预训练?
训练的基本原理:三步循环
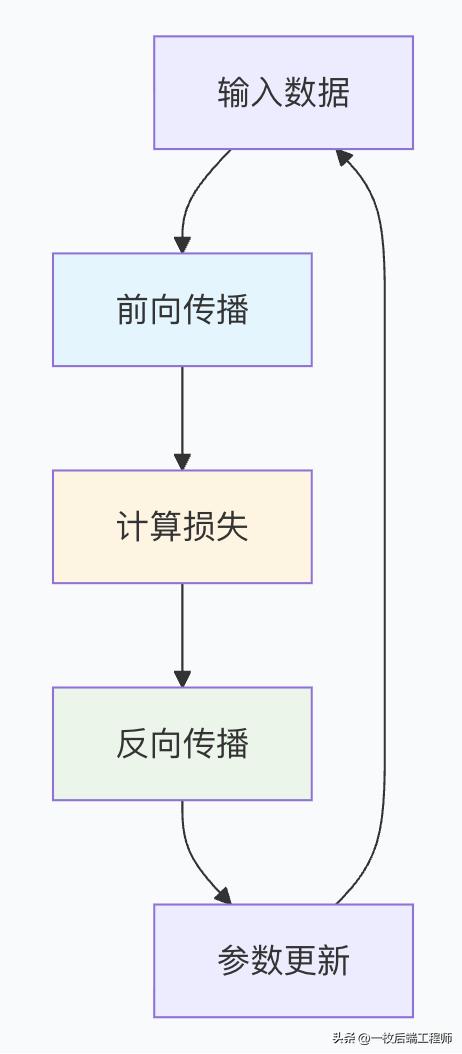
1. 前向传播:模型的"思考过程"
import torch
import torch.nn as nn
def forward_pass(model, input_data):
"""
前向传播:输入数据通过模型得到预测结果
"""
# 输入通过每一层网络
hidden1 = model.layer1(input_data)
hidden2 = model.layer2(hidden1)
# ... 更多层 ...
predictions = model.output_layer(hidden2)
return predictions
# 实际示例
batch_size = 32
seq_len = 128
input_ids = torch.randint(0, 50000, (batch_size, seq_len))
# 假设的Transformer模型
with torch.no_grad(): # 前向传播不需要梯度
outputs = model(input_ids)
predictions = outputs.last_hidden_state
2. 损失计算:评估"犯错程度"
def compute_loss(predictions, targets):
"""
计算模型预测与真实值之间的差距
"""
# 交叉熵损失 - 常用于分类任务
loss_fn = nn.CrossEntropyLoss()
# predictions: [batch_size, seq_len, vocab_size]
# targets: [batch_size, seq_len]
loss = loss_fn(predictions.view(-1, predictions.size(-1)),
targets.view(-1))
return loss
# GPT预训练的特殊损失计算
def gpt_pretraining_loss(model_output, input_ids):
"""
GPT的预训练损失:下一个词预测
"""
# 输入: "The cat sat on the"
# 目标: "cat sat on the mat"
# 即目标序列是输入序列向右移动一位
shift_logits = model_output[:, :-1, :] # 预测分布
shift_labels = input_ids[:, 1:] # 实际下一个词
loss = nn.CrossEntropyLoss()(shift_logits.reshape(-1, shift_logits.size(-1)),
shift_labels.reshape(-1))
return loss
3. 反向传播与参数更新:模型的"学习过程"
def training_step(model, batch, optimizer):
"""
单个训练步骤的完整流程
"""
# 清零梯度
optimizer.zero_grad()
# 前向传播
inputs, targets = batch
predictions = model(inputs)
# 计算损失
loss = compute_loss(predictions, targets)
# 反向传播
loss.backward()
# 梯度裁剪(防止梯度爆炸)
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
# 参数更新
optimizer.step()
return loss.item()
# 优化器配置示例
optimizer = torch.optim.AdamW(
model.parameters(),
lr=1e-4, # 学习率
weight_decay=0.01 # 权重衰减
)
GPT的预训练:自监督学习典范
GPT预训练的核心任务:下一个词预测

具体实现代码
class GPTPretrainer:
def __init__(self, model, learning_rate=1e-4):
self.model = model
self.optimizer = AdamW(model.parameters(), lr=learning_rate)
def prepare_training_data(self, text_corpus):
"""
准备GPT预训练数据
"""
# 分词
tokens = tokenizer.encode(text_corpus)
# 创建输入-目标对
# 输入: [t1, t2, t3, ..., t_{n-1}]
# 目标: [t2, t3, t4, ..., t_n]
inputs = tokens[:-1]
targets = tokens[1:]
return inputs, targets
def pretrain_step(self, batch_texts):
"""
GPT预训练步骤
"""
self.model.train()
# 准备数据
input_ids, attention_masks, labels = [], [], []
for text in batch_texts:
# Tokenize文本
encoding = tokenizer(text, truncation=True, padding='max_length',
max_length=1024, return_tensors='pt')
input_ids.append(encoding['input_ids'])
attention_masks.append(encoding['attention_mask'])
# 标签是输入向右移动一位
labels.append(torch.cat([encoding['input_ids'][:, 1:],
torch.zeros(1, 1, dtype=torch.long)], dim=1))
# 转换为tensor
input_ids = torch.cat(input_ids, dim=0)
attention_masks = torch.cat(attention_masks, dim=0)
labels = torch.cat(labels, dim=0)
# 前向传播
outputs = self.model(input_ids, attention_mask=attention_masks, labels=labels)
loss = outputs.loss
# 反向传播和优化
self.optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(self.model.parameters(), 1.0)
self.optimizer.step()
return loss.item()
三、训练的过程是什么?
完整训练流程概览
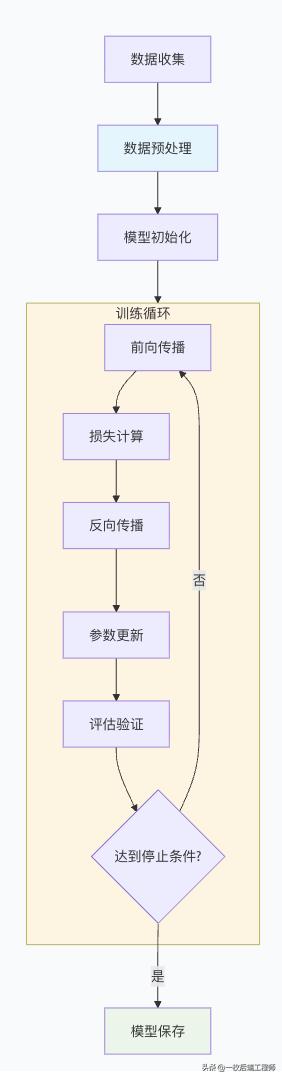
阶段1:数据准备与预处理
数据收集与清洗
class DataPreprocessor:
def __init__(self, vocab_size=50000, max_seq_len=1024):
self.vocab_size = vocab_size
self.max_seq_len = max_seq_len
self.tokenizer = AutoTokenizer.from_pretrained("gpt2")
def prepare_pretraining_data(self, corpus_files):
"""
准备预训练数据
"""
datasets = []
for file in corpus_files:
with open(file, 'r', encoding='utf-8') as f:
text = f.read()
# 文本清洗
cleaned_text = self.clean_text(text)
# 分块处理(适应最大序列长度)
chunks = self.split_into_chunks(cleaned_text)
datasets.extend(chunks)
return datasets
def clean_text(self, text):
"""文本清洗"""
# 移除特殊字符、标准化空白等
import re
text = re.sub(r'[^\w\s.,!?;:]', '', text)
text = re.sub(r'\s+', ' ', text)
return text.strip()
def split_into_chunks(self, text, chunk_size=1000):
"""将长文本分割为块"""
words = text.split()
chunks = []
for i in range(0, len(words), chunk_size):
chunk = ' '.join(words[i:i+chunk_size])
chunks.append(chunk)
return chunks
数据加载器配置
from torch.utils.data import DataLoader, Dataset
class TextDataset(Dataset):
def __init__(self, texts, tokenizer, max_length=1024):
self.texts = texts
self.tokenizer = tokenizer
self.max_length = max_length
def __len__(self):
return len(self.texts)
def __getitem__(self, idx):
text = self.texts[idx]
# Tokenize
encoding = self.tokenizer(
text,
max_length=self.max_length,
padding='max_length',
truncation=True,
return_tensors='pt'
)
# 对于GPT,标签是输入向右移动一位
input_ids = encoding['input_ids'].squeeze()
labels = input_ids.clone()
labels[:-1] = input_ids[1:]
labels[-1] = -100 # 忽略最后一个位置的损失
return {
'input_ids': input_ids,
'attention_mask': encoding['attention_mask'].squeeze(),
'labels': labels
}
# 创建数据加载器
def create_dataloader(texts, batch_size=32, shuffle=True):
dataset = TextDataset(texts, tokenizer)
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
num_workers=4 # 并行加载数据
)
return dataloader
阶段2:训练配置与初始化
模型初始化策略
def initialize_model(config):
"""
初始化Transformer模型
"""
model_config = GPT2Config(
vocab_size=config.vocab_size,
n_positions=config.max_seq_len,
n_embd=config.hidden_size,
n_layer=config.num_layers,
n_head=config.num_heads
)
model = GPT2LMHeadModel(model_config)
# 参数初始化
def init_weights(module):
if isinstance(module, (nn.Linear, nn.Embedding)):
module.weight.data.normal_(mean=0.0, std=0.02)
elif isinstance(module, nn.LayerNorm):
module.bias.data.zero_()
module.weight.data.fill_(1.0)
model.apply(init_weights)
return model
# 训练配置类
class TrainingConfig:
def __init__(self):
self.batch_size = 32
self.learning_rate = 1e-4
self.num_epochs = 10
self.warmup_steps = 1000
self.max_grad_norm = 1.0
self.log_interval = 100
self.save_interval = 1000
self.eval_interval = 500
优化器与学习率调度
def create_optimizer_and_scheduler(model, config, total_steps):
"""
创建优化器和学习率调度器
"""
# 优化器
optimizer = AdamW(
model.parameters(),
lr=config.learning_rate,
weight_decay=0.01
)
# 学习率调度器(带warmup)
scheduler = get_linear_schedule_with_warmup(
optimizer,
num_warmup_steps=config.warmup_steps,
num_training_steps=total_steps
)
return optimizer, scheduler
# 学习率调度示例
def get_linear_schedule_with_warmup(optimizer, num_warmup_steps, num_training_steps):
"""
线性warmup然后线性衰减
"""
def lr_lambda(current_step):
if current_step < num_warmup_steps:
return float(current_step) / float(max(1, num_warmup_steps))
return max(0.0, float(num_training_steps - current_step) /
float(max(1, num_training_steps - num_warmup_steps)))
return torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda)
阶段3:训练循环实现
完整训练循环
class Trainer:
def __init__(self, model, train_dataloader, val_dataloader, config):
self.model = model
self.train_dataloader = train_dataloader
self.val_dataloader = val_dataloader
self.config = config
# 计算总步数
self.total_steps = len(train_dataloader) * config.num_epochs
# 创建优化器和调度器
self.optimizer, self.scheduler = create_optimizer_and_scheduler(
model, config, self.total_steps
)
# 训练状态
self.global_step = 0
self.best_val_loss = float('inf')
def train(self):
"""完整的训练过程"""
self.model.train()
for epoch in range(self.config.num_epochs):
print(f"开始第 {epoch + 1}/{self.config.num_epochs} 轮训练")
for batch_idx, batch in enumerate(self.train_dataloader):
# 训练步骤
train_loss = self.training_step(batch)
# 更新学习率
self.scheduler.step()
# 记录和日志
if self.global_step % self.config.log_interval == 0:
current_lr = self.scheduler.get_last_lr()[0]
print(f"Step {self.global_step}: Loss = {train_loss:.4f}, LR = {current_lr:.2e}")
# 验证
if self.global_step % self.config.eval_interval == 0:
val_loss = self.validate()
print(f"验证损失: {val_loss:.4f}")
# 保存最佳模型
if val_loss < self.best_val_loss:
self.best_val_loss = val_loss
self.save_checkpoint()
# 保存检查点
if self.global_step % self.config.save_interval == 0:
self.save_checkpoint()
self.global_step += 1
def training_step(self, batch):
"""单个训练步骤"""
self.optimizer.zero_grad()
# 将数据移动到设备
input_ids = batch['input_ids'].to(self.device)
attention_mask = batch['attention_mask'].to(self.device)
labels = batch['labels'].to(self.device)
# 前向传播
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
loss = outputs.loss
# 反向传播
loss.backward()
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(self.model.parameters(), self.config.max_grad_norm)
# 参数更新
self.optimizer.step()
return loss.item()
def validate(self):
"""验证过程"""
self.model.eval()
total_loss = 0
total_samples = 0
with torch.no_grad():
for batch in self.val_dataloader:
input_ids = batch['input_ids'].to(self.device)
attention_mask = batch['attention_mask'].to(self.device)
labels = batch['labels'].to(self.device)
outputs = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
labels=labels
)
total_loss += outputs.loss.item() * input_ids.size(0)
total_samples += input_ids.size(0)
self.model.train()
return total_loss / total_samples
def save_checkpoint(self):
"""保存检查点"""
checkpoint = {
'global_step': self.global_step,
'model_state_dict': self.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict(),
'scheduler_state_dict': self.scheduler.state_dict(),
'best_val_loss': self.best_val_loss,
'config': self.config
}
torch.save(checkpoint, f'checkpoint_step_{self.global_step}.pt')
print(f"检查点已保存: checkpoint_step_{self.global_step}.pt")
阶段4:监控与评估
训练过程监控
import matplotlib.pyplot as plt
from tensorboardX import SummaryWriter
class TrainingMonitor:
def __init__(self, log_dir='runs/experiment1'):
self.writer = SummaryWriter(log_dir)
self.train_losses = []
self.val_losses = []
self.learning_rates = []
def log_training_step(self, step, loss, lr):
"""记录训练步骤"""
self.writer.add_scalar('train/loss', loss, step)
self.writer.add_scalar('train/learning_rate', lr, step)
self.train_losses.append((step, loss))
self.learning_rates.append((step, lr))
def log_validation(self, step, val_loss):
"""记录验证结果"""
self.writer.add_scalar('val/loss', val_loss, step)
self.val_losses.append((step, val_loss))
def plot_training_curves(self):
"""绘制训练曲线"""
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(12, 4))
# 损失曲线
steps, train_losses = zip(*self.train_losses)
_, val_losses = zip(*self.val_losses)
ax1.plot(steps, train_losses, label='训练损失')
ax1.plot(steps, val_losses, label='验证损失')
ax1.set_xlabel('训练步数')
ax1.set_ylabel('损失')
ax1.legend()
ax1.set_title('训练和验证损失')
# 学习率曲线
steps, lrs = zip(*self.learning_rates)
ax2.plot(steps, lrs, color='orange')
ax2.set_xlabel('训练步数')
ax2.set_ylabel('学习率')
ax2.set_title('学习率变化')
plt.tight_layout()
plt.savefig('training_curves.png', dpi=300, bbox_inches='tight')
模型评估指标
def evaluate_model(model, eval_dataloader, device):
"""全面评估模型性能"""
model.eval()
total_loss = 0
total_tokens = 0
correct_predictions = 0
with torch.no_grad():
for batch in eval_dataloader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids=input_ids,
attention_mask=attention_mask,
labels=labels)
total_loss += outputs.loss.item()
# 计算准确率
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
# 只计算非忽略位置的准确率
non_ignore = labels != -100
correct_predictions += ((predictions == labels) & non_ignore).sum().item()
total_tokens += non_ignore.sum().item()
avg_loss = total_loss / len(eval_dataloader)
accuracy = correct_predictions / total_tokens if total_tokens > 0 else 0
perplexity = torch.exp(torch.tensor(avg_loss)).item()
return {
'loss': avg_loss,
'accuracy': accuracy,
'perplexity': perplexity
}
四、训练过程的关键挑战与解决方案
1. 过拟合问题
# 防止过拟合的技术
def setup_regularization(model, config):
"""设置正则化"""
# Dropout
for module in model.modules():
if hasattr(module, 'p'): # 有dropout率的模块
module.p = config.dropout_rate
# 权重衰减(已在优化器中配置)
# 早停
if config.early_stopping_patience > 0:
early_stopper = EarlyStopper(patience=config.early_stopping_patience)
2. 训练不稳定性
def stabilize_training(model, config):
"""训练稳定性技术"""
# 梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), config.max_grad_norm)
# 学习率warmup
# 已在调度器中实现
# 梯度累积(模拟更大批次)
if config.gradient_accumulation_steps > 1:
loss = loss / config.gradient_accumulation_steps
3. 内存优化
# 内存优化技术
def setup_memory_optimization():
"""设置内存优化"""
# 混合精度训练
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
# 梯度检查点(用计算换内存)
model.gradient_checkpointing_enable()
总结:训练的艺术与科学
训练过程的本质理解
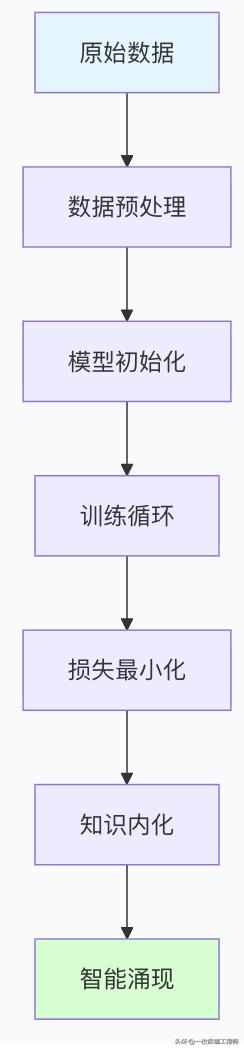
关键要点总结
- 数据是燃料:质量高、数量足的数据是成功训练的基础
- 架构是蓝图:合适的模型架构为学习提供可能性
- 优化是引擎:高效的优化算法驱动学习过程
- 正则化是导航:防止模型偏离正确方向
- 监控是仪表盘:实时了解训练状态,及时调整
训练成功的标志
- 损失持续下降:训练损失和验证损失都稳步下降
- 泛化能力良好:在未见数据上表现优秀
- 训练稳定性:没有剧烈的损失震荡
- 收敛合理:在合适的时间达到性能平台
从工程到艺术的升华
模型训练开始是严格的科学工程,但随着经验积累,逐渐变成一种艺术:
- 直觉:对超参数选择的敏感度
- 经验:对训练状态的准确判断
- 创新:针对特定问题的独特解决方案
正是这种科学与艺术的完美结合,使得Transformer模型的训练成为现代人工智能最令人着迷的领域之一。通过精心设计的训练流程,我们能够将原始数据转化为真正的智能,这无疑是数字时代的炼金术。



















 20
20

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











