 Kubernetes 1.18-1.24版Pod调度Pending问题解析
Kubernetes 1.18-1.24版Pod调度Pending问题解析





目录标题
Kubernetes Pod调度Pending问题深度解析:从1.18到1.24版本的资源计算与快速定位
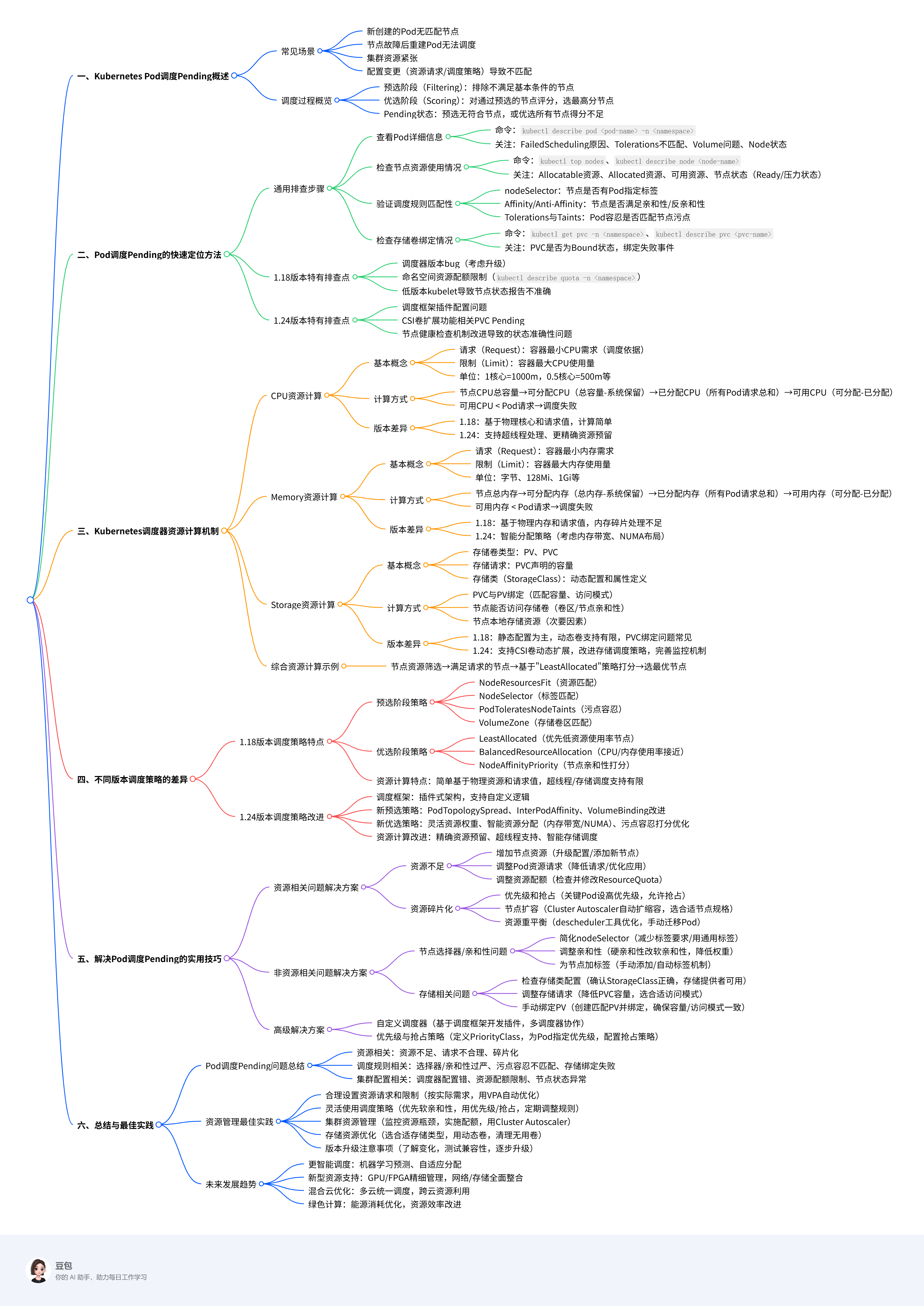
一、Kubernetes Pod调度Pending概述
在Kubernetes集群中,当Pod处于Pending状态时,意味着它已经被创建但尚未被调度到任何节点上运行。这通常是由于调度器无法找到满足Pod所有调度条件的节点。Pod调度是Kubernetes核心功能之一,了解调度Pending的原因及资源计算方式对于高效运维集群至关重要。
1.1 Pod调度Pending的常见场景
Pod调度Pending可能出现在以下场景:
- 新创建的Pod:当您首次创建Pod时,如果没有满足条件的节点,Pod将保持Pending状态。
- 节点故障后重建:当节点发生故障,其上的Pod被驱逐后,重新创建的Pod可能无法找到合适的替代节点。
- 资源紧张时:当集群资源使用率高,新的Pod可能因资源不足而无法调度。
- 配置变更后:当Pod的资源请求或调度策略(如nodeSelector、affinity)发生变更,可能导致无法找到匹配的节点。
1.2 调度过程概览
Kubernetes调度器(kube-scheduler)负责将Pod分配到合适的节点上,这个过程主要分为两个阶段:
- 预选阶段(Filtering):排除不满足基本条件的节点,如资源不足、节点选择器不匹配等。
- 优选阶段(Scoring):对通过预选的节点进行评分,选择得分最高的节点。
当Pod处于Pending状态时,意味着在预选阶段没有找到符合条件的节点,或者在优选阶段所有节点的得分都不足以被选中。
二、Pod调度Pending的快速定位方法
2.1 通用排查步骤
无论Kubernetes版本如何,以下步骤都能帮助您快速定位Pod调度Pending的原因:
2.1.1 查看Pod详细信息
使用kubectl describe pod <pod-name>命令查看Pod的详细信息,特别是Events部分,这是定位问题的关键。
kubectl describe pod my-pending-pod -n my-namespace
在输出中,关注以下关键信息:
- FailedScheduling原因:直接显示调度失败的原因,如资源不足、节点选择器不匹配等。
- Tolerations不匹配:如果存在节点污点(Taint)而Pod没有相应的容忍(Toleration)。
- Volume问题:如存储卷无法绑定或找不到可用的卷区。
- Node状态:节点是否Ready,是否有其他条件问题。
2.1.2 检查节点资源使用情况
通过以下命令检查节点的资源使用情况:
kubectl top nodes
kubectl describe node <node-name>
关注以下指标:
- Allocatable资源:节点声明的可分配资源总量。
- Allocated资源:节点上已分配的资源总和(已调度Pod的Requests总和)。
- 可用资源:Allocatable减去Allocated即为可用资源,如果可用资源小于Pod的Requests,调度将失败。
- 节点状态:节点是否处于Ready状态,是否有MemoryPressure、DiskPressure等问题。
2.1.3 验证调度规则匹配性
检查Pod的调度规则是否与节点属性匹配:
- nodeSelector匹配性:检查节点是否具有Pod指定的标签。
- Affinity/Anti-Affinity:检查节点是否满足Pod的亲和性/反亲和性要求。
- Tolerations与Taints匹配:检查Pod的容忍是否匹配节点的污点。
2.1.4 检查存储卷绑定情况
如果Pod使用了持久卷声明(PVC),检查PVC是否已成功绑定:
kubectl get pvc -n my-namespace
kubectl describe pvc <pvc-name> -n my-namespace
关注PVC的状态是否为Bound,以及是否有相关的事件显示绑定失败。
2.2 Kubernetes 1.18版本特有排查点
在Kubernetes 1.18版本中,有一些特有的因素需要考虑:
2.2.1 调度器版本问题
1.18版本的调度器可能存在一些已知的bug,导致Pod调度失败。可以考虑升级调度器版本来解决问题。
2.2.2 资源配额限制
检查命名空间的资源配额是否限制了Pod的创建:
kubectl describe quota -n my-namespace
2.2.3 低版本kubelet问题
在1.18版本中,如果kubelet版本较低,可能导致节点状态报告不准确,影响调度决策。
2.3 Kubernetes 1.24版本特有排查点
Kubernetes 1.24版本引入了一些新特性和变化,排查时需注意:
2.3.1 调度框架改进
1.24版本使用了更灵活的调度框架,可能存在插件配置问题。检查调度器配置文件是否正确。
2.3.2 存储卷扩展支持
1.24版本默认启用了CSI卷扩展功能,如果PVC处于Pending状态,可能与此特性相关。
2.3.3 节点健康检查改进
1.24版本改进了节点健康检查机制,检查节点状态是否准确反映实际情况。
三、Kubernetes调度器资源计算机制
3.1 CPU资源计算
在Kubernetes中,CPU资源的计算方式在不同版本中基本保持一致,但在资源分配和调度策略上有一些细微变化。
3.1.1 CPU请求与限制的基本概念
- CPU请求(Request):容器运行所需的最小CPU资源,调度器根据请求值选择节点。
- CPU限制(Limit):容器可以使用的最大CPU资源。
- CPU单位:1个CPU代表1个核心,0.5或500m表示半个核心,100m表示0.1个核心。
3.1.2 CPU资源计算方式
在调度阶段,调度器计算节点是否能满足Pod的CPU请求:
- 节点CPU总容量:节点的物理CPU核心数。
- 节点可分配CPU:总容量减去系统保留的资源(用于kubelet、容器运行时等)。
- 已分配CPU:节点上所有Pod的CPU请求总和。
- 可用CPU:可分配CPU减去已分配CPU。
如果Pod的CPU请求超过节点的可用CPU,调度将失败。
3.1.3 1.18与1.24版本的差异
- 1.18版本:CPU资源计算相对简单,主要基于节点的物理核心数和Pod的请求值。
- 1.24版本:引入了更精细的CPU资源管理,如支持超线程处理和更精确的资源预留。
3.2 Memory资源计算
内存资源的计算方式与CPU类似,但在处理上有一些差异。
3.2.1 Memory请求与限制的基本概念
- Memory请求(Request):容器运行所需的最小内存量。
- Memory限制(Limit):容器可以使用的最大内存量。
- Memory单位:可以使用字节(byte)或带单位的符号,如128Mi、1Gi等。
3.2.2 Memory资源计算方式
调度器计算内存资源的方式如下:
- 节点总内存:节点的物理内存总量。
- 节点可分配内存:总内存减去系统保留的内存(用于内核、系统服务等)。
- 已分配内存:节点上所有Pod的内存请求总和。
- 可用内存:可分配内存减去已分配内存。
如果Pod的内存请求超过节点的可用内存,调度将失败。
3.2.3 1.18与1.24版本的差异
- 1.18版本:内存资源计算基于物理内存和请求值,对内存碎片的处理不够优化。
- 1.24版本:引入了更智能的内存分配策略,如考虑内存带宽和NUMA节点布局。
3.3 Storage资源计算
存储资源的处理在Kubernetes中相对复杂,尤其是在不同版本之间有较大变化。
3.3.1 Storage请求的基本概念
- 存储卷类型:Kubernetes支持多种存储卷类型,包括持久卷(PV)和持久卷声明(PVC)。
- 存储请求:PVC声明所需的存储容量。
- 存储类(StorageClass):定义存储的动态配置和属性。
3.3.2 Storage资源计算方式
存储资源的计算涉及以下几个步骤:
- PVC绑定:PVC需要与匹配的PV绑定,PV必须满足PVC的容量和访问模式要求。
- 存储卷可用性:调度器需要确保节点能够访问存储卷,这可能涉及卷区(zone)或节点亲和性要求。
- 节点存储资源:节点的本地存储资源(如emptyDir、hostPath)也需要考虑,但通常不是主要因素。
3.3.3 1.18与1.24版本的差异
-
1.18版本:
- 存储卷的调度主要基于静态配置,动态卷供应支持有限。
- PVC绑定问题是导致Pod调度Pending的常见原因。
-
1.24版本:
- 支持CSI卷动态扩展,PVC可以自动调整大小。
- 改进了存储卷的调度策略,更智能地处理卷区和节点亲和性。
- 引入了更完善的存储资源监控和报告机制。
3.4 综合资源计算示例
下面通过一个示例说明调度器如何综合计算CPU、Memory和Storage资源:
假设集群中有三个节点,资源情况如下:
| 节点 | CPU(核心) | 内存 | 可用存储 |
|---|---|---|---|
| Node1 | 4 | 8GB | 50GB |
| Node2 | 8 | 16GB | 100GB |
| Node3 | 2 | 4GB | 30GB |
现有一个Pod,其资源请求为:
resources:
requests:
cpu: "1"
memory: "2Gi"
storage: "20GB"
调度器的计算过程如下:
-
计算每个节点的可用资源:
- Node1: CPU 3 (4-1), 内存 6GB (8-2), 存储 30GB (50-20)
- Node2: CPU 7 (8-1), 内存 14GB (16-2), 存储 80GB (100-20)
- Node3: CPU 1 (2-1), 内存 2GB (4-2), 存储 10GB (30-20)
-
筛选满足资源请求的节点:
- Node1: CPU 3 >=1, 内存6GB >=2GB, 存储30GB >=20GB → 满足
- Node2: 同样满足
- Node3: 存储10GB <20GB → 不满足
-
对满足条件的节点进行打分:
- 通常使用"LeastAllocated"策略,优先选择资源使用率最低的节点。
- 计算各节点的资源使用率:
- Node1: CPU 25% (1/4), 内存25% (2/8), 存储40% (20/50)
- Node2: CPU 12.5% (1/8), 内存12.5% (2/16), 存储20% (20/100)
- Node3被排除
-
选择得分最高的节点:
- Node2的资源使用率最低,因此被选中。
四、不同版本调度策略的差异
4.1 Kubernetes 1.18调度策略特点
Kubernetes 1.18版本的调度策略相对基础,但已经具备了核心功能:
4.1.1 预选阶段策略
1.18版本的预选阶段使用以下主要策略:
- NodeResourcesFit:检查节点资源是否满足Pod请求。
- NodeSelector:检查节点标签是否匹配Pod的nodeSelector。
- PodToleratesNodeTaints:检查Pod是否容忍节点的污点。
- VolumeZone:检查存储卷的可用区是否匹配。
4.1.2 优选阶段策略
1.18版本的优选阶段使用以下主要策略:
- LeastAllocated:优先选择资源使用率最低的节点。
- BalancedResourceAllocation:节点上CPU和Memory使用率越接近,权重越高。
- NodeAffinityPriority:根据节点亲和性配置打分。
4.1.3 资源计算特点
- 资源计算相对简单:主要基于节点的物理资源和Pod的请求值。
- 对超线程处理有限:不区分物理核心和逻辑核心。
- 存储调度不够智能:对存储卷的调度策略较为基础。
4.2 Kubernetes 1.24调度策略改进
Kubernetes 1.24版本引入了多项调度策略改进:
4.2.1 调度框架改进
1.24版本使用了更灵活的调度框架,支持插件式架构,允许自定义调度逻辑。
4.2.2 新的预选策略
1.24版本引入了一些新的预选策略:
- PodTopologySpread:更智能的Pod拓扑分布控制。
- InterPodAffinity:基于其他Pod的位置进行调度。
- VolumeBinding:改进了存储卷的绑定逻辑。
4.2.3 新的优选策略
1.24版本引入了更精细的优选策略:
- 更灵活的资源权重配置:可以自定义CPU、Memory和Storage的权重。
- 更智能的资源分配:考虑内存带宽、NUMA节点布局等因素。
- 改进的污点容忍打分:更灵活地处理节点污点和Pod容忍。
4.2.4 资源计算改进
- 更精确的资源预留:考虑系统服务和守护进程的资源需求。
- 支持超线程处理:可以区分物理核心和逻辑核心。
- 更智能的存储调度:支持CSI卷动态扩展和更智能的卷区分配。
五、解决Pod调度Pending的实用技巧
5.1 资源相关问题解决方案
5.1.1 资源不足问题
当Pod因资源不足而无法调度时,可以采取以下措施:
-
增加节点资源:
- 升级现有节点的配置(CPU、内存)。
- 向集群添加新节点。
-
调整Pod资源请求:
- 降低Pod的CPU或Memory请求。
- 优化应用程序,减少资源消耗。
-
资源配额调整:
- 检查命名空间的资源配额是否限制了Pod的创建。
- 调整ResourceQuota配置以允许更多资源使用。
5.1.2 资源碎片化问题
当集群存在资源碎片化时,可以采取以下措施:
-
使用优先级和抢占:
- 为关键Pod设置高优先级。
- 允许高优先级Pod抢占低优先级Pod的资源。
-
节点扩容策略:
- 配置集群自动扩展器(Cluster Autoscaler)自动添加节点。
- 选择合适的节点规格,避免资源碎片化。
-
资源重平衡:
- 使用descheduler工具定期优化Pod分布。
- 手动迁移Pod以平衡资源分布。
5.2 非资源相关问题解决方案
5.2.1 节点选择器/亲和性问题
当Pod因节点选择器或亲和性配置而无法调度时:
-
简化nodeSelector:
- 减少不必要的标签要求。
- 使用更通用的标签。
-
调整亲和性策略:
- 将硬亲和性(requiredDuringScheduling)改为软亲和性(preferredDuringScheduling)。
- 降低亲和性权重,增加灵活性。
-
为节点添加标签:
- 为现有节点添加所需的标签。
- 配置节点自动标签机制。
5.2.2 存储相关问题
当Pod因存储问题而无法调度时:
-
检查存储类配置:
- 确保StorageClass配置正确。
- 检查存储提供者是否可用。
-
调整存储请求:
- 降低PVC的容量请求。
- 选择更合适的访问模式(ReadWriteOnce、ReadOnlyMany等)。
-
手动绑定PV:
- 创建符合条件的PV并手动绑定到PVC。
- 确保PV和PVC的容量和访问模式匹配。
5.3 高级解决方案
5.3.1 自定义调度器 暂不考虑
对于复杂的调度需求,可以考虑创建自定义调度器:
-
使用调度框架:
- 基于Kubernetes调度框架开发自定义插件。
- 实现特定于业务需求的调度逻辑。
-
多调度器协作:
- 运行多个调度器处理不同类型的Pod。
- 为不同类型的Pod指定不同的调度器。
5.3.2 优先级与抢占策略 暂不考虑
配置Pod优先级和抢占策略,确保关键应用能够优先调度:
-
定义优先级类:
apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: high-priority value: 1000000 globalDefault: false description: "High priority for critical applications" -
为Pod指定优先级:
apiVersion: v1 kind: Pod metadata: name: critical-app spec: priorityClassName: high-priority # ... 其他配置 ... -
配置抢占策略:
- 设置合适的抢占策略,确保高优先级Pod能够抢占低优先级Pod的资源。
- 配置Pod中断预算(PodDisruptionBudget)保护关键应用。
六、总结与最佳实践
6.1 Pod调度Pending问题总结
通过本文的详细分析,我们可以总结出Pod调度Pending的主要原因和解决方案:
-
资源相关原因:
- CPU、Memory或Storage资源不足。
- 资源请求设置不合理。
- 资源碎片化导致无法找到连续的资源块。
-
调度规则相关原因:
- nodeSelector或affinity配置过于严格。
- 节点污点与Pod容忍不匹配。
- 存储卷绑定失败或存储策略配置错误。
-
集群配置相关原因:
- 调度器配置错误。
- 资源配额限制了Pod的创建。
- 节点状态异常或健康检查失败。
6.2 Kubernetes资源管理最佳实践
基于对Kubernetes调度和资源计算机制的理解,以下是一些最佳实践:
-
合理设置资源请求和限制:
- 根据应用实际需求设置CPU和Memory的requests和limits。
- 避免设置过高或过低的资源值。
- 使用Vertical Pod Autoscaler(VPA)自动优化资源配置。
-
灵活使用调度策略:
- 优先使用软亲和性(preferredDuringScheduling)而非硬亲和性(requiredDuringScheduling)。
- 使用优先级和抢占机制保障关键应用。
- 定期评估和调整节点标签和Pod调度规则。
-
集群资源管理:
- 监控节点资源使用情况,及时发现资源瓶颈。
- 实施资源配额管理,防止资源滥用。
- 使用集群自动扩展器(Cluster Autoscaler)实现资源弹性管理。
-
存储资源优化:
- 根据应用需求选择合适的存储类型和大小。
- 利用动态卷供应减少存储管理复杂度。
- 定期清理不再使用的存储卷。
-
版本升级注意事项:
- 在升级到新版本前,了解调度策略和资源计算的变化。
- 测试新版本的调度行为,确保与现有应用兼容。
- 逐步升级集群,避免大规模版本跳跃。
通过遵循这些最佳实践,您可以有效减少Pod调度Pending问题,提高Kubernetes集群的稳定性和资源利用率。
6.3 未来发展趋势
随着Kubernetes的不断发展,调度和资源管理机制也在持续演进:
-
更智能的调度算法:
- 基于机器学习的调度预测。
- 自适应资源分配策略。
-
新型资源类型支持:
- GPU、FPGA等专用硬件资源的更精细管理。
- 网络和存储资源的更全面整合。
-
混合云环境优化:
- 多云环境下的统一调度策略。
- 跨云资源的高效利用。
-
绿色计算实践:
- 基于能源消耗的调度优化。
- 资源使用效率的持续改进。
总之,Kubernetes的调度和资源管理机制正在朝着更智能、更灵活、更高效的方向发展,为云原生应用提供更强大的支持。

















 2958
2958

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









