




1. 分布式系统的本质与价值
什么是分布式系统?
官方定义:分布式系统是由多个独立的计算机节点通过网络连接,协同完成共同任务的系统。这些节点对用户表现为一个统一的整体。
通俗理解:就像一支专业的足球队,每个球员(节点)有明确的分工,通过默契配合(网络通信)完成进球(业务目标)的整体任务。
依稀记得之前老师举的一个很形象的例子:用一堆2C4G配置电脑替代一个配置8C64G的(2012年配置很顶了)电脑。
为什么需要分布式系统?解决的核心问题
1. 突破单机性能瓶颈
// 单体架构的性能天花板
public class MonolithicService {
// 单机硬件限制:CPU、内存、磁盘I/O、网络带宽
// 随着用户量增长,性能曲线逐渐平坦
public void handleRequest() {
// 单个服务器很快达到性能极限
if (currentLoad > MAX_CAPACITY) {
throw new RuntimeException("系统过载!");
}
}
}
2. 高可用性与故障容错
单点故障风险 vs 分布式容错设计
单体架构:┌─────────────┐ 分布式:┌─────┐ ┌─────┐ ┌─────┐
│ 单台服务器 │ │节点A│ │节点B│ │节点C│
│ 宕机 │──故障──> │正常 │ │正常 │ │正常 │
└─────────────┘ └─────┘ └─────┘ └─────┘
服务完全中断! 服务继续可用!
3. 业务解耦与团队协作
# 微服务架构示例:各团队独立负责特定服务
teams:
- name: 用户团队
service: user-service
tech-stack: [SpringBoot, MySQL]
- name: 订单团队
service: order-service
tech-stack: [SpringCloud, PostgreSQL]
- name: 支付团队
service: payment-service
tech-stack: [Dubbo, Redis]
4. 地理分布与低延迟
全球用户访问优化: 纽约用户 ──→ 美东数据中心 │ 北京用户 ──→ 北京数据中心 伦敦用户 ──→ 欧洲数据中心 │ 上海用户 ──→ 上海数据中心 相比单一数据中心:减少网络延迟,提升用户体验
2. CAP定理:分布式系统的"不可能三角"
CAP概念详解
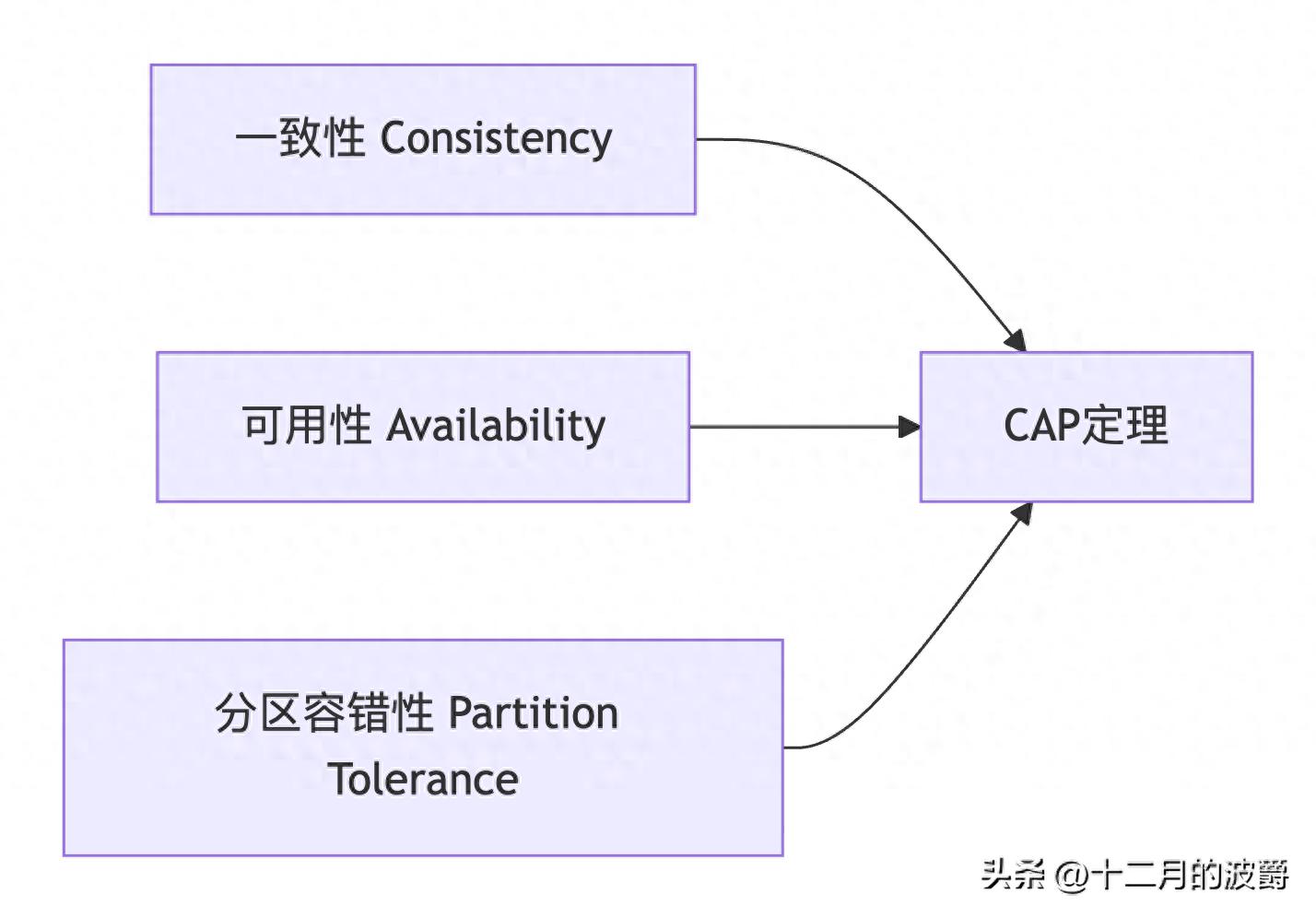
C(一致性):所有节点在同一时间看到的数据完全相同
// 强一致性示例:读写都要保证数据最新
public class ConsistentSystem {
public void writeData(String key, String value) {
// 写入必须同步到所有节点
node1.write(key, value);
node2.write(key, value); // 必须成功
node3.write(key, value); // 必须成功
}
public String readData(String key) {
// 读取总能获得最新写入的数据
return node1.read(key); // 保证是最新值
}
}
A(可用性):每个请求都能获得响应(不保证是最新数据)
public class AvailableSystem {
public String readData(String key) {
// 即使数据不是最新,也立即返回响应
if (node1.isAlive()) return node1.read(key);
if (node2.isAlive()) return node2.read(key); // 不保证一致性
if (node3.isAlive()) return node3.read(key);
throw new RuntimeException("服务不可用");
}
}
P(分区容错性):系统在网络分区情况下继续运作
public class PartitionTolerantSystem {
public void handleNetworkPartition() {
// 网络发生分区:节点A、B能通信,但与C断开
// 系统仍然需要继续提供服务
if (networkPartitionOccurs) {
// 在分区内继续服务,而不是完全停止
continueServiceInPartition();
}
}
}
为什么不能同时满足CAP?
网络分区的必然性:
// 分布式系统中,网络分区是必然发生的
public class NetworkReality {
public void inevitablePartitions() {
// 现实世界中的网络问题:
switch (networkIssue) {
case CABLE_CUT: // 光缆被挖断
case SWITCH_FAILURE: // 交换机故障
case FIREWALL_ISSUE: // 防火墙配置错误
case ISP_OUTAGE: // ISP服务中断
case NATWORK_CONGESTION:// 网络拥堵
// 这些都无法100%避免
break;
}
}
}
三选二的现实约束:
|
选择组合 |
实际表现 |
典型系统 |
适用场景 |
|
CA(放弃P) |
强一致性+高可用,但无法容忍网络分区 |
单机数据库、关系型数据库集群 |
网络稳定的内部系统 |
|
CP(放弃A) |
强一致性+分区容错,但可能拒绝服务 |
ZooKeeper、etcd、HBase |
配置管理、分布式锁 |
|
AP(放弃C) |
高可用+分区容错,但数据可能不一致 |
Cassandra、DynamoDB、Eureka |
社交网络、实时性要求不高的系统 |
3. BASE理论:CAP的工程实践妥协
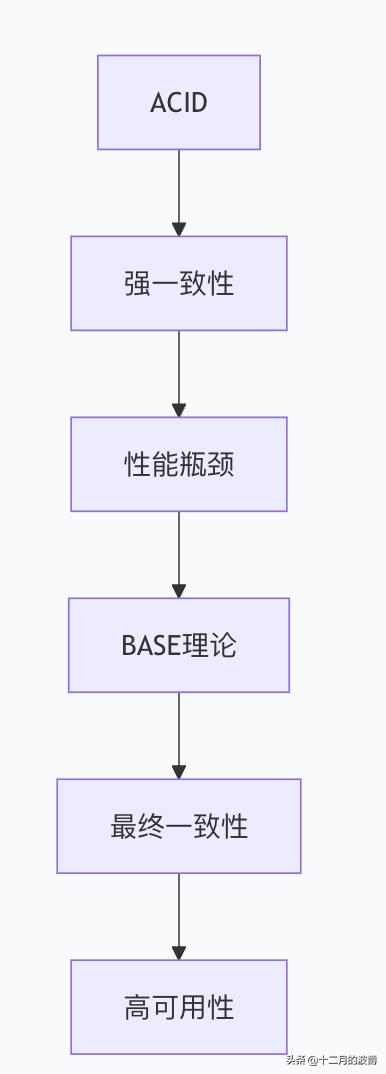
BASE概念解析
BA(基本可用 - Basically Available)
public class BasicallyAvailableService {
// 核心服务降级,保证基本功能可用
@HystrixCommand(fallbackMethod = "degradedService")
public Response premiumFeature() {
// 正常情况下提供完整功能
return fullFeatureService();
}
public Response degradedService() {
// 系统压力大时,提供简化版服务
return basicFeatureService(); // 保证核心功能
}
}
S(软状态 - Soft State)
public class SoftStateExample {
private String intermediateState; // 允许中间状态存在
public void asyncDataSync() {
// 数据同步过程中允许不一致状态
updateCacheAsync(); // 异步更新缓存
sendMessageAsync(); // 异步发送消息
// 此时系统处于"软状态"
}
}
E(最终一致性 - Eventual Consistency)
public class EventualConsistency {
public void transferMoney(String from, String to, BigDecimal amount) {
// 1. 扣减转出账户(立即生效)
accountService.debit(from, amount);
// 2. 异步增加转入账户(最终一致)
messageQueue.send(new TransferMessage(to, amount));
// 短时间内转入账户可能看不到资金
// 但最终所有节点数据会一致
}
}
BASE解决的核心问题
平衡一致性与性能的矛盾:
public class BalanceSolution {
// ACID方案:强一致性但性能低
@Transactional // 全局锁,性能瓶颈
public void acidOperation() {
// 所有操作在一个事务中
step1();
step2(); // 阻塞其他操作
step3();
}
// BASE方案:最终一致性但高吞吐
public void baseOperation() {
// 分解为多个可并行的步骤
CompletableFuture<Void> task1 = CompletableFuture.runAsync(this::step1);
CompletableFuture<Void> task2 = CompletableFuture.runAsync(this::step2);
CompletableFuture<Void> task3 = CompletableFuture.runAsync(this::step3);
// 通过补偿机制保证最终一致
CompletableFuture.allOf(task1, task2, task3)
.exceptionally(this::compensate); // 异常时回滚
}
}
4. 共识算法:分布式一致性的技术基石
共识算法的本质定义
共识算法是分布式系统中多个独立节点就某个值(或状态)达成一致的分布式协议。它是在存在节点故障、网络延迟、分区等不可靠因素的环境中,确保系统一致性的核心技术。
分布式环境面临的三大问题

共识算法要解决的核心问题
问题1:领导者选举(Leader Election)
场景:多个节点都需要写入数据,但必须避免冲突,防止脑裂问题
需要解决:谁有权限执行写操作? 没有共识:节点A、B、C都尝试写入 → 数据冲突 有共识:选举出唯一Leader,只有Leader可以写入
问题2:数据一致性(Data Consistency)
场景:客户端向不同节点读取数据,应该得到相同结果
需要解决:如何保证所有节点数据同步? 没有共识:节点A有最新数据,节点B还是旧数据 → 读取不一致 有共识:所有写操作通过Leader同步,保证最终一致
问题3:容错处理(Fault Tolerance)
场景:部分节点故障或网络中断
需要解决:系统能否继续正常工作? 没有共识:一旦有节点故障,整个系统可能停滞 有共识:多数派节点正常即可继续服务(N/2+1原则)
问题4:顺序保证(Total Order)
场景:多个客户端并发操作
需要解决:操作的全局顺序如何确定? 没有共识:操作顺序混乱,可能A→B和B→A同时发生 有共识:所有操作有全局唯一顺序编号
主要共识算法分类
1. Paxos家族:理论奠基者
2. Raft算法:工程友好型
总结
分布式系统通过将任务分散到多个节点,解决了单机系统的性能瓶颈和单点故障问题。CAP定理揭示了分布式系统设计的根本约束,而BASE理论提供了在工程实践中平衡一致性与可用性的方法论。共识算法则是实现分布式一致性的技术基础,确保在复杂网络环境下系统能够可靠运行。


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











