




Deep Research一种使用推理来综合大量在线信息并为您完成多步骤研究任务的代理。
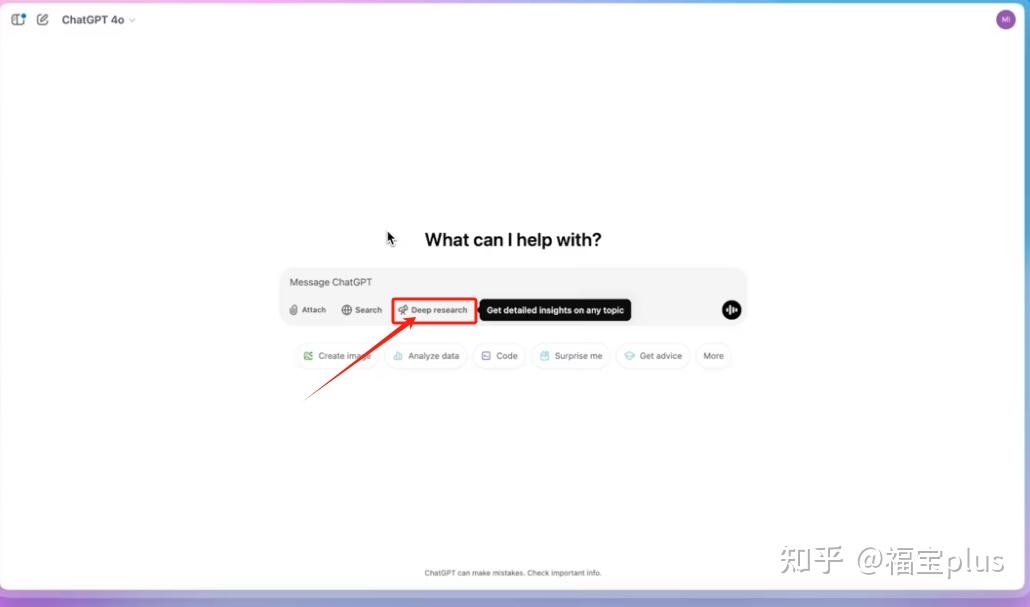
Deep Research怎么使用
目前可供 Pro 用户使用,接下来可供 Plus 和 Team 用户使用。
PS: 大家需要使用Sora或者订阅ChatGPT Pro或者升级Plus的用户可以参考本教程:(最新)国内如何订阅升级购买ChatGPT Pro Plus会员教程
今天,openAI 在 ChatGPT 中发布了深度研究,这是一项新的代理功能,可以在互联网上针对复杂任务进行多步骤研究。它只需数十分钟就能完成人类需要数小时才能完成的工作。 深度研究是 OpenAI 的下一个代理,它可以独立为您工作 - 您给它一个提示,ChatGPT 就会查找、分析和综合数百个在线资源,以研究分析师的水平创建一份综合报告。它由即将推出的 OpenAI o3 模型版本提供支持,该模型针对网页浏览和数据分析进行了优化,它利用推理来搜索、解释和分析互联网上的大量文本、图像和 PDF,并根据遇到的信息做出必要的调整。 综合知识的能力是创造新知识的先决条件。因此,深入研究标志着我们朝着开发通用人工智能的更广泛目标迈出了重要一步,我们长期以来一直设想通用人工智能能够产生新颖的科学研究成果。
什么场景会用到深入研究
深度研究是为从事金融、科学、政策和工程等领域密集知识工作并需要全面、精确和可靠研究的人员而打造的。它对于寻找高度个性化推荐的挑剔购物者同样有用,这些推荐通常需要仔细研究才能购买,例如汽车、家电和家具。每个输出都经过完整记录,并附有清晰的引文和思路摘要,便于参考和验证信息。它在查找需要浏览多个网站的小众、非直观信息方面特别有效。深度研究让您只需一个查询即可减轻和加快复杂、耗时的网络研究,从而节省宝贵的时间。 深度研究独立发现、推理并整合来自网络的见解。为了实现这一点,它接受了需要使用浏览器和 Python 工具的实际任务的训练,使用了与我们的第一个推理模型 OpenAI o1 相同的强化学习方法。虽然 o1 在编码、数学和其他技术领域表现出色,但许多现实世界的挑战需要从各种在线来源收集广泛的背景和信息。深度研究以这些推理能力为基础来弥补这一差距,使其能够解决人们在工作和日常生活中面临的各种问题。
如何使用深度研究
在 ChatGPT 中,选择消息编辑器中的“深入研究”并输入您的查询。告诉 ChatGPT 您需要什么——无论是流媒体平台的竞争分析还是最佳通勤自行车的个性化报告。您可以附加文件或电子表格以添加问题的背景信息。一旦开始运行,就会出现一个侧边栏,其中包含已采取的步骤和使用的来源的摘要。 深入研究可能需要 5 到 30 分钟才能完成,这需要花费大量时间深入研究网络。在此期间,您可以离开或处理其他任务 - 研究完成后您会收到通知。最终结果将以报告的形式在聊天中显示 - 在接下来的几周内,我们还将在这些报告中添加嵌入式图像、数据可视化和其他分析输出,以提供更多清晰度和背景信息。 与深度研究相比,GPT-4o 非常适合实时、多模式对话。对于深度和细节至关重要的多方面、特定领域的调查,深度研究进行广泛探索并引用每项主张的能力是快速摘要与可用作工作产品的有据可查、经过验证的答案之间的区别。

工作原理
深度研究使用端到端强化学习在一系列领域的硬浏览和推理任务上进行训练。通过这种训练,它学会了规划和执行多步骤轨迹以找到所需的数据,并在必要时回溯并对实时信息做出反应。该模型还能够浏览用户上传的文件,使用 Python 工具绘制和迭代图表,在其响应中嵌入生成的图表和网站图像,并引用其来源中的特定句子或段落。经过这种训练,它在一系列针对现实问题的公开评估中创下了新高。
性能如何
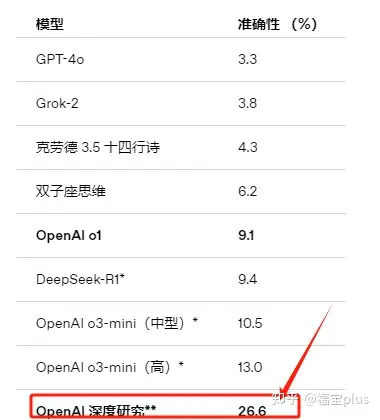
专家级任务的通过率(按估计经济价值计算)
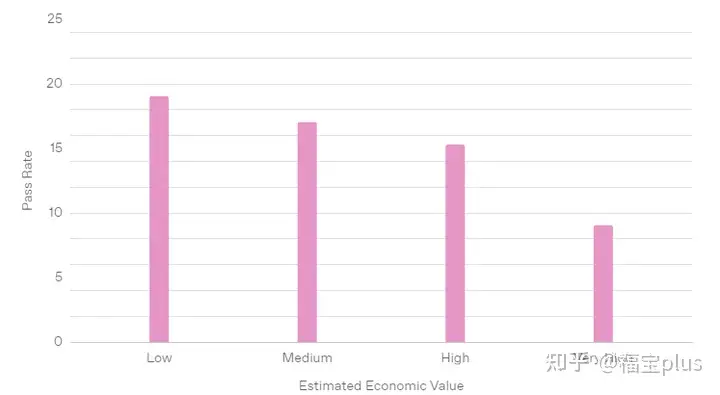
专家级任务的预计小时数通过率
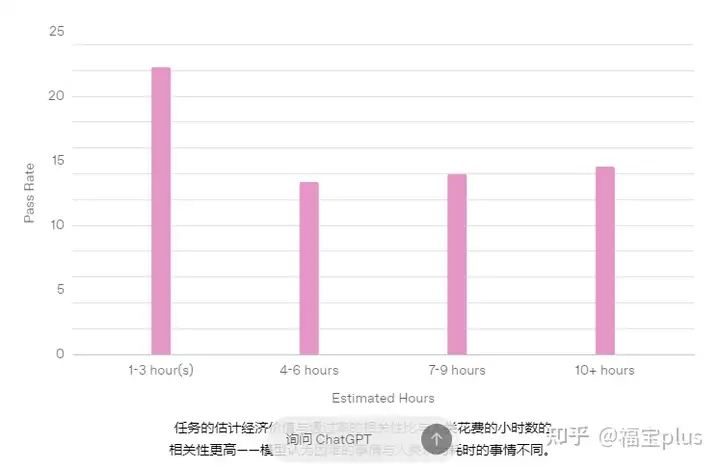
实际表现
咱们就以医学研究为例,看看4o和deep research表现如何:
Q:深入研究通过直接修改四个 Yamanaka 因子的蛋白质序列来提高 OSKM 重编程效率的尝试。列出您找到的所有相关论文、作者、使用的方法和结果。研究论文中蛋白质变化的模式和相应的结果,并列出科学家为提高效率而修改的前 3 个域,以及他们认为这些变化有效的原因。
4o的回答如下:
"人们已探索直接修改山中伸弥因子(Oct4、Sox2、Klf4 和 c-Myc,统称为 OSKM)的蛋白质序列,以提高体细胞重编程为诱导性多能干细胞 (iPSC) 的效率。以下是相关研究的摘要,包括作者、方法和主要发现:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









