




数据在计算机内存中的存储方式是计算机科学的核心基础之一,它涵盖了数据的表示方法、组织结构和访问机制,下面我将系统地讲解几个关键要点,确保信息准确可靠。

1.整数在内存中的储存
在整个计算机系统,整数在内存中是以二进制的形式进行存储和运用,但是整数的二进制又有三种表达形式:
即原码、反码、补码。
①原码:直接将数值按照正负数的形式翻译成⼆进制得到的就是原码
②反码:将原码的符号位不变,其他位依次按位取反就可以得到反码
③补码:反码+1就得到补码。(仅针对于负数)
温馨提示:
正整数的原、反、补码都相同。
问题探究:为什么对于整形来说,数据在内存中存放的是补码呢?
原因在于,使⽤补码,可以将符号位和数值域统⼀处理;同时,加法和减法也可以统⼀处理(CPU只有加法器)此外,补码与原码相互转换,其运算过程是相同的,不需要额外的硬件电路。
2.⼤⼩端字节序
在初步了解了整数在内存当中以何种形式的存储之后,我们想进一步了解其在内存中是以什么顺序进行存储的,以及是以什么方式进行取出得。
我们先看一段代码:
#include <stdio.h>
int main()
{
int a = 0x11223344;
return 0;
}
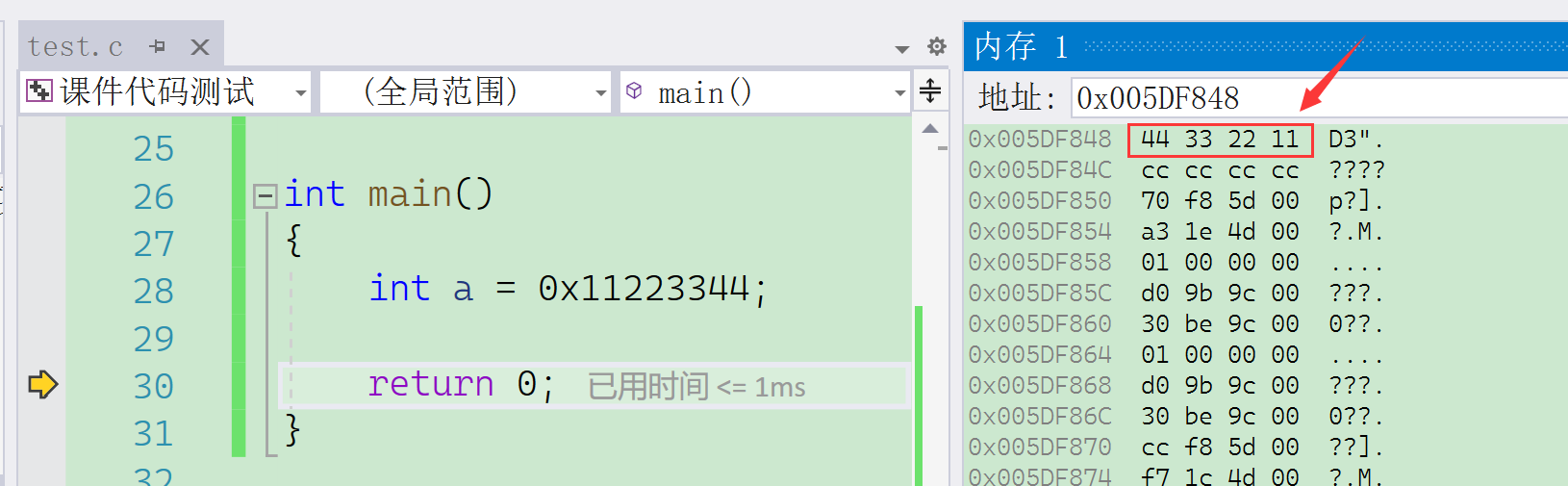
调试的时候,我们可以看到在a中的 0x11223344 这个数字是按照字节为单位,倒着存储的。这是为什么呢?要回答这个问题,这里就得引入大小端字节序这一概念,其实超过⼀个字节的数据在内存中存储的时候,就有存储顺序的问题,按照不同的存储顺序,我们分为⼤端字节序存储和⼩端字节序存储。
1.大端字节序
⼤端(存储)模式:是指数据的低位字节内容保存在内存的⾼地址处,⽽数据的⾼位字节内容,保存 在内存的低地址处。( 简单记忆为,低字节高地址,高字节低地址。)
2.小端字节序
⼩端(存储)模式:是指数据的低位字节内容保存在内存的低地址处,⽽数据的⾼位字节内容,保存 在内存的⾼地址处。( 简单记忆为,低字节低地址,高字节高地址。)
3.为什么有大小端字节序?
为什么会有⼤⼩端模式之分呢?这是因为在计算机系统中,我们以字节为单位的,每个地址单元都对应着⼀个字节。⼀个字节为8 bit 位,但是在C语⾔中除了8 bit 的 char 之外,还有16 bit 的 short型,32 bit 的 long 型(要看 具体的编译器)。另外,对于位数⼤于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度⼤于⼀个字节,那么必然存在着⼀个如何将多个字节安排的问题。因此就导致了⼤端存储模式和⼩端存储模式。
例如:⼀个 16bit 的 short 型 x ,在内存中 x 的地址为 0x0010 , x 的值为 0x1122 ,那么 0x11 为⾼字节, 0x22 为低字节。对于⼤端模式,就将 0x11 放在低地址中,即 0x0010 中,0x22 放在⾼地址中,即 0x0011 中。对于⼩端模式,刚好相反,将 0x11 放在高地址中,即0x0011,将0x22放在低地址中,0x0010。温馨提示:我们常⽤的 X86 结构是⼩端模式,⽽ KEIL C51 则为⼤端模式。很多的ARM,DSP都为⼩端模式。有些ARM处理器还可以由硬件来选择是 ⼤端模式还是⼩端模式。
3.练习与回顾
1.练习一
通过编写C/C++语言代码设计⼀个⼩程序来判断当前机器的字节序。
思路:
对于整数1来说:
① 1的二进制补码:00000000 00000000 00000000 00000001
② 1的十六进制形式下的补码:00 00 00 01
为了方便显示,在电脑中一般为十六进制形式,表示一个十六进制需要4个bit位,所以一个字节的数据需要2个十六进制的数字表示,但实际上还是以二进制形式储存,只是为了便于显示在电脑显示器中。
我们可以通过将 1 强行转化为char* 类型的指针,将整型变量int
i=1的地址强制转换为char *类型,这样pc就指向了int i=1的第一个字节,通过解引用后就能访问一个字节。
若其是 1 的话那么证明,低字节存放在低地址中,即小端字节序。
内存低地址 → 高地址 [01][00][00][00] ↑ pc指向此处
若是 0 的话低字节存放在高地址当中,即大端字节序。
内存低地址 → 高地址 [00][00][00][01] ↑ pc指向此处
void test0()
{
int i = 1;
//00000000 00000000 00000000 00000001 ---1 的二进制补码
//00 00 00 01 --- 1的十六进制形式下的补码
char* pc = (char*)&i;
if (*pc == 1)
{
printf("小端存储\n");
}
else
{
printf("大端存储\n");
}
}
int main()
{
test0();
return0;
}
运行结果如下图:

2.练习二
根据代码,求出运行结果。
#include <stdio.h>
int main()
{
char a= -1;
signed char b=-1;
unsigned char c=-1;
printf("a=%d,b=%d,c=%d",a,b,c);
return 0;
}
要解决这个问题,首先我们要了解:
① char signed char unsigned char 三个数据类型是如何进行存储数据
对于 char 能储存一个字节大小(八个bit位)的数据 (一般表示有符号)
1.可声明为有符号的数据 signed char
2.可声明为无符号的数据 unsigned char
以 -1 为例
1.原码为:10000000 00000000 00000000 00000001
2.反码为:11111111 11111111 11111111 11111110
3.补码为:11111111 11111111 11111111 11111111
由于char 类型只能存储一个字节(八个bit位大小)
①char 类型储存的补码为 11111111 其最高位表示符号位
②signed char 类型储存的补码为 11111111 其最高位表示符号位
③unsigned char 类型储存的补码为 11111111 其最高位表示数值位
但由于是以 "%d" (
signed int)的形式进行打印,所以需要提升到整形,即四个字节大小 ,(三十二个bit位大小)。
%d的输出逻辑:
%d的作用是将内存中以补码存储的二进制数,解释为有符号整数,并直接转换为对应的十进制值。
它的工作流程是:读取内存中补码的二进制位。根据最高位(符号位)判断正负:
①若最高位为 1(负数):自动按照补码规则反推其对应的十进制负值(本质是补码的 “逆运算”,但对用户来说是透明的)。
②若最高位为 0(正数):直接将补码(即原码)转换为十进制输出。
1.对于char 类型:高位补符号位 1
即补码提升为: 11111111 11111111 11111111 11111111
故打印结果为 a = -1
2.对于signed char 类型:高位补符号位 1
即补码提升为: 11111111 11111111 11111111 11111111
故打印结果为 b = -1
3.对于unsigned char :高位补0
即补码提升为:00000000 00000000 00000000 11111111
打印结果为 c=255

②整形提升:
1. 有符号整数提升是按照变量的数据类型的符号位来提升的2. ⽆符号整数提升,⾼位补0
3.练习三
#include <stdio.h>
int main()
{
char a = -128;
printf("a=%u\n",a);
return 0;
}
由上面的知识,我们可以进行类比分析:
1. -128的原码为:10000000 00000000 00000000 10000000
2.-128的反码为:11111111 11111111 11111111 01111111
3.-128的补码为:11111111 11111111 11111111 10000000
-128存放在char类型(一个字节,八个bit位)的变量当中的补码就是10000000
若以%u进行打印需要进行整形提升(补充符号位,有符号补1无符号补0)
整形提升后的补码是11111111 11111111 11111111 10000000
温馨提示:
%u总是将数据视为非负整数,无论原数据是有符号还是无符号类型。
所以打印结果为:a=4294967168 (即
2^32 - 128)
4.练习四
#include <stdio.h>
int main()
{
char a = 128;
printf("%u\n",a);
return 0;
}
由上面的知识,我们可以进行类比分析:
1. 128的原码为:00000000 00000000 00000000 10000000
128存放在char类型(一个字节,八个bit位)的变量当中的补码就是10000000
若以%u进行打印需要进行整形提升(补充符号位,有符号补1无符号补0)
整形提升后的补码是11111111 11111111 11111111 10000000
温馨提示 :
%u总是将数据视为非负整数,无论原数据是有符号还是无符号类型。
所以打印结果为:a=4294967168 (即
2^32 - 128)
5.练习五
#include <stdio.h>
int main()
{
char a[1000];
int i;
for(i=0; i<1000; i++)
{
a[i] = -1-i;
}
printf("%d",strlen(a));
return 0;
}
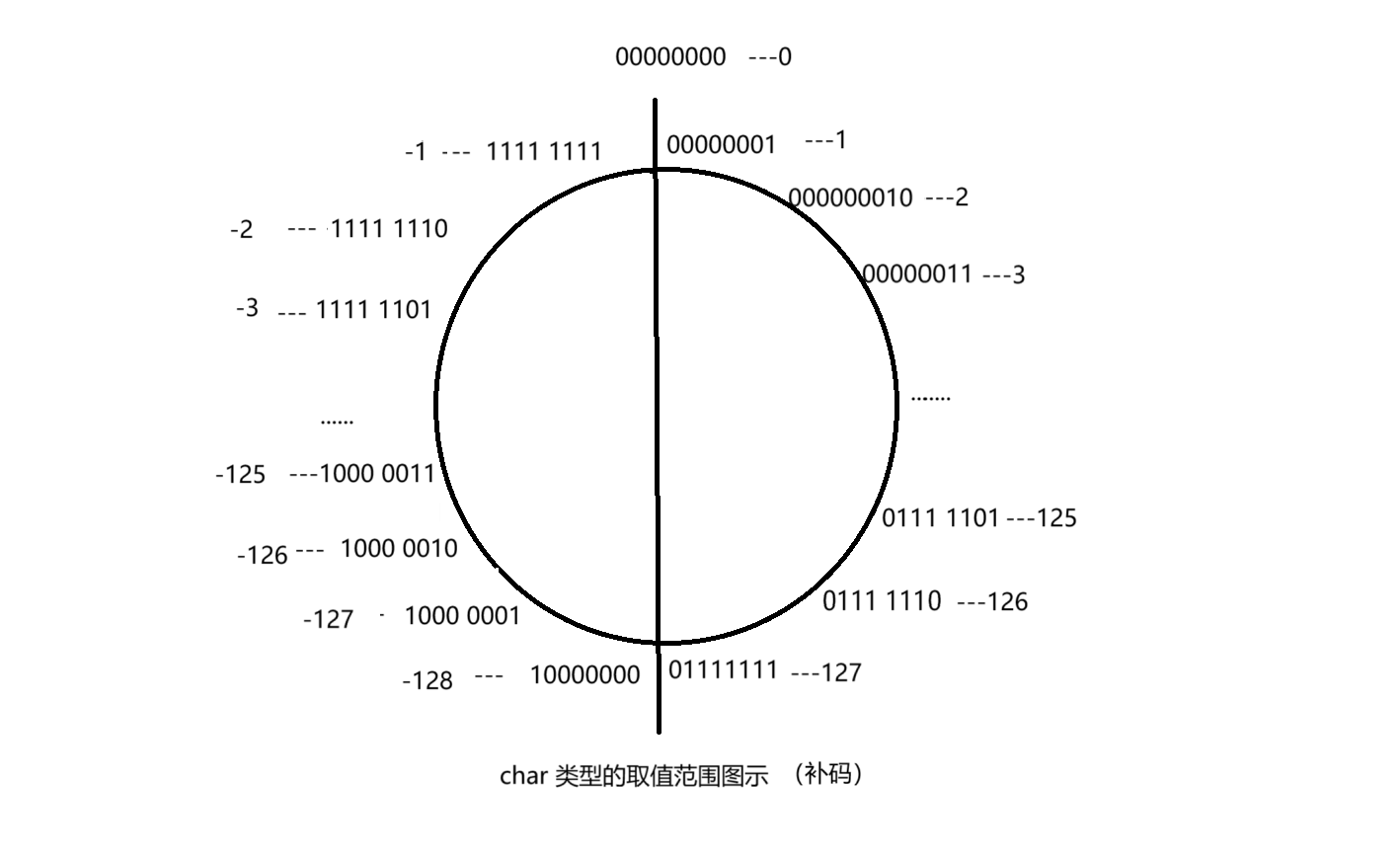
针对这道题我们要深入了解char类型的存储范围,对于char类型的取值范围我们可以通过图解的方式来记忆。
由图示可知:a[i]的值为: -1 -2 -3 -4 ...... -127 -128 127 126 125 ...... 4 3 2 1 0 ...... -1 -2
由strlen计算的是 ‘\0’ 前的数据个数,所以计算结果为 255
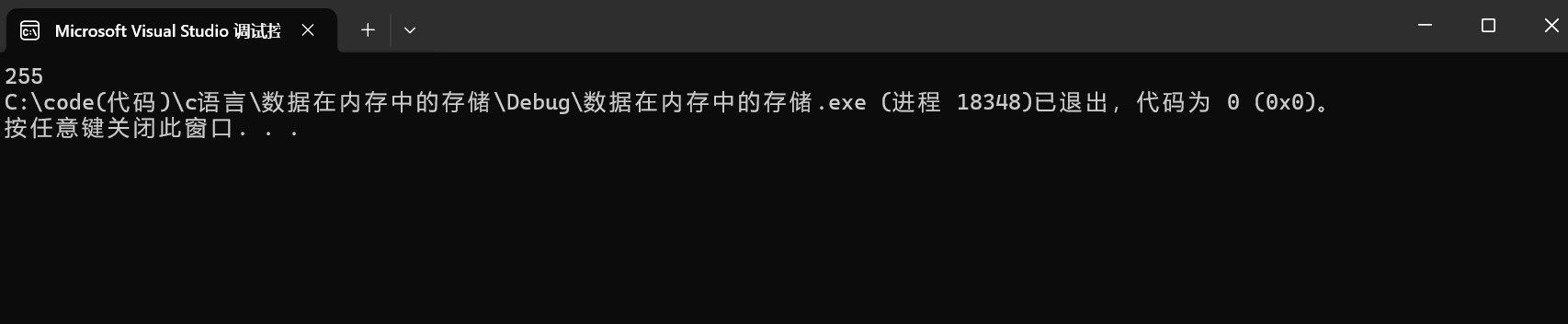
6.练习六
#include <stdio.h>
unsigned char i = 0;
int main()
{
for(i = 0;i<=255;i++)
{
printf("hello world\n");
}
return 0;
}
由于unsigned char 类型的取值范围是从 00000000 ~ 11111111
即范围大小为0~255
所以其结果为无限循环
7.练习七
#include <stdio.h>
int main()
{
unsigned int i;
for(i = 9; i >= 0; i--)
{
printf("%u\n",i);
}
return 0;
}
unsigned int 类型是恒大于0的数,所以该循环无限执行
8.练习八
假设改计算机在x86环境下,即小端存储模式
#include <stdio.h>
int main()
{
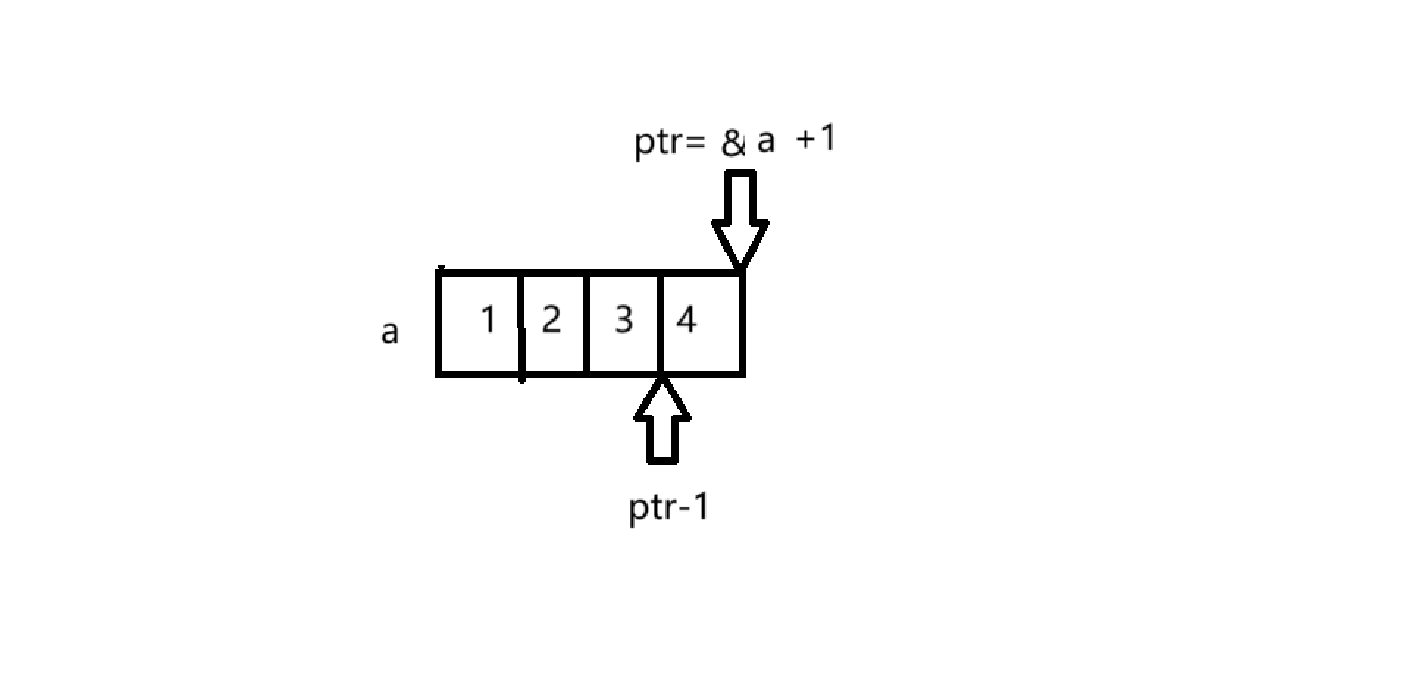
int a[4] = { 1, 2, 3, 4 };
int *ptr1 = (int *)(&a + 1);
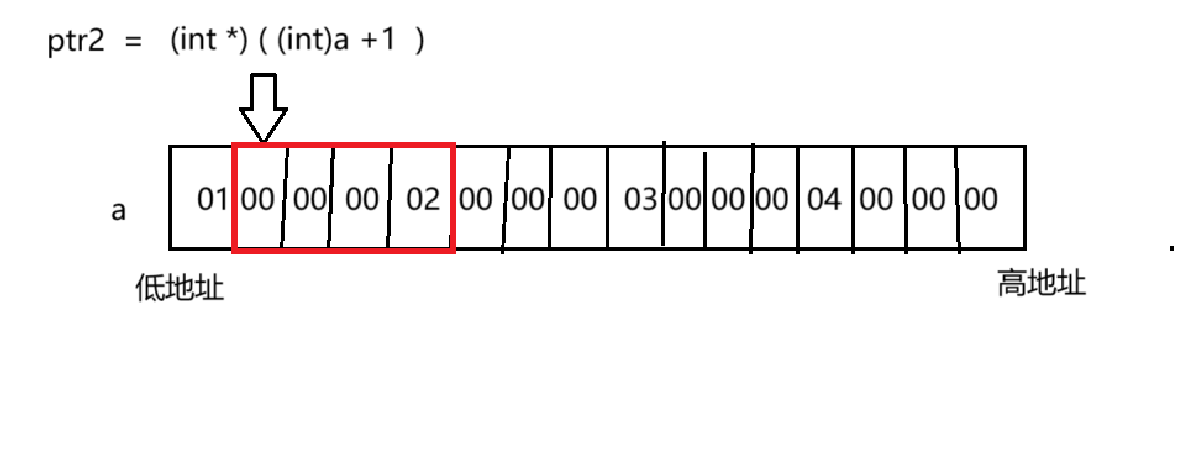
int *ptr2 = (int *)((int)a + 1);
printf("%x,%x", ptr1[-1], *ptr2);
return 0;
}
其指针图示:
&a是整个数组的地址,其类型为 int (*)[4] , &a+1 向后跳跃了整个数组的大小。
ptr为整形指针,ptr-1 向前跳跃了一个整形大小。
所以ptr[-1] 为 * (ptr-1) 其值为 4
将 a 这个地址转化为整形,整形+1即数值上加上1。
假设a的地址为 0x0012ff40 +1 -> 0x0012ff41 ,然后再将其转化为 int* 类型的指针
*ptr2 访问四个字节大小,因为是小端存储,低字节放在低地址上,高字节放在高地址上
所以 取出的结果为 02 00 00 00
综上的结果为:

4.浮点数在内存中的存储
1.浮点数初探
#include <stdio.h>
int main()
{
int n = 9;
float *pFloat = (float *)&n;
printf("n的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
*pFloat = 9.0;
printf("num的值为:%d\n",n);
printf("*pFloat的值为:%f\n",*pFloat);
return 0;
}
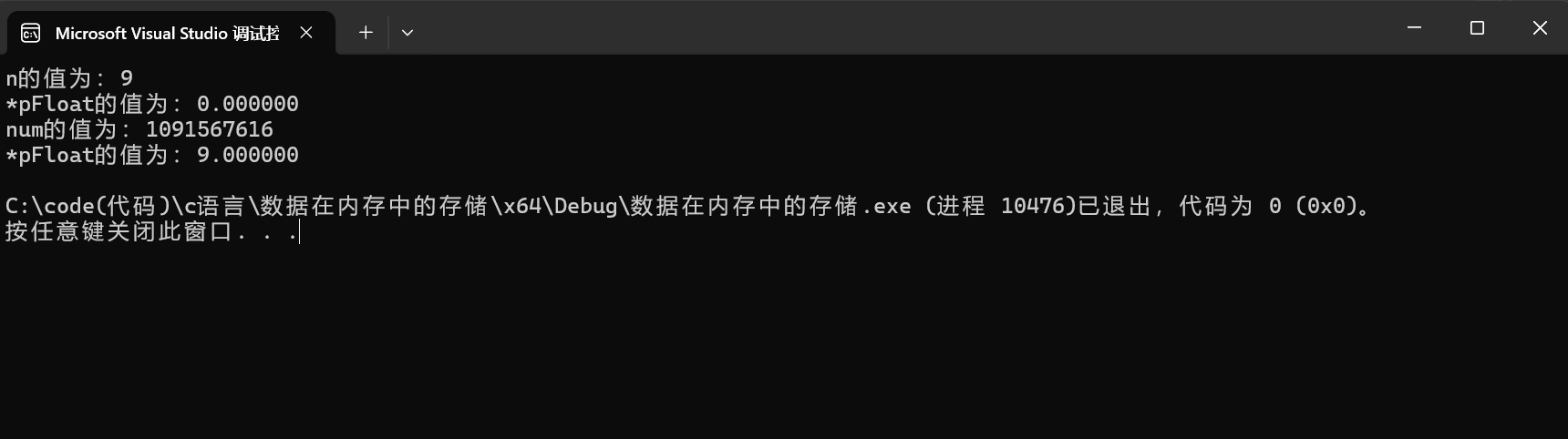
出现这种现象的原因是:
- 整数和浮点数在计算机内存中的存储方式完全不同
- 整数 9 和浮点数 9.0 的二进制表示截然不同
- 当使用不同类型的指针访问同一块内存时,会按照该类型的规则进行解析
为了深入了解这个输出结果我们就要了解浮点数在内存中是如何进行存储和使用。
2.浮点数的储存
根据国际标准IEEE754(电⽓和电⼦⼯程协会) ,任意⼀个⼆进制浮点数V可以表⽰成下⾯的形式:V = (−1) ^ S * M * 2 ^ E• (−1)^S : 表⽰符号位,当S=0,V为正数;当S=1,V为负数• M : 表⽰有效数字,M是⼤于等于1,⼩于2的 (1<=M<2)• 2 ^ E : 表⽰指数位
举例说明:以12.25为例
• 整数部分转换:使用除 2 取余法将整数 12 转换为二进制。
12÷2 = 6 余 0
6÷2 = 3 余 0
3÷2 = 1 余 1
1÷2 = 0 余 1
从下往上读取余数,得到整数部分的二进制表示为 1100。
• 小数部分转换:使用乘 2 取整法将小数 0.25 转换为二进制。
0.25×2 = 0.5 ,整数部分为 0
0.5×2 = 1.0 ,整数部分为 1
当小数部分为 0 时结束,得到小数部分的二进制表示为 01。
所以,12.25 的二进制表示为 1100.01 ,科学计数法后为 1.10001×2³ 。
V=(-1)^0 * 1.10001 * 2^3
按照上面V的格式表示为: S=0 M=1.10001 E=3
若是-12.25
二进制表示为-1100.01 ,科学计数法后为-1.10001×2³
按照上面V的格式表示为: S=1 M=1.10001 E=3
综上所述,要存储浮点数,即需存储 S M E 这三个数据
2.1 浮点数存的过程
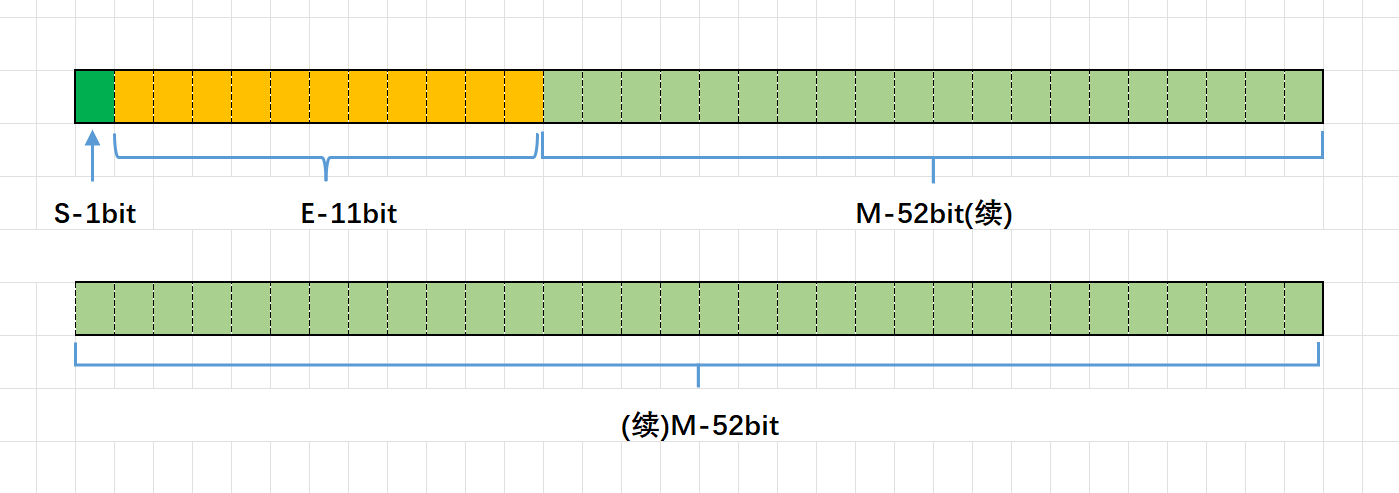
EEE 754规定:浮点数的内存分配如下图
对于32位的浮点数(float),最⾼的1位存储符号位S,接着的8位存储指数E,剩下的23位存储有效数字M

对于64位的浮点数(double),最⾼的1位存储符号位S,接着的11位存储指数E,剩下的52位存储有效数字M
特别注意 :
在存储的过程中,IEEE 754 对有效数字M和指数E,还有⼀些特别规定。
对于M的规定如下:
前⾯说过, 1≤M<2 ,也就是说,M可以写成 1.xxxxxx 的形式,其中 xxxxxx 表⽰M的⼩数部分。
根据IEEE 754 规定,在计算机内部保存M时,默认这个数的第⼀位总是1,因此可以被舍去,只保存后⾯的xxxxxx部分。
举个栗子:
⽐如保存1.01的时候,只保存01,等到读取的时候,再把第⼀位的1加上去。这样做的
⽬的是节省1位有效数字。以32位浮点数为例,留给M只有23位,将第⼀位的1舍去以后,等
于可以保存24位有效数字。 (M的23位数字,加上舍去的第一位的1)
对于E的规定如下:
⾸先,E为⼀个⽆符号整数(unsigned int):
①如果E为8位,它的取值范围为0~255; ②如果E为11位,它的取值范围为0~2047。
但是,我们知道,科学计数法中的E是可以出现负数的,所以IEEE 754规定,存⼊内存时E的真实值必须再加上⼀个中间数。
①对于8位的E,这个中间数是127; ②对于11位的E,这个中间数是1023。
举个栗子:
1.01 * 2^10 的E是10,所以保存成32位浮点数时,必须保存成10+127=137,即10001001。
2.2 浮点数取的过程
指数E从内存中取出还可以再分成三种情况:
① E不全为0或不全为1
这时,浮点数就采⽤下⾯的规则表⽰,即指数E的计算值减去127(或1023),得到真实值,再将有效数字M前加上第⼀位的1。
⽐如: 0.5 的⼆进制形式为0.1,用科学计数法表示则为:(-1) ^ 0 * 1.0 * 2 ^ (-1)。
S的存储:存储为0
E的存储:32位下加上中间值127,其阶码为-1+127(中间值)=126,表⽰为01111110。
M的存储:尾数1.0去掉整数部分1,剩余为0,补⻬0到23位00000000000000000000000
综上所述则其⼆进制表⽰形式为: 0 01111110 00000000000000000000000
②E全为0
这时,浮点数的指数E等于1-127(或者1-1023)即为真实值,有效数字M不再加上第⼀位的1,⽽是还原为0.xxxxxx的⼩数。这样做是为了表⽰±0,以及接近于0的很⼩的数字。
例如:
0 00000000 00100000000000000000000
③E全为1
这时,如果有效数字M全为0,表⽰±⽆穷⼤(正负取决于符号位s);
例如:
0 11111111 00010000000000000000000
3.浮点数再探
通过学习了上面的知识,对于我们可以深入理解这段代码
#include <stdio.h>
int main()
{
int n = 9;
float *pFloat = (float *)&n;
printf("n的值为:%d\n",n); //---①
printf("*pFloat的值为:%f\n",*pFloat); //---②
*pFloat = 9.0;
printf("num的值为:%d\n",n); //---③
printf("*pFloat的值为:%f\n",*pFloat); //---④
return 0;
}
对于①:
显然打印结果为n的值为:9
对于②:
浮点型指针 pFloat 将整形变量 n 视为浮点型,我们知道整形变量n以二进制补码储存在计算机中。
若视为浮点型:
S E M
0 00000000 00000000000000000001001
浮点数的指数,若E为全0,则E=1-127 --> -126
有效数字M,取出后不加上1
该数被解析为: (-1)^0 * 0.000000000000000000001001 * 2 ^ (-126)
故而打印结果为:*pFloat为0
对于③、④:
以浮点数的形式存储到 *pFloat中
9.0的浮点二进制为: 1001.0
二进制科学计数法的形式: 1.001 * 2^3 (-1)^0 * 1.001 * 2^3
S=0 E=3 M=1.001
S E M
内存中的储存结果为: 0 10000010 00100000000000000000000
针对于③:以%d的形式进行打印,直接将上述内存以二进制补码进行打印,而非浮点数:
0 10000010 00100000000000000000000
故而打印结果为:num为1,091,567,616
针对于④:以%f的形式进行打印,将内存存储的结果,按照浮点型的储存方式还原为 9.0

















 2172
2172




 到【灌水乐园】发言
到【灌水乐园】发言







