




1 Transformer参数大小的影响及机制
1.1 参数如何影响模型能力
在Transformer模型中,参数是模型内部结构的核心要素,它们如同模型的 "脑细胞" ,存储着从训练数据中学到的知识和模式。这些参数主要包括:
- 权重:在神经网络中扮演类似 "电线" 的角色,连接各个神经元,调整信号传递的强度
- 注意力机制参数:包括查询矩阵、键矩阵和值矩阵等,功能如同 "指南针" ,在复杂信息中精准找出最具价值的相关线索
1.2 为什么参数越多模型越"聪明"
参数规模与模型性能的关系可以通过以下示意图理解:
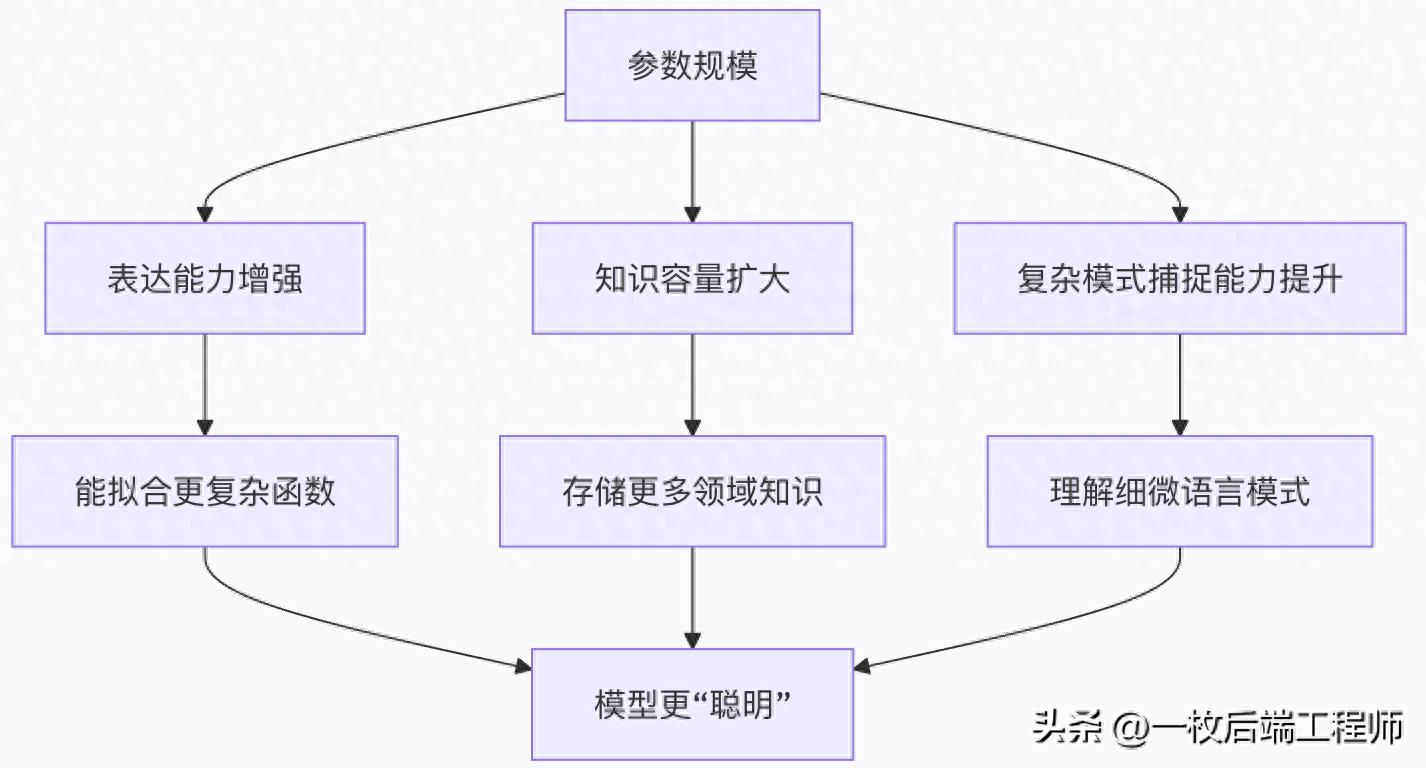
具体来说,参数增加的益处体现在:
- 知识容量扩大:更多参数意味着模型可以存储更多事实、概念和关系。例如,GPT-3凭借1750亿参数,能够处理多种复杂的语言任务,如文本生成、机器翻译和问答系统
- 复杂模式识别:大规模参数使模型能够捕捉数据中更细微、更复杂的特征和关系,从而在处理歧义、理解上下文细微差别方面表现更好
- 泛化能力提升:足够多的参数可以帮助模型从大量训练数据中学习通用规律,而非简单地记忆特定示例
1.3 参数规模的边际效应与局限
然而,参数规模并非越大越好,存在明显的边际效应:
- 性能饱和现象:随着参数增加,性能提升会逐渐趋于平缓
- 过参数化风险:参数过多可能导致模型过于复杂,捕捉数据中的噪声而非真实模式,引发过拟合,降低泛化能力
- 计算资源暴增:大参数模型需要巨大的计算资源来训练和推理,包括高性能CPU/GPU/TPU及大量内存存储
2 影响参数量的因素及实际模型分析
2.1 影响参数数量的主要因素
Transformer模型的参数总量主要由以下因素决定:
2.1.1 模型架构维度
- 隐藏层维度:模型中间表示的维度大小,直接影响所有全连接层的参数数量
- 层数:Transformer编码器/解码器的堆叠层数,每层都有自注意力和前馈子层
- 注意力头数:多头注意力机制中的头数量,每个头都有独立的Q、K、V投影矩阵
2.1.2 模型架构类型
- 稠密模型:所有参数对每个输入都激活,如BERT、GPT系列
- 混合专家模型:只有部分参数在处理每个输入时被激活,如DeepSeek-V3有671B总参数但仅激活37B,大幅提升效率
2.2 实际大模型参数规模分析
2.2.1 Qwen系列模型参数
Qwen系列展示了参数规模的演进路径:
- Qwen-7B和Qwen-14B:基础版本,分别拥有70亿和140亿参数
- Qwen2-72B:拥有720亿参数,采用80层Transformer结构,8192维隐藏层与64个查询头
Qwen2-72B通过分组查询注意力机制优化推理效率,支持128K tokens长上下文处理能力,在代码生成、数学计算和多语言理解等场景展现显著优势。
2.2.2 DeepSeek系列模型参数
DeepSeek模型采用了创新的混合专家架构:
- DeepSeek-V3:总参数671B,但每个token仅激活37B参数
- DeepSeek-V3.1:同样保持671B总参数和37B激活参数的设计,支持128K上下文长度
这种设计实现了"大象与蝴蝶的平衡" - 拥有庞大的知识库(总参数),却能高效灵活地处理任务(激活参数),兼具强大能力和高效推理。
2.3 参数存储与内存需求
2.3.1 参数存储格式
大模型参数通常以多种格式存储,在精度和存储空间间权衡:
|
存储格式 |
比特数 |
每个参数占用空间 |
典型应用场景 |
|
Float32 |
32比特 |
4字节 |
早期模型训练 |
|
Half/BF16 |
16比特 |
2字节 |
训练和推理平衡 |
|
Int8 |
8比特 |
1字节 |
资源受限环境 |
|
Int4 |
4比特 |
0.5字节 |
极端压缩场景 |
2.3.2 内存需求估算
以基于Transformer的大模型为例,内存需求可通过以下公式粗略估算:
训练内存 ≈ (参数数量 × 每个参数字节数) + (批次大小 × 序列长度 × 隐藏维度 × 精度字节数)
7B参数模型推理内存需求:
- Float32精度:约28GB
- BF16精度:约14GB
- Int8精度:约7GB
3 参数效率与未来发展方向
3.1 提高参数效率的技术
面对参数规模的限制,业界开发了多种参数效率优化技术:
- 混合专家架构:如DeepSeek-V3,大幅减少激活参数数量
- 模型压缩:包括参数剪枝(移除不重要参数)、量化(降低参数精度)和知识蒸馏(大模型教小模型)
- 并行计算优化:通过模型并行、数据并行和混合并行策略,分布式处理超大参数模型
3.2 参数规模的明智选择
在实际应用中,选择参数规模需考虑:
- 任务复杂度:简单任务可能不需要极大模型
- 实时性要求:资源受限场景中,较小参数模型可能更合适
- 成本约束:大参数模型需要巨大的计算资源
研究表明,更大的模型对压缩技术有更强的鲁棒性 - 高度压缩的大型模型比轻度压缩的小型模型可能获得更高精度。
结论
Transformer参数规模是模型能力的关键决定因素,但并非唯一因素。参数增加通过扩大知识容量和增强复杂模式识别能力使模型更"聪明",但存在边际效应和过拟合风险。现代大模型如Qwen2-72B和DeepSeek-V3展示了如何通过智能架构设计在参数规模与效率间取得平衡。
未来趋势不再是单纯追求参数数量,而是专注于提升参数效率 - 通过更优的架构、训练方法和压缩技术,让每个参数发挥更大价值。在实际应用中,选择合适的而非最大的参数规模,才是明智的技术决策。


















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











