




一、什么是向量化?
核心定义
向量化是将离散的符号(如文字)转换为连续的数值向量的过程。在深度学习中,它把人类可读的文本转换成计算机能够理解和处理的数学表示。
生动比喻:语言翻译成数学坐标
想象每个词在一个高维空间中的位置:
- 传统词典:用文字解释文字
- 向量空间:用数学坐标精确定位每个词的含义
"国王" → [0.8, -0.2, 0.5, 0.1, ...] "皇后" → [0.7, -0.3, 0.6, 0.2, ...] "男人" → [0.6, 0.1, 0.3, -0.4, ...] "女人" → [0.5, 0.2, 0.4, -0.3, ...]
向量化的神奇特性

二、从文字到向量化的完整过程
整体流程概览
步骤1:分词 - 文本的"原子化"
基本分词方法
# 原始文本
text = "I love natural language processing!"
# 简单空格分词
tokens = text.split()
print(tokens) # ['I', 'love', 'natural', 'language', 'processing!']
# 实际使用分词器
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
tokens = tokenizer.tokenize(text)
print(tokens) # ['i', 'love', 'natural', 'language', 'processing', '!']
不同分词策略对比
|
分词方法 |
示例输入 |
输出结果 |
优缺点 |
|
单词级 |
"I'm learning NLP" |
["I'm", "learning", "NLP"] |
词汇表大,OOV问题 |
|
子词级 |
"I'm learning NLP" |
["I", "'", "m", "learn", "##ing", "NL", "##P"] |
平衡词汇表与OOV |
|
字符级 |
"I'm learning NLP" |
["I", "'", "m", " ", "l", "e", ...] |
词汇表小,序列长 |
分词粒度比喻:乐高积木组装
- 单词级:使用完整的大型积木块
-
- 优点:表达完整,组合简单
- 缺点:需要大量存储空间,缺少灵活性
- 子词级:使用标准尺寸的中型积木
-
- 优点:灵活组合,经济高效
- 缺点:需要学习组合规则
- 字符级:使用最小的基础积木单元
-
- 优点:极简存储,无限组合
- 缺点:组装复杂,效率较低
步骤2:构建词汇表 - 创建"词库字典"
词汇表构建过程
# 假设我们有训练语料
corpus = [
"I love machine learning",
"Deep learning is amazing",
"Natural language processing transforms AI"
]
# 构建词汇表
vocab = {}
for sentence in corpus:
tokens = sentence.lower().split()
for token in tokens:
vocab[token] = vocab.get(token, 0) + 1
# 按频率排序并分配ID
sorted_vocab = sorted(vocab.items(), key=lambda x: x[1], reverse=True)
vocab_with_ids = {word: idx for idx, (word, _) in enumerate(sorted_vocab)}
print("词汇表:", vocab_with_ids)
# 输出: {'learning': 0, 'i': 1, 'love': 2, 'machine': 3,
# 'deep': 4, 'is': 5, 'amazing': 6, 'natural': 7,
# 'language': 8, 'processing': 9, 'transforms': 10, 'ai': 11}
实际Transformer词汇表示例
# BERT-base的词汇表大小
vocab_size = 30522 # 包含30522个token
# GPT-3的词汇表大小
gpt3_vocab_size = 50257 # 包含50257个token
# 实际使用中的token到ID映射
token_ids = tokenizer.encode("Hello world!")
print("Token IDs:", token_ids) # [101, 7592, 2088, 102]
# 反向解码
decoded_text = tokenizer.decode([101, 7592, 2088, 102])
print("Decoded:", decoded_text) # "[CLS] hello world! [SEP]"
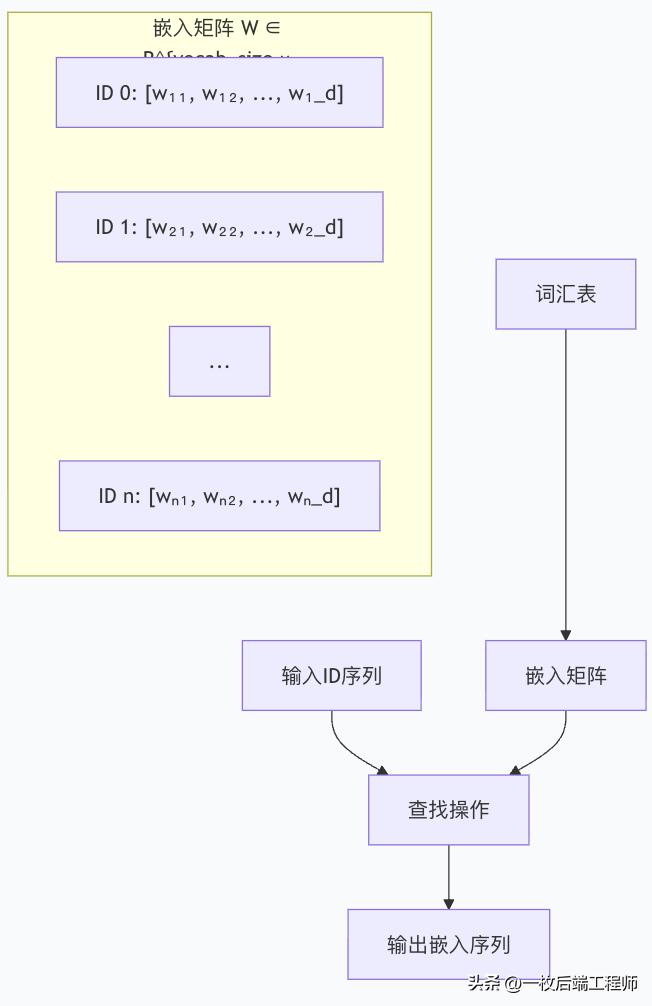
步骤3:词嵌入 - 从离散到连续的魔法
词嵌入的核心思想
词嵌入将离散的token ID映射到连续的向量空间:
离散ID: [101, 7592, 2088, 102]
↓ 嵌入矩阵查找
连续向量:
[0.1, 0.4, -0.2, ..., 0.8] # CLS token
[0.3, -0.1, 0.5, ..., 0.2] # "hello"
[-0.2, 0.6, 0.1, ..., -0.3] # "world"
[0.4, 0.2, -0.3, ..., 0.6] # SEP token
代码实现词嵌入层
import torch
import torch.nn as nn
import numpy as np
class TokenEmbedding(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
def forward(self, token_ids):
# token_ids: [batch_size, seq_len]
# 返回: [batch_size, seq_len, embedding_dim]
return self.embedding(token_ids)
# 实际使用示例
vocab_size = 50000
embedding_dim = 512 # 常见维度: 512, 768, 1024
embedding_layer = TokenEmbedding(vocab_size, embedding_dim)
# 输入: 批次大小为2, 序列长度为5
input_ids = torch.tensor([
[101, 7592, 2088, 102, 0], # 句子1
[101, 4875, 2031, 102, 0] # 句子2
])
# 获取词嵌入
word_embeddings = embedding_layer(input_ids)
print("嵌入形状:", word_embeddings.shape) # torch.Size([2, 5, 512])
词嵌入的可视化理解
词向量的语义特性
经过训练后,词向量会捕捉丰富的语义关系:
# 语义关系的向量运算示例
def analogical_reasoning(embedding_layer, word1, word2, word3, word_to_id):
# 获取词向量
vec1 = embedding_layer(torch.tensor([word_to_id[word1]]))
vec2 = embedding_layer(torch.tensor([word_to_id[word2]]))
vec3 = embedding_layer(torch.tensor([word_to_id[word3]]))
# 类比推理: king - man + woman ≈ queen
result_vector = vec1 - vec2 + vec3
# 在实际中,我们会计算与所有词向量的相似度
# 找到最接近的结果词
return result_vector
# 实际中,这种语义关系是通过大规模训练自然涌现的
步骤4:位置编码 - 注入顺序信息
为什么需要位置编码?
由于Transformer的自注意力机制是置换不变的(打乱输入顺序可能得到相同输出),需要显式注入位置信息。
正弦位置编码
import math
def sinusoidal_positional_encoding(seq_len, d_model):
"""
生成正弦位置编码
seq_len: 序列长度
d_model: 模型维度(嵌入维度)
"""
position = torch.arange(seq_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) *
-(math.log(10000.0) / d_model))
pe = torch.zeros(seq_len, d_model)
pe[:, 0::2] = torch.sin(position * div_term) # 偶数维度
pe[:, 1::2] = torch.cos(position * div_term) # 奇数维度
return pe
# 示例:生成长度为10,维度为512的位置编码
pos_encoding = sinusoidal_positional_encoding(10, 512)
print("位置编码形状:", pos_encoding.shape) # torch.Size([10, 512])
位置编码的可视化

完整的位置感知嵌入
class TransformerInputEmbedding(nn.Module):
def __init__(self, vocab_size, d_model, max_seq_len=512):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size, d_model)
self.position_embedding = nn.Parameter(
torch.zeros(1, max_seq_len, d_model)
)
self.layer_norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, token_ids):
# 词嵌入
token_embeddings = self.token_embedding(token_ids)
# 位置嵌入(截取到实际序列长度)
seq_len = token_ids.size(1)
position_embeddings = self.position_embedding[:, :seq_len, :]
# 相加并归一化
embeddings = token_embeddings + position_embeddings
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
步骤5:完整流程代码示例
import torch
import torch.nn as nn
class CompleteTextToVector(nn.Module):
def __init__(self, vocab_size, d_model=512, max_seq_len=512):
super().__init__()
self.d_model = d_model
# 1. 词嵌入层
self.token_embedding = nn.Embedding(vocab_size, d_model)
# 2. 位置编码(可学习或正弦)
self.position_embedding = nn.Parameter(
torch.randn(1, max_seq_len, d_model)
)
# 3. 层归一化和dropout
self.layer_norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(0.1)
def forward(self, input_ids):
batch_size, seq_len = input_ids.shape
# 词嵌入查找
token_embeds = self.token_embedding(input_ids) # [batch, seq_len, d_model]
# 添加位置信息
position_embeds = self.position_embedding[:, :seq_len, :]
embeddings = token_embeds + position_embeds
# 归一化和正则化
embeddings = self.layer_norm(embeddings)
embeddings = self.dropout(embeddings)
return embeddings
# 使用示例
vocab_size = 50000
model = CompleteTextToVector(vocab_size)
# 模拟输入:批次大小=2, 序列长度=8
input_ids = torch.randint(0, vocab_size, (2, 8))
# 转换为向量
output_vectors = model(input_ids)
print("输入形状:", input_ids.shape) # torch.Size([2, 8])
print("输出形状:", output_vectors.shape) # torch.Size([2, 8, 512])
三、不同嵌入策略的对比
静态vs动态词嵌入

对比表格
|
特性 |
传统静态嵌入 |
Transformer动态嵌入 |
|
上下文处理 |
每个词固定向量 |
根据上下文动态调整 |
|
多义词处理 |
一个向量表示所有含义 |
不同上下文不同向量 |
|
训练方式 |
预训练后固定 |
端到端联合训练 |
|
示例 |
Word2Vec, GloVe |
BERT, GPT, T5 |
|
向量质量 |
"bank"只有一个向量 |
"river bank"和"money bank"向量不同 |
四、向量化的意义与价值
1.语义空间的几何结构
经过良好训练的向量空间具有优美的数学结构:
语义相近 → 向量距离近 语义相反 → 向量方向相反 语义关系 → 向量运算可表达
2.模型能力的基石

3.实际应用价值
- 相似度计算:通过余弦相似度比较文本相似度
- 语义搜索:在向量空间中快速检索相关文档
- 文本分类:基于向量表示进行情感分析、主题分类
- 机器翻译:在不同语言的向量空间之间建立映射
总结:数字化的语言革命
文字向量化不仅是技术实现,更是思维范式的转变:
从符号到向量的哲学意义
- 传统语言学:研究符号之间的关系和规则
- 向量语义学:在连续空间中捕捉语义的相似性和关联性
技术演进的价值
这个过程让计算机从字面理解进化到语义理解,从规则驱动进化到数据驱动,最终实现了真正意义上的语言智能。
向量化就像为人类语言和计算机思维之间搭建了一座桥梁,让两种完全不同的"思维方式"能够相互理解和沟通。这正是现代自然语言处理技术能够取得突破性进展的根本基础。


















 952
952

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











