






基于RapidIO接口的DSP+GPU工业AI实时计算解决方案是一种面向高性能、低延迟工业应用的异构计算架构,适用于工业自动化、机器视觉、预测性维护、机器人控制等场景。以下是该方案的核心设计思路和技术要点:
1. 方案背景与目标
工业需求:
工业场景对实时性(毫秒级/微秒级响应)、高吞吐量和可靠性要求严苛,需处理多源异构数据(传感器信号、图像、振动等)。
技术痛点:
传统CPU难以满足并行计算需求,单独依赖GPU存在数据预处理瓶颈,FPGA开发复杂度高。
方案目标:
结合DSP的实时信号处理能力与GPU的高吞吐量并行计算能力。
通过RapidIO实现低延迟、高带宽的芯片间通信。
支持工业AI模型(如目标检测、时序预测、异常检测)的实时推理与闭环控制。
2. 硬件架构设计
核心组件
DSP芯片(HC3080 DSP):
负责前端数据预处理(滤波、特征提取、降噪)。
低功耗、高能效的定点/浮点运算。
HC3080-SRIO-PCIE3X16板卡是一款以高性能HC3080 DSP为核心的双路SRIO PCIe3.0x16数据采集与处理板卡。
| 类别 | 参数 |
| 主控芯片 | HC3080 DSP,8×向量核 + 4×RASP核 + 4×AI核,主频1.25GHz,集成8MB SRAM。 |
| 内存 | 双通道DDR4-3200 ,每组4GByte,64bit宽度 |
| 存储 | 32MB NOR Flash ,固件程序存储 |
| PCIe接口 | PCIe3.0 x16, 或者PXIe接口 |
| SRIO接口 | 双路4x SRIO 3.0 |
| 自研编译器 | 支持C/C++编程,便于用户进行自定义算法开发。 |
| 驱动与API | 提供Linux/WinDriver驱动包及SRIO/PCIE/DDR4控制接口封装,简化开发流程。 |
| 工作温度 | -40℃ ~ +85℃ |
GPU芯片(如NVIDIA Jetson AGX Orin):
执行深度学习模型推理(如ResNet、LSTM、Transformer轻量化模型)。
利用CUDA/cuDNN加速矩阵运算。
| GPU | 搭载 Tensor Core 的 512 核 Volta GPU |
| CPU | 8 核 ARM v8.2 64 位 CPU、8 MB L2 + 4 MB L3 |
| 内存 | 32 GB 256 位 LPDDR4x | 137 GB/秒 |
| 存储 | 32 GB eMMC 5.1 |
| M.2 Key M | 1路 NVMe PCIeX4 |
DSP 与FPGA通过 PCIe3.0X8互联
RapidIO互联:
芯片间采用RapidIO 4x/8x接口(带宽达16/32 Gbps),替代PCIe,降低传输延迟(微秒级)。
支持多主设备互联(如多DSP+多GPU协同),扩展计算资源。
工业级FPGA(可选):
作为协处理器,用于协议转换(如Camera Link→RapidIO)或硬件级逻辑加速。
典型拓扑
[工业传感器/摄像头]
↓ 数据采集
[前端预处理DSP集群] --RapidIO--> [GPU计算集群]
↓ 预处理结果
[实时控制模块] ←---反馈调节
3. 软件栈算法分层优化:
3.1 DSP层:
使用DSP专用库(如TI C66x DSPLIB)优化信号处理算法(FFT、FIR滤波)。
支持FFT/IFFT、FIR、相关、向量运算、矩阵运算、排序、通道拆分和基本数学运算等9大类共32种信号处理算法硬件加速
| 序号 | 算法种类 | 算子类型 | 说明 |
| 1 | FFT/IFFT | FFT、IFFT | 点数:8-1M |
| 2 | FIR | 复数FIR、实数FIR、 多普勒复数FIR、多 普勒实数FIR | 点数:8-128K 阶数:8-128 |
| 3 | 相关 | 互相关、自相关 | 点数16~64K |
| 4 | 向量运算 | 向量加/减法、向量 点乘、向量共轭 | 点数:1-1M |
| 5 | 向量乘法 | 点数:1-1M、支持复向量、实向量 | |
| 6 | 向量求和/均值/模均 值 | 点数:8-1M、支持复向量、实向量 | |
| 7 | 矩阵运算 | 矩阵协方差 | 最大支持到256x8K |
| 8 | 矩阵求逆 | 支持LU分解、cholesky分解 | |
| 9 | 矩阵乘法 | 矩阵A行数:1-2K,矩阵A列数/B行数:1-8K, | |
| 10 | 广义内积 | 矩阵A:MxN,矩阵B:MxM | |
| 11 | 加权 | 矩阵A:1xM,矩阵B:MxN | |
| 12 | 排序 | 寻最值 | 点数8-32K,支持寻最大/最小值 |
| 13 | 全排序 | 点数8-32K,支持升序/降序全排序 | |
| 14 | 筛选 | 点数8-32K | |
| 15 | 基本数学 运算 | 除法 | 点数8-1M |
| 16 | 求模 | 点数8-1M | |
| 17 | 定浮转换 | 点数8-1M | |
| 18 | EXP(jφ) | 点数8-1M 输入弧度 | |
| 19 | Sin/Cos | 点数8-1M输入弧度、Sin/Cos可选 | |
| 20 | 复倒数 | 点数8-1M | |
| 21 | SQRT、1/SQRT | 点数8-1M | |
| 22 | 通道拆分 | 通道拆分 | 距离采样点数:8-1M 通道数:4-128(偶数) |
3.2 GPU层:
采用TensorRT、cuDNN等框架优化AI模型,利用流处理器(SM)并行化计算。基于CUDA 深度学习框架支持如下软件功能
(1) TensorFlow / PyTorch
功能:通用深度学习框架,支持GPU加速的模型训练与推理。
工业应用:
预测性维护:LSTM/Transformer模型分析振动/温度时序数据。
缺陷检测:CNN模型(如ResNet、EfficientNet)检测产品表面缺陷。
机器人控制:强化学习(RL)模型实现复杂动作规划。
优势:生态完善,支持分布式训练和模型导出(如TensorFlow Serving)。
(2) Keras
特点:高层API封装,适合快速原型开发。
工业场景:轻量化模型部署(如TensorFlow Lite GPU Delegate)。
(3) 计算机视觉库- NVIDIA DALI
功能:基于CUDA的高性能数据加载与预处理库。
工业应用:
图像增强(旋转、裁剪、归一化)加速。
支持多模态数据(图像+传感器数据)流水线。
优势:减少CPU-GPU数据传输瓶颈,吞吐量提升3-10倍。
(4) 计算机视觉库-OpenCV CUDA模块
功能:OpenCV的GPU加速版本,支持传统计算机视觉算法。
工业应用:
实时图像滤波(高斯滤波、直方图均衡化)。
特征提取(HOG、SIFT)与目标跟踪(CAMShift)。
局限性:深度学习能力弱于专用框架。
(5) Halcon
特点:工业视觉专用库,支持CUDA加速。
工业场景:
机器视觉定位(模板匹配、几何测量)。
光学字符识别(OCR)与缺陷检测。
(6) 工业AI专用库TensorRT
功能:NVIDIA的高性能推理优化器,支持模型量化(INT8/FP16)。
工业应用:
部署轻量化模型(如YOLOv5-Tiny、MobileNet)。
实时推理吞吐量可达数百FPS。
优势:低延迟、高能效,适合边缘计算。
(7) 工业AI专用库-NVIDIA RAPIDS
功能:GPU加速的数据科学库(cuDF、cuML、cuGraph)。
工业应用:
时序数据分析(cuTimeSeries)。
工业大数据聚类(cuML K-Means)与回归预测。
(8) 工业AI专用库-Intel oneAPI(兼容CUDA)
功能:跨架构的工业级AI工具包(支持CUDA和oneDNN)。
工业场景:生产质量检测(ONNX模型优化)。
4. 模型优化与部署工具
(1) ONNX Runtime
功能:跨框架模型部署,支持CUDA加速推理。
工业应用:统一部署不同框架(如PyTorch→ONNX→TensorRT)。
(2) OpenVINO
特点:英特尔推理引擎,部分模型可通过CUDA兼容。
工业场景:工业视觉模型(如检测、分类)部署。
5. 工业场景案例
场景 常用算法 GPU库/工具
缺陷检测 CNN、YOLO、U-Net TensorFlow, PyTorch, TensorRT
预测性维护 LSTM、Transformer PyTorch, RAPIDS
机器人视觉引导 ORB-SLAM、PointNet OpenCV CUDA, PyTorch3D
生产质量控制 Faster R-CNN、SSD Detectron2, OpenVINO
6. 选择建议
需求匹配:
若需快速开发,优先选择PyTorch/TensorFlow + TensorRT。
若需传统视觉算法加速,选择OpenCV CUDA或Halcon。
性能优化:
使用DALI优化数据加载,TensorRT优化推理。
生态兼容性:
工业协议兼容性(如OPC UA)需结合具体硬件平台(如NVIDIA Jetson、DGX)。
7. 注意事项
模型轻量化:工业实时场景需平衡精度与速度(如知识蒸馏、通道剪枝)。
硬件限制:部分老旧GPU(如Fermi架构)不支持最新CUDA特性。
多模态数据:时序+图像融合任务需自定义CUDA内核(如CUDA C++编程)。
通过上述库的组合,可构建高性能的工业AI解决方案,满足从边缘计算到云端的全栈需求。
3.3 RapidIO驱动与中间件:
开发定制化的RapidIO通信协议栈,支持零拷贝(Zero-copy)数据传输。
设计任务调度器,动态分配DSP和GPU任务负载(如通过OpenMP或MPI)。
实时操作系统(RTOS):
在DSP端部署RTOS(如TI RTOS、FreeRTOS),保证关键任务确定性执行。
GPU端结合Linux实时补丁(如PREEMPT-RT)降低调度抖动。
4. 关键技术突破
低延迟传输:
RapidIO的Packet Switching机制减少总线争用,结合DMA实现硬件级数据搬运。
数据流水线设计:DSP预处理与GPU推理重叠执行(Pipeline)。
异构协同计算:
任务分割策略:
将数据预处理(DSP)与模型计算(GPU)解耦,通过RapidIO DMA实现零拷贝传输。
动态负载均衡:
根据DSP和GPU的实时负载调整任务分配(如基于优先级的调度算法)。
工业场景适配:
模型轻量化:通过知识蒸馏、量化(INT8/FP16)压缩AI模型,适配GPU算力。
硬件容错:设计双机热备和RapidIO链路冗余,保障99.999%可用性。
5. 典型应用案例
缺陷检测:
DSP预处理(图像去噪、ROI提取)→ GPU运行YOLOv7-Tiny模型 → 输出缺陷坐标。
端到端延迟:<5ms(含数据传输)。
机器人运动控制:
DSP实时处理关节编码器信号 → GPU计算逆运动学模型 → 生成控制指令。
预测性维护:
DSP分析振动信号频谱 → GPU运行LSTM模型预测设备剩余寿命。
6. 性能评估指标
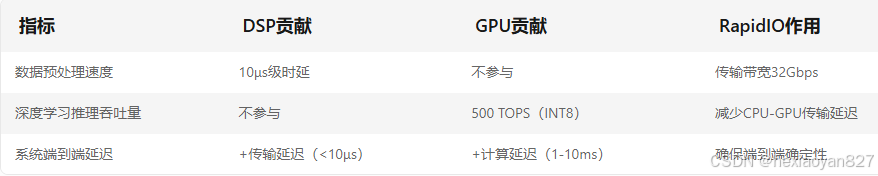
7. 方案优势
低延迟:RapidIO的硬件直连特性比传统PCIe更适用于实时场景。
高能效比:DSP和GPU分工协作,整体功耗低于纯GPU方案。
扩展性:支持多DSP+多GPU集群,适应更大规模数据处理需求。
8. 挑战与改进方向
生态兼容性:需开发RapidIO与CUDA生态的桥接工具链。
调试复杂度:异构系统需要不同的开发平台进行软件,算法分割和代码工具带来挑战。
成本优化:DSP+GPU构建固定成本的实时计算服务器, FPGA+AD或者图像进行灵活设计为SRIO适配器或者控制板。
该方案已在工业机器人、智能电网等领域落地,未来可结合边缘计算与5G进一步扩展应用范围。在电力智能变电站,核工业发电厂,高能物理粒子加速中心,汽车自动化工厂,半导体产线,船舶自动驾驶,盾构机大卡车,都有很大机会。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









