




Quantstats是非常著名的量化策略评估与可视化库。从2024年底起约8个月里,它没有得到积极的维护,出现了在Python 3.12以上,完全无法运行等严重bug。
好消息是,最近一周,原作者 Ran Aroussi 已经恢复了对这个库的维护,并且连发了5个版本(从0.0.64到0.0.68)。
我们在课程中一直推荐大家使用这个库来进行策略的评估与可视化,以避免重复造轮子。这种推荐,也使得我们有义务去维护它。于是,我们在7月初发布了quantstats-reloaded。
为避免再次失联,我们仍将继续维护quantstats-reloaded一段时间,以便我们的学员始终能有可用的quantstats。另外,我们也将对这个库进行一些重要的改进,首先是进行单元测试增强。
原库缺乏系统的单元测试和CI,这可能是导致原作者无法及时修复bug的主要原因。
这也让我们作为使用者,不免有些担心。所以,在重启维护之后,我们先借由AI,加上了完整的单元测试与CI流程。然后,我们刚刚手工补齐了最重要的stats模块的全部单元测试,测试结果与原库完全一致(但不一定正确!),并达到了91%的单元测试覆盖率。
以下是我们的对照测试方法。
首先,我们使用以下方法,在安装 Quantstats的环境下,对stats模块的运行结果进行录制:
def record(dst: str):
import pickle
dates = pd.date_range(start='2020-01-01', end='2020-12-31', freq='B')
np.random.seed(42)
returns = pd.Series(np.random.normal(0.001, 0.02, len(dates)), index=dates)
np.random.seed(43)
benchmark_returns = pd.Series(np.random.normal(0.0005, 0.015, len(dates)), index=dates)
# the following requires returns only
unary_ops = ['adjusted_sortino', 'autocorr_penalty', 'avg_loss', 'avg_return', 'avg_win', 'best', 'cagr', 'calmar', 'common_sense_ratio', 'comp', 'compsum', 'conditional_value_at_risk', 'consecutive_losses', 'consecutive_wins', 'cpc_index', 'cvar', 'distribution', 'drawdown_details', 'expected_return', 'expected_shortfall', 'exposure', 'gain_to_pain_ratio', 'geometric_mean', 'ghpr', 'implied_volatility', 'kelly_criterion', 'kurtosis', 'max_drawdown', 'monthly_returns', 'omega', 'outlier_loss_ratio', 'outlier_win_ratio', 'outliers', 'payoff_ratio', 'pct_rank', 'probabilistic_adjusted_sortino_ratio', 'probabilistic_ratio', 'probabilistic_sharpe_ratio', 'probabilistic_sortino_ratio', 'profit_factor', 'profit_ratio', 'rar', 'recovery_factor', 'remove_outliers', 'risk_of_ruin', 'risk_return_ratio', 'rolling_sharpe', 'rolling_sortino', 'rolling_volatility', 'ror', 'serenity_index', 'sharpe', 'skew', 'smart_sharpe', 'smart_sortino', 'sortino', 'tail_ratio', 'to_drawdown_series', 'ulcer_index', 'ulcer_performance_index', 'upi', 'validate_input', 'value_at_risk', 'var', 'volatility', 'win_loss_ratio', 'win_rate', 'worst']
# the following requires benchmark also
binary_ops = [
"compare",
"greeks",
"information_ratio",
"r2",
"r_squared",
"treynor_ratio"
]
# need speical handling, or not a stats
excluded = ["rolling_greeks", "safe_concat"]
results = {}
for name in dir(qs.stats):
if name[0] == '_':
continue
func = getattr(qs.stats, name)
if name in unary_ops:
results[name] = func(returns)
elif name in binary_ops:
results[name] = func(returns, benchmark_returns)
else:
print("no handled", name)
data= {
"returns": returns,
"benchmark": benchmark_returns,
"results": results,
"unary_ops": unary_ops
}
with open(dst, "wb") as f:
pickle.dump(data, f)
然后,我们在 Quantstats-reloaded 所在的虚拟环境下,对录制的结果进行验证:
def test_recorded():
returns, benchmark, expected, unary_ops = replay()
for name in expected.keys():
try:
func = getattr(qs.stats, name)
if name in unary_ops:
ret = func(returns)
expected_ret = expected.get(name)
msg = f"{name}结果不一致,期望{expected_ret},实际{ret}"
assert is_equal(ret, expected_ret), msg
else:
ret = func(returns, benchmark)
expected_ret = expected.get(name, None)
msg = f"{name}结果不一致,期望{expected_ret},实际{ret}"
assert is_equal(ret, expected_ret), msg
except Exception as e:
print(name, e)
最后,通过pytest测试,保证了核心指标计算模块测试覆盖率达到91%:
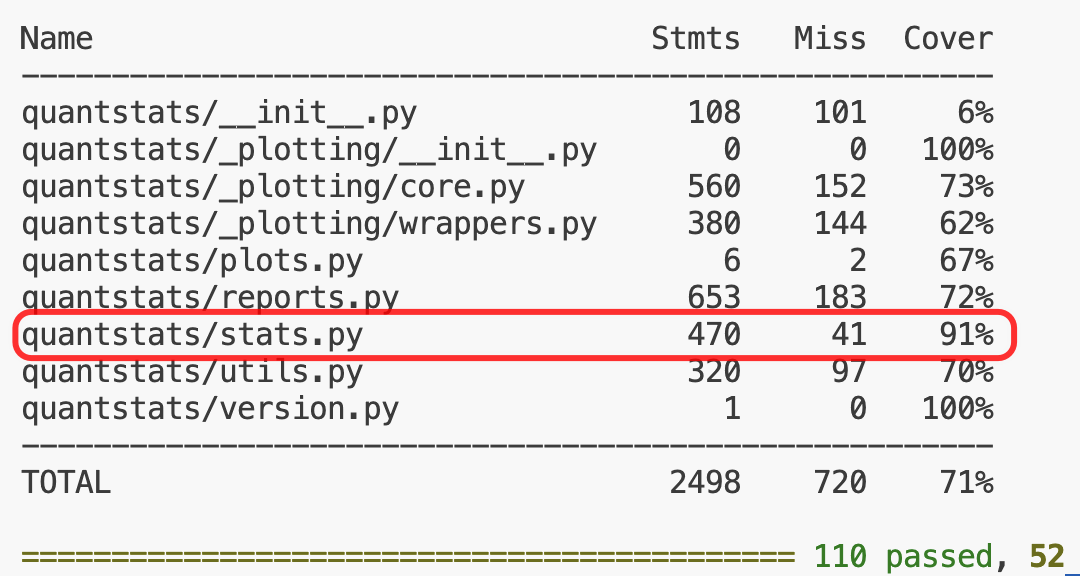
当然,这只是保证了quantstats-reloaded的结果与原quantstats一致,并不能保证这些指标计算都是正确的。不过我们会继续维护和增强单元测试,以确保最终每一项指标计算都是正确的。



















 966
966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











