一、 环境准备
Acllite下载:
https://gitee.com/ascend/samples/tree/master/python/common
Yolov7源码:
https://github.com/WongKinYiu/yolov7
Yolov7模型:
https://github.com/WongKinYiu/yolov7/releases/download/v0.1/yolov7.pt
Torch & ONNX CPU版本
torch 1.12.1
torchaudio 0.12.1
torchvision 0.13.1
onnx 1.12.0
onnxconverter-common 1.12.2
onnxmltools 1.11.1
onnxruntime 1.12.1
二、 推理跑通
1、 把Acllite & Yolov7源码放在服务器同一个位置

2、 Pt文件转onnx文件
在yolov7-main目录下执行:
python3 export.py --weights yolov7.pt --grid --simplify --topk-all 100 --img-size 640 640 --max-wh 640

3、 模型转换
atc \
--model=./yolov7.onnx \
--framework=5 \
--output=./yolov7_bs1 \
--input_format=NCHW \
--input_shape="images:1,3,640,640" \
--soc_version=Ascend310P3 \
--log=info

4、 源码修改
只需要修改detect.py文件
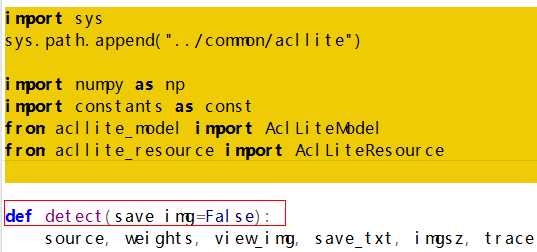
def detect(save_img=False):上增加
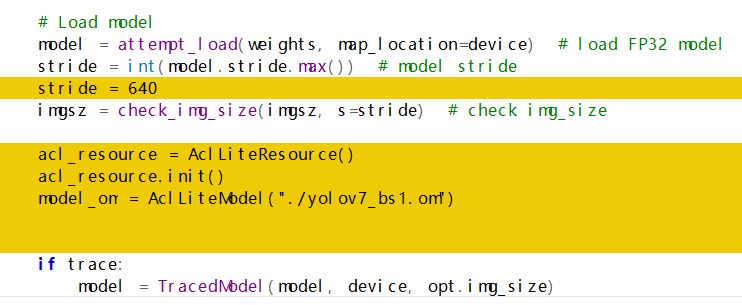
# Load model下增加

# Inference下增加
仅需增加以上黄色部分代码即可
5、 模型跑通
python3 detect.py --weights yolov7.pt --conf 0.25 --img-size 640 --device cpu --source inference/images/horses.jpg





 该博客主要介绍Yolov7模型推理的实现步骤。首先进行环境准备,提供Acllite、Yolov7源码及模型的下载链接,还提及Torch与ONNX的CPU版本。接着阐述推理跑通流程,包括将源码放于同一位置、Pt文件转onnx文件、模型转换、修改detect.py源码,最终实现模型跑通。
该博客主要介绍Yolov7模型推理的实现步骤。首先进行环境准备,提供Acllite、Yolov7源码及模型的下载链接,还提及Torch与ONNX的CPU版本。接着阐述推理跑通流程,包括将源码放于同一位置、Pt文件转onnx文件、模型转换、修改detect.py源码,最终实现模型跑通。


















 2350
2350

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









