




几天前,OpenAI在 API 中推出了三个新模型:GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano。这些模型的性能全面超越 GPT-4o 和 GPT-4o mini(感觉这个GPT-4.1就是GPT-4o的升级迭代版本),主要在编码和指令跟踪方面均有显著提升。还拥有更大的上下文窗口——支持多达 100 万个上下文标记——并且能够通过改进的长上下文理解更好地利用这些上下文。
知识截止日期已更新至 2024 年 6 月,而对于plus、Pro、Team用户可以在模型的更多选择器中使用GPT-4.1,如下图所示
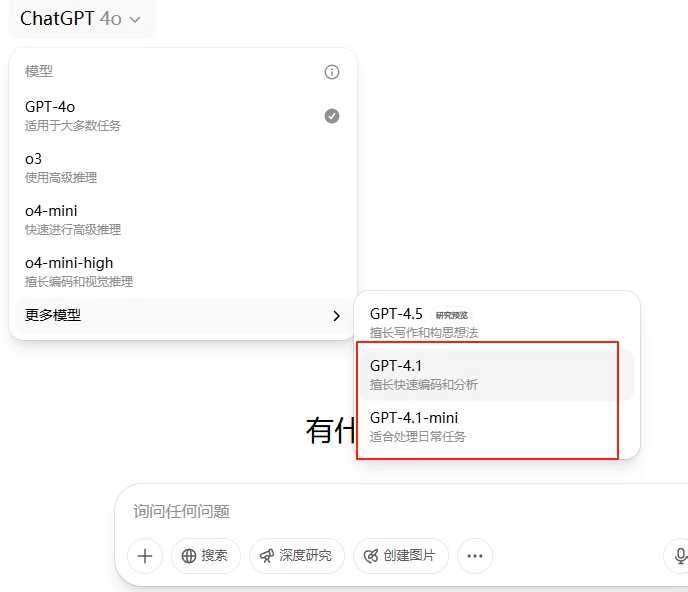
GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano更新了哪些特点
接下来我们一起来看看GPT-4.1的编码、绘画、上下文能力到底如何,值不值得试试呢? 先看看官方的基准测试数据,然后再来实现一个小应用吧,最后告诉大家如何才能使用升级到CahtGPTplus/Pro会员去试试GPT-4.1
-
编码:GPT-4.1 在SWE-bench Verified上的得分为 54.6%,比 GPT-4o 提高了 21.4%,比 GPT-4.5 提高了 26.6% ,使其成为领先的编码模型。
-
说明如下: 在Scale 的MultiChallenge基准,即衡量指令遵循能力的标准,GPT-4.1 得分为 38.3%,比 GPT-4o 提高了10.5 % 。
-
详细背景:关于视频MME作为多模态长上下文理解的基准,GPT-4.1 创造了新的最先进成果——在长篇无字幕类别中得分为 72.0%,比 GPT-4o 提高了6.7 % 。
GPT-4.1 VS GPT-4o模型系列以更低的成本提供了更好的性能。这些模型在延迟曲线的每个点上都实现了性能的提升。
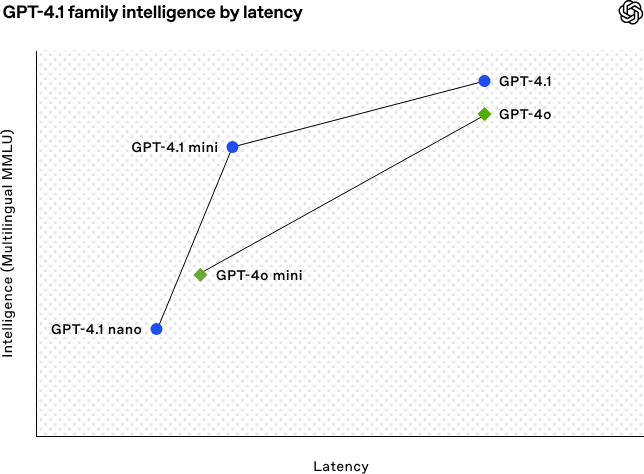
GPT-4.1 mini 在小模型性能上实现了显著飞跃,甚至在多项基准测试中超越了 GPT-4o。它在智能评估方面达到甚至超越了 GPT-4o,同时将延迟降低了近一半,成本降低了 83%。
而对于需要低延迟的任务,GPT-4.1 nano 是目前速度最快、成本最低的模型。它拥有 100 万个 token 上下文窗口,在小规模下实现了卓越的性能,在 MMLU 测试中得分高达 80.1%,在 GPQA 测试中得分高达 50.3%,在 Aider 多语言编码测试中得分高达 9.8%,甚至高于 GPT-4o mini。它是分类或自动完成等任务的理想选择。 这些在指令遵循可靠性和长上下文理解方面的改进,也使得 GPT-4.1 模型在驱动代理(即能够代表用户独立完成任务的系统)方面更加有效。当与 Responses API 等原语结合使用时,开发人员现在可以构建在实际软件工程中更有用、更可靠的代理,从大型文档中提取见解,以最少的手动操作解决客户请求以及其他复杂任务。 在此之前GPT-4.1 仅通过 API 提供。在 ChatGPT 中,指令遵循、编码和智能方面的许多改进已逐步融入最新版的GPT-4o,OpenAI将在未来的版本中继续融入更多内容。
下面,将分析 GPT-4.1 在多个基准测试中的表现,并结合 Windsurf、Qodo、Hex、Blue J、Thomson Reuters 和 Carlyle 等 alpha 测试人员的示例,展示其在特定领域任务的生产中的表现。
特点一:编码能力提升
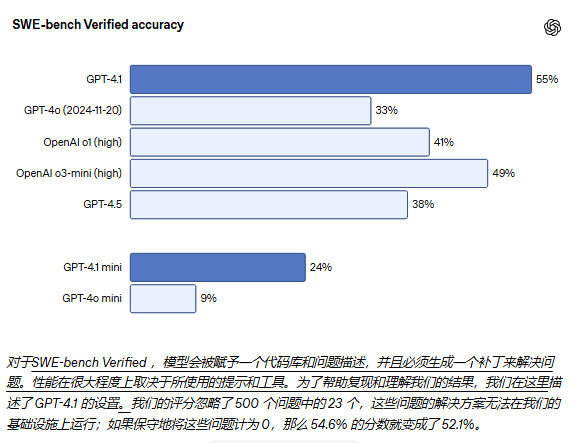
GPT-4.1 在各种编码任务上都比 GPT-4o 表现得更好,包括代理解决编码任务、前端编码、减少无关编辑、可靠地遵循差异格式、确保一致的工具使用等等。 在衡量真实世界软件工程技能的 SWE-bench Verified 测试中,GPT-4.1 完成了 54.6% 的任务,而 GPT-4o(2024-11-20)的完成率为 33.2%。这反映了模型在探索代码库、完成任务以及生成可运行并通过测试的代码方面的能力有所提升。
在SWE‑bench Verified accuracy正确性对比
对比模型有GPT-4.1、GPT-4o (2024-11-20)、OpenAI o1 (high)、OpenAI o3-mini (high)、GPT-4.5、GPT-4.1 mini、GPT-4o mini
特点二:多编程语言支持
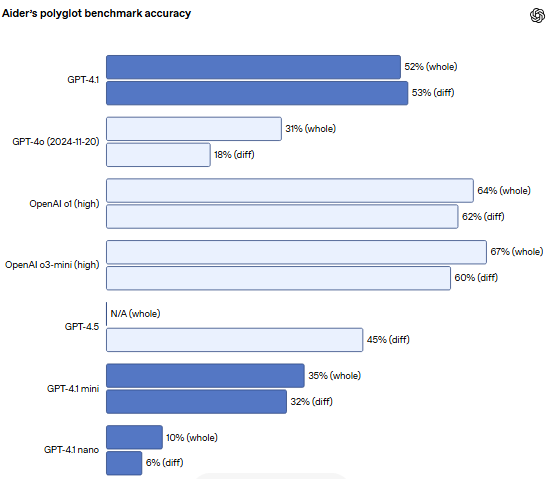
对于需要编辑大型文件的 API 开发者来说,GPT-4.1 在跨多种格式的代码差异分析方面更加可靠。在Aider 的多语言差异基准测试中,GPT-4.1 的得分是 GPT-4o 的两倍多。甚至比 GPT-4.5 还高出 8% 。这项评估既衡量了跨各种编程语言的编码能力,也衡量了模型在整体和差异格式下生成更改的能力。OpenAI还专门训练了 GPT-4.1,使其能够更可靠地遵循差异格式,这使得开发人员只需让模型输出更改的行,而无需重写整个文件,从而节省成本和延迟。为了获得最佳的代码差异性能,请参阅 prompting-gpt-4-1-models
提示指南,对于喜欢重写整个文件的开发者,OpenAI将 GPT-4.1 的输出令牌限制增加到 32,768 个令牌(GPT-4o 为 16,384 个令牌)。并建议使用预测输出减少完整文件重写的延迟。 在 Aider 的多语言基准测试中,模型解决了来自Exercism的编码练习通过编辑源文件,允许重试一次。“whole”格式要求模型重写整个文件,这可能很慢且成本高昂。“diff”格式要求模型编写一系列搜索/替换块。
GPT-4.1 在前端编码方面也比 GPT-4o 有了显著提升,能够创建功能更强大、更美观的 Web 应用。在我们的面对面对比中,付费人工评分员 80% 的评分结果显示,GPT-4.1 的网站比 GPT-4o 的网站更受欢迎。
特点三:长上下文(最多可以处理100W个上下文标记)
GPT-4.1、GPT-4.1 mini 和 GPT-4.1 nano 最多可以处理 100 万个上下文标记,而之前的 GPT-4o 型号最多可以处理 128,000 个。100 万个标记相当于整个 React 代码库的 8 个以上副本,因此长上下文非常适合处理大型代码库或大量长文档。 OpenAI训练了 GPT-4.1,使其能够可靠地处理长达 100 万个上下文中的信息。此外,我们还训练它比 GPT-4o 更加可靠地识别相关文本,并忽略长短上下文中的干扰项。长上下文理解是法律、编码、客户支持以及许多其他领域应用的关键能力。
特点四:图像视觉
GPT-4.1 系列在图像理解方面非常强大,尤其是 GPT-4.1 mini 实现了重大的飞跃,在图像基准测试中经常击败 GPT-4o。
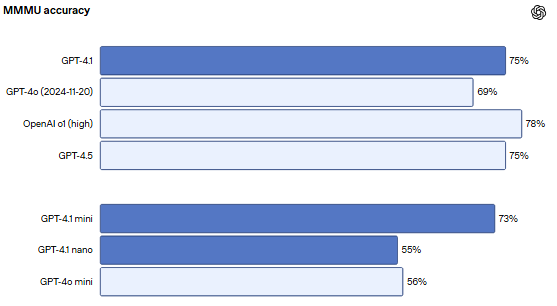
在 MMMU中,模型回答包含图表、图解、地图等的问题。(注意:即使不包含图像,许多答案仍然可以从上下文中推断或猜测。)
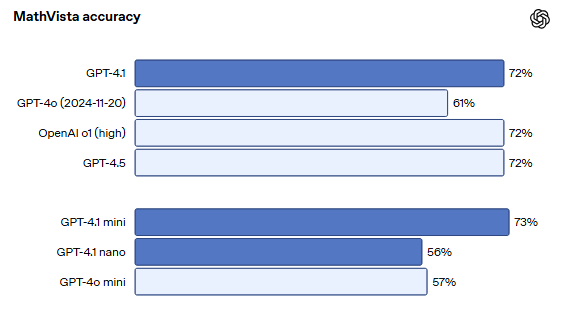
在MathVista中,一个模型解决了视觉数学任务。
看长视频内容然后回答问题正确性对比

在 Video-MME
视频-MME中,一个模型根据 30-60 分钟长的无字幕视频回答多项选择题。
如何订阅升级ChatGPTplus?如何使用GPT-4.1
目前所有的chatgptPlus用户已经被推送 了GPT-4.1模型(在更多模型里面就可以使用),对于普通用户,现在也可以使用GPT-4.1
GPT-4.1使用次数限制
免费用户每24小时最多使用5次GPT-4.1,超出后自动切换其它模型;Plus用户每3小时最多使用80次
如何升级ChatGPTplus?
plus用户升级可以参考本教程:https://littlemagic8.github.io/2024/09/04/update-ChatGPT-Plus/ (笔者已经使用了一年多了,保证可行)
GPT-4.1 实例展示
我们使用镜像站(chatshare)来演示一番,目前镜像站GPT-4.1已经被推送了
PS: 想要体验共享原生镜像站的童鞋可以参考本文: https://littlemagic8.github.io/2025/04/10/how-use-share-AI-model/
实例一:AI 驱动的社交媒体分析工具
提示词:使用 Python 开发一个社交媒体分析工具,分析指定 X 用户(如 @elonmusk)最近 100 条帖子的情绪和关键词。
要求: 1. 通过 X API 获取帖子(假设 API 密钥为 'X_API_KEY')。
2. 使用 NLTK 进行情绪分析,分类为积极、消极、中性。
3. 提取前 10 个高频关键词(去除停用词)。
4. 生成柱状图(使用 Matplotlib)显示情绪分布,保存为 'sentiment_analysis.png'。
5. 输出结果为 JSON 文件 'user_analysis.json',包含情绪分布和关键词。 确保代码有错误处理、日志记录和详细注释,适合生产环境。
import os
import sys
import json
import logging
import requests
from collections import Counter
from typing import List, Dict
import nltk
from nltk.sentiment import SentimentIntensityAnalyzer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import matplotlib.pyplot as plt
# === 初始化 NLTK 资源 ===
try:
nltk.data.find('tokenizers/punkt')
except LookupError:
nltk.download('punkt')
try:
nltk.data.find('corpora/stopwords')
except LookupError:
nltk.download('stopwords')
try:
nltk.data.find('sentiment/vader_lexicon')
except LookupError:
nltk.download('vader_lexicon')
# === 日志配置 ===
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s %(levelname)s %(message)s',
handlers=[
logging.StreamHandler(sys.stdout), # 输出到控制台
logging.FileHandler("social_media_analysis.log", encoding='utf-8')
]
)
logger = logging.getLogger(__name__)
class SocialMediaAnalyzer:
def __init__(self, api_key: str):
self.api_key = api_key
self.base_url = "https://api.twitter.com/2" # 假设 X API 为 Twitter v2 类似结构
self.headers = {
"Authorization": f"Bearer {self.api_key}"
}
self.sia = SentimentIntensityAnalyzer()
self.stop_words = set(stopwords.words('english'))
def fetch_tweets(self, username: str, max_results: int = 100) -> List[str]:
"""
通过 X API 获取用户近 100 条推文文本内容
:param username: str, 用户名 (如 '@elonmusk' 可自动去除 '@')
:param max_results: int, 最多获取的推文数量(最多 100 条)
:return: List[str], 文本列表
"""
username = username.lstrip('@')
logger.info(f"开始获取用户 @{username} 的最近 {max_results} 条帖子")
try:
# Step1: 获取用户ID
user_resp = requests.get(
f"{self.base_url}/users/by/username/{username}",
headers=self.headers,
timeout=10
)
user_resp.raise_for_status()
user_id = user_resp.json()['data']['id']
logger.debug(f"获取到用户ID: {user_id}")
# Step2: 获取用户推文
# max_results 最大为100,分页可改进,此处单调用就够
params = {
"max_results": max_results,
"tweet.fields": "text", # 只要文本字段
"exclude": "retweets,replies" # 排除转推和回复短内容(如需)
}
tweets_ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









