




前言:C语⾔已经提供了内置类型,如:char、short、int、long、float、double等,但是只有这些内置类型还是不够的。
假设我想描述学⽣,描述⼀本书,这时单⼀的内置类型是不⾏的。描述⼀个学⽣需要名字、年龄、学号、⾝⾼、体重等;描述⼀本书需要作者、出版社、定价等。C语⾔为了解决这个问题,增加了结构体这种⾃定义的数据类型,让程序员可以⾃⼰创造适合的类型。

一、初识结构体
1.结构体的声明
结构体的语法模型如下:
struct tag //结构体的名称
{
member-list; //成员列表
} variable-list ; //变量列表
温馨提示:结尾的分号不要忘记
形如:描述一个学生结构体
struct stu
{
char name[20]; //名字
int age; //年龄
int high; //身高
double weight;//体重
char id[16]; //学号
}s4,s5,s6; // (全局)结构体变量
1.定义 stu 为结构体的名称
2. 通过下列数据类型,描述结构体成员变量:
char name[20]; //名字
int age; //年龄
int high; //身高
double weight;//体重
char id[16]; //学号
3. s4 s5 s6 为结构体变量,此时的结构体变量为全局变量
2.结构体变量的定义
声明了一个结构体后,如何进行对结构体变量的定义呢?有以下两种方式可以进行定义。
方法一:声明结构体的时候进行定义结构体变量
struct Point
{
int x;
int y;
}p1;
此时的 p1 就为结构体Point 的变量,注意此时的p1为全局变量
方法二:直接定义结构体变量
struct Point
{
int x;
int y;
};
struct Point p1; //此时为全局变量
int main()
{
struct Point p2; //此时为局部变量
return 0;
}
通过 struct + 结构体名 + 变量名 的方法直接定义
3.结构体变量的初始化
如何对结构体变量进行初始化呢? 其实类似于数组的初始化,但也有一定的区别
struct stu
{
char name[20]; //名字
int age; //年龄
int high; //身高
double weight;//体重
char id[16]; //学号
};
int main()
{
//按照顺序对结构体进行初始化
struct stu s1 = {"wang",20,180,70,"001"};
//自定义对结构成员进行初始化
struct stu s2 = {.age=21,.high=186,.name="li",.id="002",.weight=75};
return 0;
}
对结构体初始化可以分为两种形式:
①按照结构体中的成员变量,通过 {} 依次进行赋值,其中要用 ,的形式分隔各个变量
②通过 · + 成员变量名 的方式,可以对结构体变量以自定义的形式进行赋值操作
若结构中还含有结构体如何进行赋值呢?
struct S
{
char name[20];
int age;
};
struct B
{
struct S s;
int* p;
};
int main()
{
struct B b1 = { .p=NULL ,.s = {"zhang",20} };
struct B b2 = { {"zhang",20} , NULL };
return 0;
}
对于这种嵌套结构体而言,对结构体中的成员结构体,通过 {} 单独进行赋值
4.结构体的访问
针对于结构体的访问,也有如下两种方式:
方法一:通过 · 直接进行访问
#include<stdio.h>
struct stu
{
char name[20]; //名字
int age; //年龄
int high; //身高
double weight;//体重
char id[16]; //学号
};
int main()
{
struct stu s1 = {"wang",20,180,70,"001"};
printf("%s %d %d %.1f %s", s1.name, s1.age, s1.high, s1.weight, s1.id);
return 0;
}
方法二:利用 结构体指针 进行间接访问
#include <stdio.h>
struct Point
{
int x;
int y;
};
int main()
{
struct Point p = {3, 4};
struct Point *ptr = &p;
ptr->x = 10;
ptr->y = 20;
printf("x = %d y = %d\n", ptr->x, ptr->y);
return 0;
}
5.结构体传参
①通过以 传值 的形式进行传递参数:
void print1(struct S tmp)
{
for (int i = 0; i < 5; i++)
{
printf("%d ", tmp.arr[i]);
}
printf("\n%d ", tmp.n);
printf("\n%lf ", tmp.d);
}
int main()
{
struct S s ={ {1,2,3,4}, 100, 9.9};
print1(s);
return 0;
}
②通过以 传址 的形式进行传递参数
void print2(const struct S* ps)
{
for (int i = 0; i < 5; i++)
{
printf("%d ", ps->arr[i]);
}
printf("\n%d ", ps->n);
printf("\n%lf ", ps->d);
}
int main()
{
struct S s ={ {1,2,3,4}, 100, 9.9};
print2(&s);
return 0;
}
上⾯的 print1 和 print2 函数哪个好些?
分析:
函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。如果传递⼀个结构体对象的时候,结构体过⼤,参数压栈的的系统开销⽐较⼤,所以会导致性能的下降。
所以,结构体传参的时候,要传结构体的地址
二、深入结构体
1.结构体的特殊声明
在 C 语言中,匿名结构体(Anonymous Struct)是指没有显式命名的结构体类型,通常嵌套在其他结构体或联合体中使用。
匿名结构体的定义形式为:在结构体关键字struct后直接定义成员,不指定结构体名称
#include <stdio.h>
// 外层结构体包含匿名结构体
struct Student
{
int id;
int age;
// 匿名结构体(无名称)
struct
{
char first_name[20];
char last_name[20];
}; // 注意:匿名结构体后直接跟分号,无需名称
};
int main()
{
struct Student s = {
.id = 1001,
.first_name = "Zhang", // 直接访问匿名结构体的成员
.last_name = "San",
.age = 20
};
// 直接通过外层结构体变量访问匿名结构体的成员
printf("Student: %s %s, ID: %d, Age: %d\n", s.first_name, s.last_name, s.id, s.age);
return 0;
}
温馨提示:
- 匿名结构体必须嵌套在其他结构体或联合体中(不能单独定义匿名结构体变量)。
- 匿名结构体的成员可以被外层结构体 / 联合体 “直接访问”,无需通过结构体名称中转。
2.结构体的自引用
思考在结构中包含⼀个类型为该结构本⾝的成员是否可以呢? 答案是可以的。
比如,定义一个链表的结点:
struct Node
{
int data;
struct Node next;
};
但这段代码是否正确呢? 如果正确,sizeof(struct Node) 的大小是多少。
仔细分析,其实是不⾏的。
因为⼀个结构体中再包含⼀个同类型的结构体变量,这样结构体变量的⼤⼩就会⽆穷的⼤,是不合理的。
正确写法,通过结构体指针,存储下一个节点的信息:
struct Node
{
int data;
struct Node* next;
};
其中为了简化结构体变量的定义,可以通过typedef的形式,给结构体重新命名。
typedef struct Node
{
int data;
struct Node* next; //结构体自引用
}Node;
对这段代码的理解是:定义了一个结构体类型struct Node,重命名为Node。
这样的写法也等价于:
struct Node
{
int data;
struct Node* next;
};
typedef struct Node Node;
3.结构体内存对⻬
我们已经掌握了结构体的基本使⽤了,现在我们深⼊讨论⼀个问题:计算结构体的⼤⼩。
在计算结构体大小前,首先得了解规则:
1. 结构体的第⼀个成员对⻬到和结构体变量起始位置偏移量为0的地址处
2. 其他成员变量要对⻬到某个数字(对⻬数)的整数倍的地址处。
对⻬数 = 编译器默认的⼀个对⻬数 与 该成员变量⼤⼩的较⼩值。
- VS 中默认的值为 8
- Linux中 gcc 没有默认对⻬数,对⻬数就是成员⾃⾝的⼤⼩
3. 结构体总⼤⼩为最⼤对⻬数(结构体中每个成员变量都有⼀个对⻬数,所有对⻬数中最⼤的)的整数倍。
4. 如果嵌套了结构体的情况,嵌套的结构体成员对⻬到⾃⼰的成员中最⼤对⻬数的整数倍处,结构体的整体⼤⼩就是所有最⼤对⻬数(含嵌套结构体中成员的对⻬数)的整数倍。
重点知识:结构体变量起始位置偏移量的理解
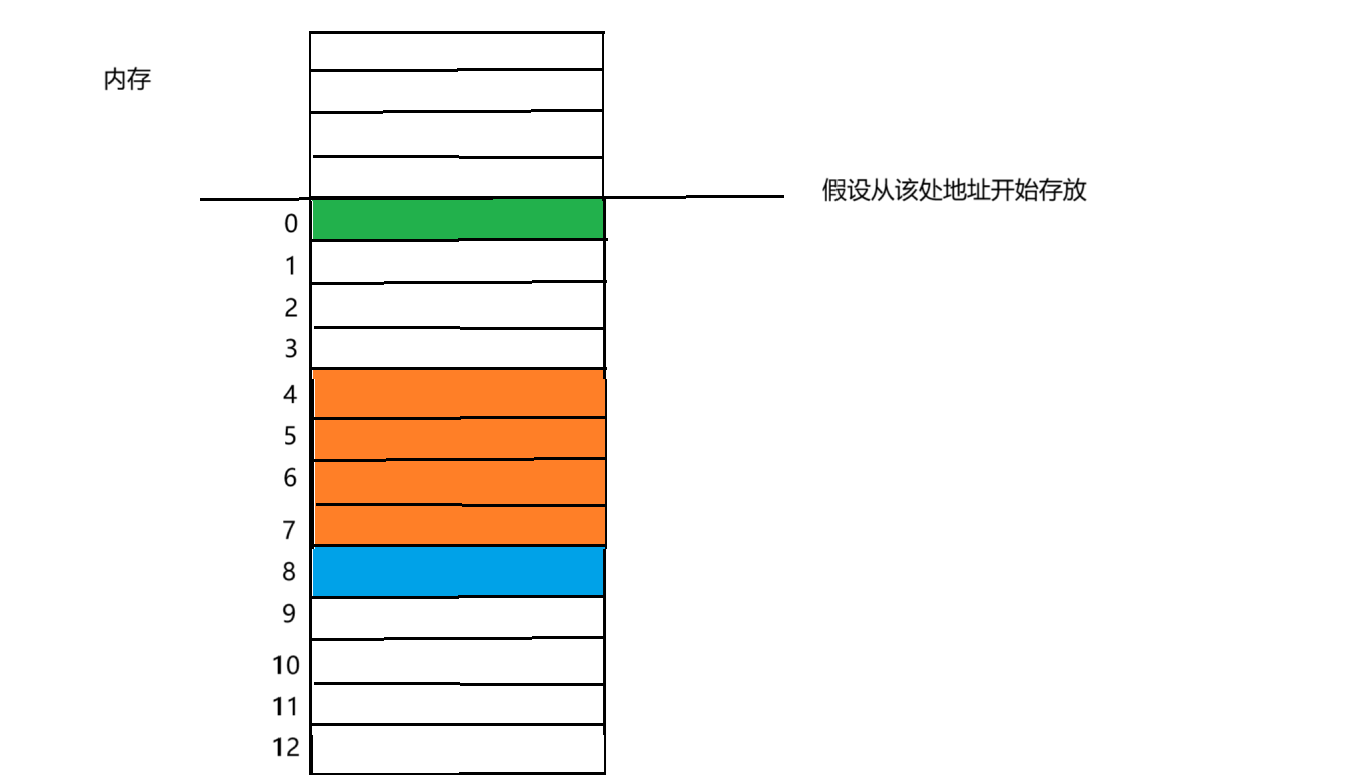
如下图所示,若开辟了一块内存,结构体变量从某个起始地址开始存放,距离该地址差值即为偏移量

通过了解上述规则我们可以练习一下试题:(温馨提示以下:代码在vs2022编译器下,编译的结果)
练习一
struct S1
{
char c1;//第一个成员 存放在偏移量为0的地址处
int i; // 本身大小为4 vs默认大小8 对齐数为4
char c2;// 本身大小为1 vs默认大小8 对齐数为1
};
int main()
{
printf("%d\n", sizeof(struct S1));
return 0;
}
解析:
①char c1 变量为第一个成员,对齐到起始位置偏移量为0的地址处
②int i 变量本身大小为4个字节 与 vs默认对齐数8 的最小值为4 所以对齐数为4 ,再根据规则存放到对齐数的整数倍偏移的 位置处。
③char c2 变量本身大小为1个字节 与 vs默认对齐数8 的最小值为1 所以对齐数为1,再根据规则存放到对齐数的整数倍偏的 位置处。
如下图分布所示:
所以大小为9个字节吗 ?根据打印结果来看,显然不是。
因为结构体的总大小为成员变量中对齐数的整数倍,成员变量中最大的对齐数为4,故而总大小为12个字节。
练习二:含结构体
struct S1
{
char c1;
int i;
char c2;
};
struct S2
{
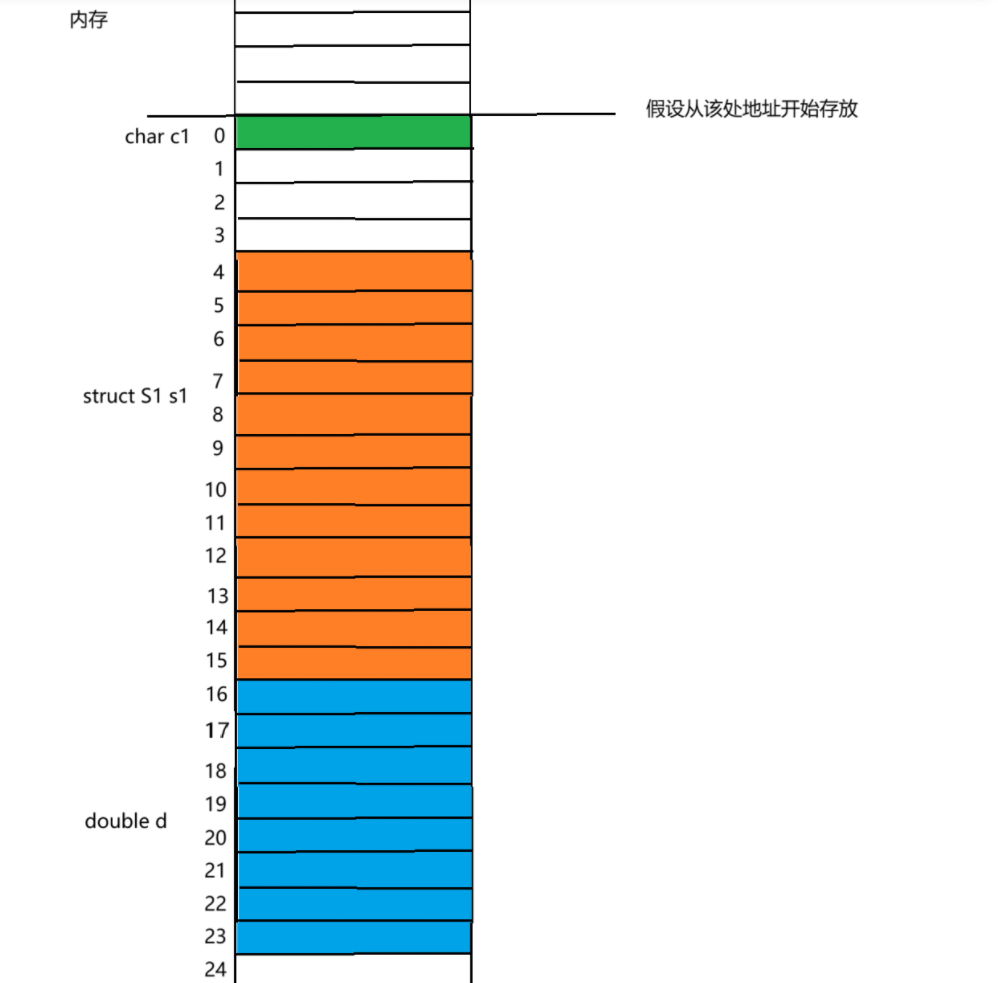
char c1; //对齐到偏移量为0的地址处
struct S1 s1; //结构体S1中成员最大的对齐数为4 vs默认8 对齐数为4
double d; // 本身大小为8 vs默认8 对齐数为8
};
int main()
{
printf("%d\n", sizeof(struct S2));
return 0;
}
如图所示分配内存:
最终结果为:为结构体的总大小为成员变量中对齐数的整数倍,成员变量中最大的对齐数为8,故而总大小为24个字节。

4.修改默认对齐数
在vs环境下。可以根据需要修改默认对齐数,以实现合适的内存对齐结构
#include <stdio.h>
#pragma pack(1)//设置默认对⻬数为1
struct S
{
char c1; //1 1 对齐数为1
int i; //4 1 对齐数为1
char c2; //1 1 对齐数为1
};
#pragma pack()//取消设置的对⻬数,还原为默认
int main()
{
//输出的结果是什么?
printf("%d\n", sizeof(struct S));
return 0;
}
此时该结构体的内存大小为6个字节。
5.为什么出现内存对齐
1. 平台原因 (移植原因):
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2. 性能原因:
数据结构(尤其是栈)应该尽可能地在⾃然边界上对⻬。原因在于,为了访问未对⻬的内存,处理器需要作两次内存访问;⽽对⻬的内存访问仅需要⼀次访问。假设⼀个处理器总是从内存中取8个字节,则地址必须是8的倍数。如果我们能保证将所有的double类型的数据的地址都对⻬成8的倍数,那么就可以⽤⼀个内存操作来读或者写值了。否则,我们可能需要执⾏两次内存访问,因为对象可能被分放在两个8字节内存块中。
总而言之:结构体的内存对⻬是拿空间来换取时间的做法
三、利用结构体实现位端
1.什么是位端
位段的声明和结构体是类似的,有两个不同:
①位段的成员必须是 int、unsigned int 或signed int ,在C99中位段成员的类型也可以选择其他类型。
②位段的成员名后边有⼀个冒号和⼀个数字,其中冒号后面跟着的数字表示,改位段所需开辟的bit位
比如:
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
2.位端的内存分配
对于位端的内存,有如下三点警示:
1. 位段的成员可以是 int、 unsigned int、 signed int 或者是 char 等类型
2. 位段的空间上是按照需要以4个字节( int )或者1个字节( char )的⽅式来开辟的。
3. 位段涉及很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使⽤位段。
事实上对于位端的内存开辟在不同的编译器上是有差异的,就拿vs2022这个环境下为例讲解一下
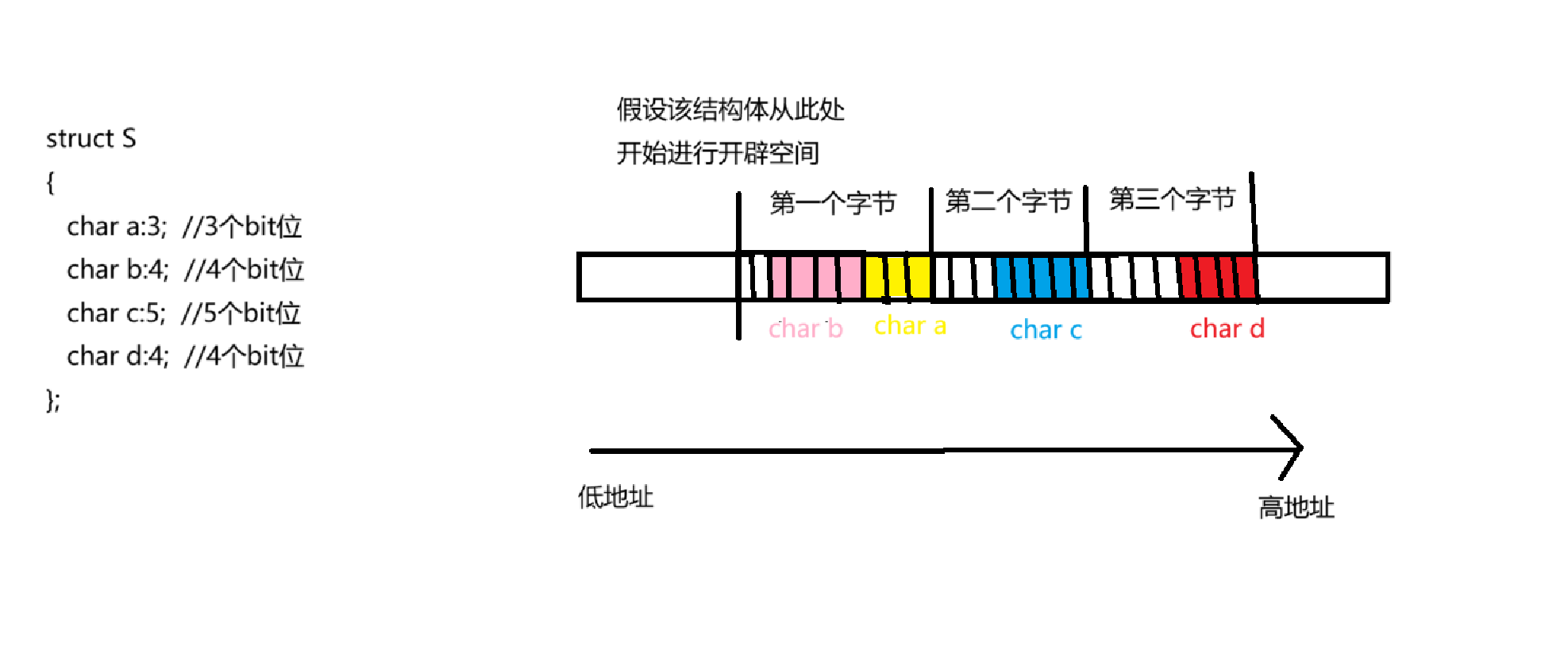
struct S
{
char a:3; //3个bit位
char b:4; //4个bit位
char c:5; //5个bit位
char d:4; //4个bit位
};
int main()
{
struct S s = {0};
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;
return 0;
}
针对于位段的内存开辟,在vs的环境下有如下规则:
①:按照4个字节(int 型变量) 或则 1个字节 (char 型变量)来开辟空间,然后从右向左填充bit位大小的空间。
②:若填充所需的bit位空间不足,则需要再另外开辟空间。
所以上述代码的空间开辟如下图所示:
总共需要3个字节大小。
根据上述赋值操作,如下图所示:
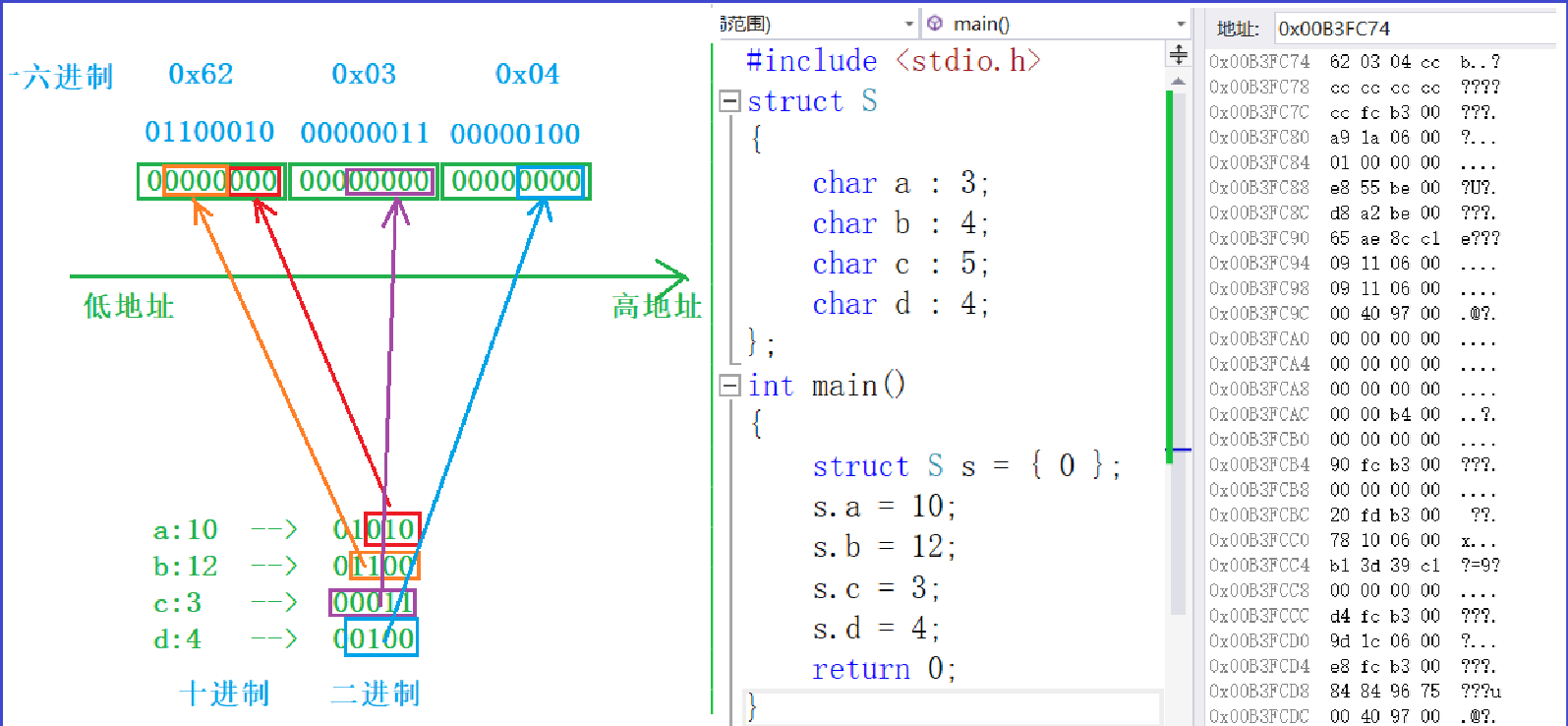
3.位段的跨平台问题
1. int 位段被当成有符号数还是⽆符号数是不确定的。
2. 位段中最⼤位的数⽬不能确定。(16位机器最⼤16,32位机器最⼤32,写成27,在16位机器会出问题。
3. 位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
4. 当⼀个结构包含两个位段,第⼆个位段成员⽐较⼤,⽆法容纳于第⼀个位段剩余的位时,是舍弃剩余的位还是利⽤,这是不确定的。
总结:
跟结构体相⽐,位段可以达到同样的效果,并且可以很好的节省空间,但是有跨平台的问题存在。
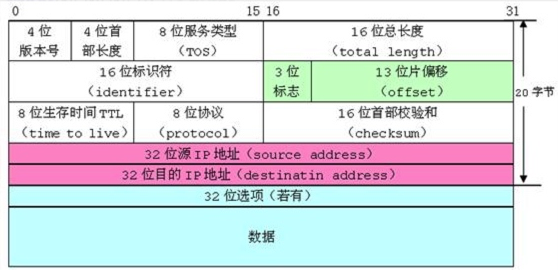
4.位段的应用
下图是⽹络协议中,IP数据报的格式,我们可以看到其中很多的属性只需要⼏个bit位就能描述,这⾥使⽤位段,能够实现想要的效果,也节省了空间,这样⽹络传输的数据报⼤⼩也会较⼩⼀些,对⽹络的畅通是有帮助的。
5.位段的注意事项
位段的⼏个成员共有同⼀个字节,这样有些成员的起始位置并不是某个字节的起始位置,那么这些位置处是没有地址的。内存中每个字节分配⼀个地址,⼀个字节内部的bit位是没有地址的。所以不能对位段的成员使⽤&操作符,这样就不能使⽤scanf直接给位段的成员输⼊值,只能是先输⼊放在⼀个变量中,然后赋值给位段的成员。
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};
int main()
{
struct A sa = {0};
//这是错误的
scanf("%d", &sa._b);
//正确的⽰范
int b = 0;
scanf("%d", &b);
sa._b = b;
return 0;
}
既然看到了这里了,不妨给个一键三连吧!


















 1772
1772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









